 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Speech Recognition with Decoder-Only Large Language Models and Latency Optimization
Jan 30, 2026Recent advances have demonstrated the potential of decoderonly large language models (LLMs) for automatic speech recognition (ASR). However, enabling streaming recognition within this framework remains a challenge. In this work, we propose a novel streaming ASR approach that integrates a read/write policy network with monotonic chunkwise attention (MoChA) to dynamically segment speech embeddings. These segments are interleaved with label sequences during training, enabling seamless integration with the LLM. During inference, the audio stream is buffered until the MoChA module triggers a read signal, at which point the buffered segment together with the previous token is fed into the LLM for the next token prediction. We also introduce a minimal-latency training objective to guide the policy network toward accurate segmentation boundaries. Furthermore, we adopt a joint training strategy in which a non-streaming LLM-ASR model and our streaming model share parameters. Experiments on the AISHELL-1 and AISHELL-2 Mandarin benchmarks demonstrate that our method consistently outperforms recent streaming ASR baselines, achieving character error rates of 5.1% and 5.5%, respectively. The latency optimization results in a 62.5% reduction in average token generation delay with negligible impact on recognition accuracy
Adapting Speech Foundation Models with Large Language Models for Unified Speech Recognition
Oct 27, 2025Unified speech recognition aims to perform auditory, visual, and audiovisual speech recognition within a single model framework. While speech foundation models (SFMs) have demonstrated remarkable performance in auditory tasks, their adaptation to multimodal scenarios remains underexplored. This paper presents UASR-LLM, a novel framework that adapts frozen SFMs to unified VSR, ASR, and AVSR tasks by leveraging large language models (LLMs) as text decoders. Our approach introduces visual representations into multiple SFM layers through visual injection modules, enabling multimodal input processing and unified hidden representations. The augmented SFMs connect with decoder-only LLMs via a feed-forward adaptor, where concatenated representations and instruction prompts guide speech transcription. We implement a twostage training strategy: visual injection pretraining followed by speech recognition finetuning. SFM parameters remain frozen throughout training, with only visual injection modules optimized initially, and LLMs finetuned using LoRA parameters subsequently. Experimental results demonstrate superior performance over state-of-the-art baselines across VSR, ASR, and AVSR tasks under both clean and noisy conditions. Ablation studies confirm generalization across various SFMs and LLMs, validating the proposed training strategy.
Audio-Visual Representation Learning via Knowledge Distillation from Speech Foundation Models
Feb 09, 2025



Audio-visual representation learning is crucial for advancing multimodal speech processing tasks, such as lipreading and audio-visual speech recognition. Recently, speech foundation models (SFMs) have shown remarkable generalization capabilities across various speech-related tasks. Building on this progress, we propose an audio-visual representation learning model that leverages cross-modal knowledge distillation from SFMs. In our method, SFMs serve as teachers, from which multi-layer hidden representations are extracted using clean audio inputs. We also introduce a multi-teacher ensemble method to distill the student, which receives audio-visual data as inputs. A novel representational knowledge distillation loss is employed to train the student during pretraining, which is also applied during finetuning to further enhance the performance on downstream tasks. Our experiments utilized both a self-supervised SFM, WavLM, and a supervised SFM, iFLYTEK-speech. The results demonstrated that our proposed method achieved superior or at least comparable performance to previous state-of-the-art baselines across automatic speech recognition, visual speech recognition, and audio-visual speech recognition tasks. Additionally, comprehensive ablation studies and the visualization of learned representations were conducted to evaluate the effectiveness of our proposed method.
Target Speaker Lipreading by Audio-Visual Self-Distillation Pretraining and Speaker Adaptation
Feb 09, 2025



