 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep CLAS: Deep Contextual Listen, Attend and Spell
Sep 26, 2024



Contextual-LAS (CLAS) has been shown effective in improving Automatic Speech Recognition (ASR) of rare words. It relies on phrase-level contextual modeling and attention-based relevance scoring without explicit contextual constraint which lead to insufficient use of contextual information. In this work, we propose deep CLAS to use contextual information better. We introduce bias loss forcing model to focus on contextual information. The query of bias attention is also enriched to improve the accuracy of the bias attention score. To get fine-grained contextual information, we replace phrase-level encoding with character-level encoding and encode contextual information with conformer rather than LSTM. Moreover, we directly use the bias attention score to correct the output probability distribution of the model. Experiments using the public AISHELL-1 and AISHELL-NER. On AISHELL-1, compared to CLAS baselines, deep CLAS obtains a 65.78% relative recall and a 53.49% relative F1-score increase in the named entity recognition scene.
The USTC-NERCSLIP Systems for the CHiME-8 NOTSOFAR-1 Challenge
Sep 03, 2024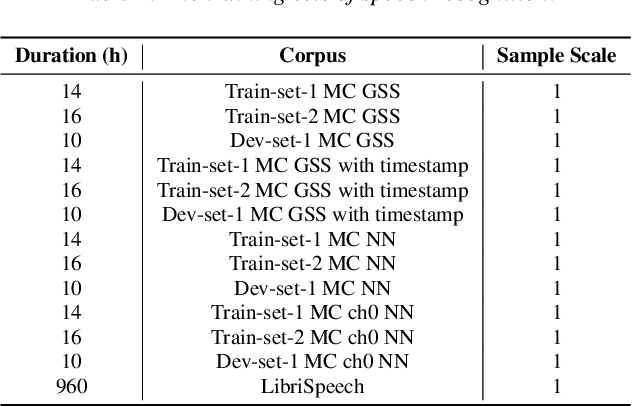
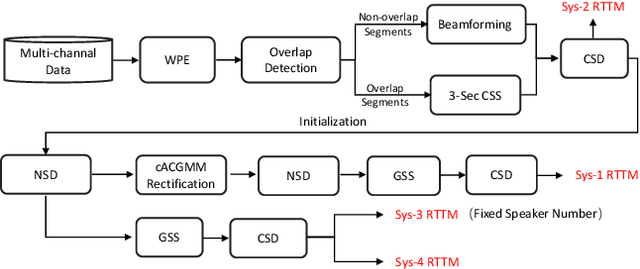
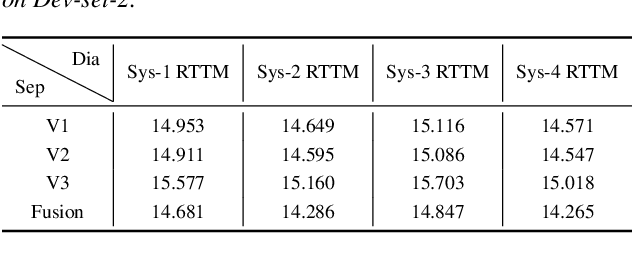
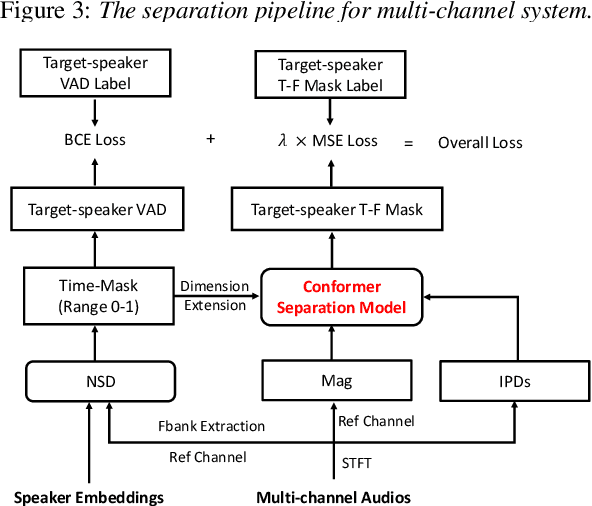
This technical report outlines our submission system for the CHiME-8 NOTSOFAR-1 Challenge. The primary difficulty of this challenge is the dataset recorded across various conference rooms, which captures real-world complexities such as high overlap rates, background noises, a variable number of speakers, and natural conversation styles. To address these issues, we optimized the system in several aspects: For front-end speech signal processing, we introduced a data-driven joint training method for diarization and separation (JDS) to enhance audio quality. Additionally, we also integrated traditional guided source separation (GSS) for multi-channel track to provide complementary information for the JDS. For back-end speech recognition, we enhanced Whisper with WavLM, ConvNeXt, and Transformer innovations, applying multi-task training and Noise KLD augmentation, to significantly advance ASR robustness and accuracy. Our system attained a Time-Constrained minimum Permutation Word Error Rate (tcpWER) of 14.265% and 22.989% on the CHiME-8 NOTSOFAR-1 Dev-set-2 multi-channel and single-channel tracks, respectively.