Lipreading is an important technique for facilitating human-computer interaction in noisy environments. Our previously developed self-supervised learning method, AV2vec, which leverages multimodal self-distillation, has demonstrated promising performance in speaker-independent lipreading on the English LRS3 dataset. However, AV2vec faces challenges such as high training costs and a potential scarcity of audio-visual data for lipreading in languages other than English, such as Chinese. Additionally, most studies concentrate on speakerindependent lipreading models, which struggle to account for the substantial variation in speaking styles across di?erent speakers. To address these issues, we propose a comprehensive approach. First, we investigate cross-lingual transfer learning, adapting a pre-trained AV2vec model from a source language and optimizing it for the lipreading task in a target language. Second, we enhance the accuracy of lipreading for specific target speakers through a speaker adaptation strategy, which is not extensively explored in previous research. Third, after analyzing the complementary performance of lipreading with lip region-of-interest (ROI) and face inputs, we introduce a model ensembling strategy that integrates both, signi?cantly boosting model performance. Our method achieved a character error rate (CER) of 77.3% on the evaluation set of the ChatCLR dataset, which is lower than the top result from the 2024 Chat-scenario Chinese Lipreading Challenge.
Self-Supervised Audio-Visual Speech Representations Learning By Multimodal Self-Distillation
Dec 06, 2022



In this work, we present a novel method, named AV2vec, for learning audio-visual speech representations by multimodal self-distillation. AV2vec has a student and a teacher module, in which the student performs a masked latent feature regression task using the multimodal target features generated online by the teacher. The parameters of the teacher model are a momentum update of the student. Since our target features are generated online, AV2vec needs no iteration step like AV-HuBERT and the total training time cost is reduced to less than one-fifth. We further propose AV2vec-MLM in this study, which augments AV2vec with a masked language model (MLM)-style loss using multitask learning. Our experimental results show that AV2vec achieved comparable performance to the AV-HuBERT baseline. When combined with an MLM-style loss, AV2vec-MLM outperformed baselines and achieved the best performance on the downstream tasks.
Is Lip Region-of-Interest Sufficient for Lipreading?
Jun 02, 2022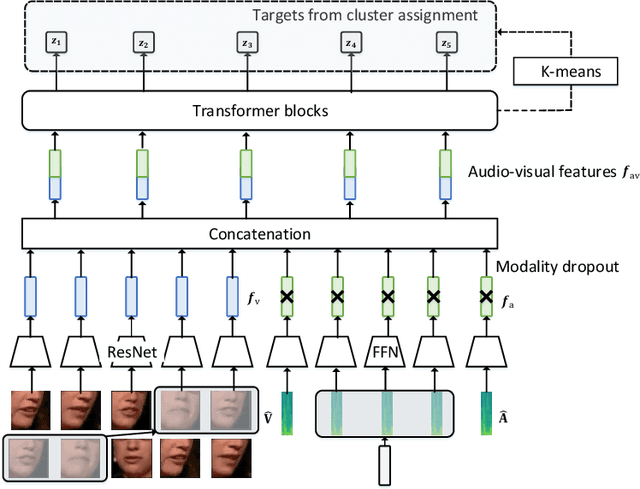
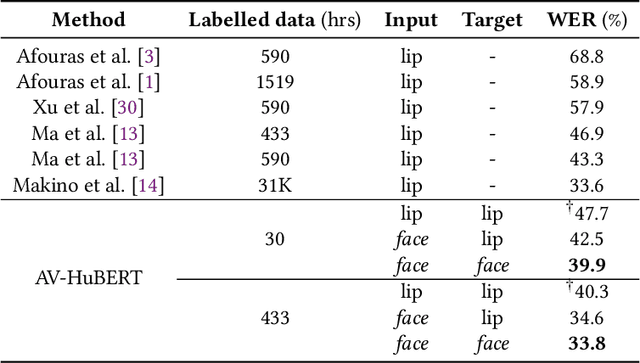