The USTC-NERCSLIP Systems for the CHiME-7 DASR Challenge
Aug 28, 2023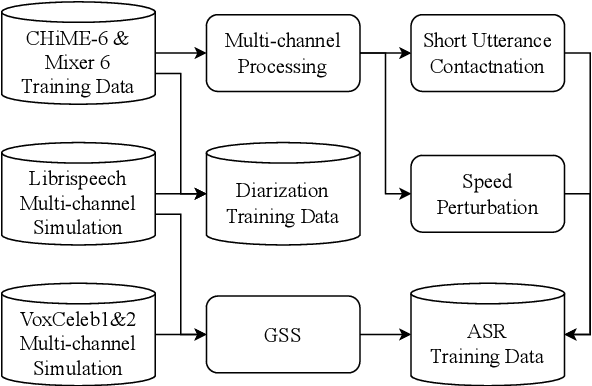
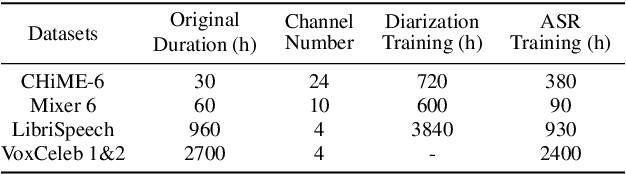
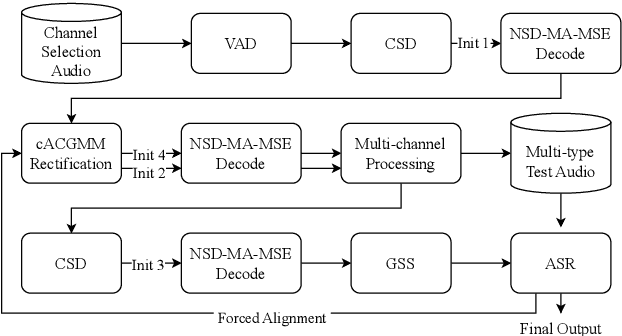
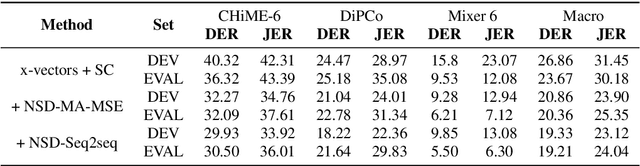
This technical report details our submission system to the CHiME-7 DASR Challenge, which focuses on speaker diarization and speech recognition under complex multi-speaker settings. Additionally, it also evaluates the efficiency of systems in handling diverse array devices. To address these issues, we implemented an end-to-end speaker diarization system and introduced a rectification strategy based on multi-channel spatial information. This approach significantly diminished the word error rates (WER). In terms of recognition, we utilized publicly available pre-trained models as the foundational models to train our end-to-end speech recognition models. Our system attained a macro-averaged diarization-attributed WER (DA-WER) of 22.4\% on the CHiME-7 development set, which signifies a relative improvement of 52.5\% over the official baseline system.