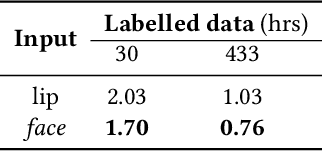
Lip region-of-interest (ROI) is conventionally used for visual input in the lipreading task. Few works have adopted the entire face as visual input because lip-excluded parts of the face are usually considered to be redundant and irrelevant to visual speech recognition. However, faces contain much more detailed information than lips, such as speakers' head pose, emotion, identity etc. We argue that such information might benefit visual speech recognition if a powerful feature extractor employing the entire face is trained. In this work, we propose to adopt the entire face for lipreading with self-supervised learning. AV-HuBERT, an audio-visual multi-modal self-supervised learning framework, was adopted in our experiments. Our experimental results showed that adopting the entire face achieved 16% relative word error rate (WER) reduction on the lipreading task, compared with the baseline method using lip as visual input. Without self-supervised pretraining, the model with face input achieved a higher WER than that using lip input in the case of limited training data (30 hours), while a slightly lower WER when using large amount of training data (433 hours).
TaL: a synchronised multi-speaker corpus of ultrasound tongue imaging, audio, and lip videos
Nov 19, 2020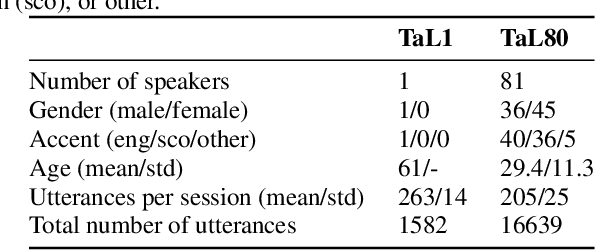
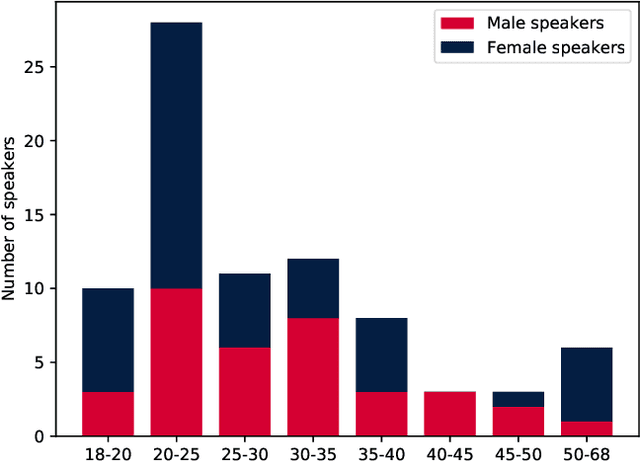
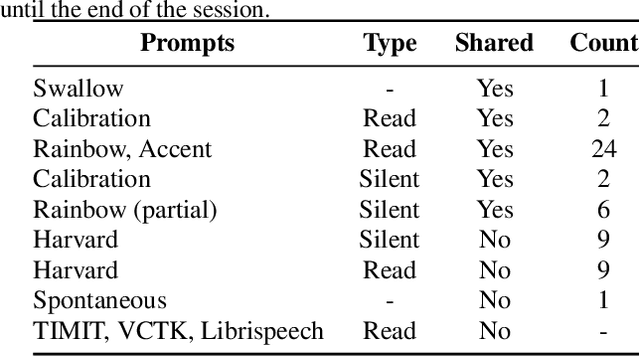

We present the Tongue and Lips corpus (TaL), a multi-speaker corpus of audio, ultrasound tongue imaging, and lip videos. TaL consists of two parts: TaL1 is a set of six recording sessions of one professional voice talent, a male native speaker of English; TaL80 is a set of recording sessions of 81 native speakers of English without voice talent experience. Overall, the corpus contains 24 hours of parallel ultrasound, video, and audio data, of which approximately 13.5 hours are speech. This paper describes the corpus and presents benchmark results for the tasks of speech recognition, speech synthesis (articulatory-to-acoustic mapping), and automatic synchronisation of ultrasound to audio. The TaL corpus is publicly available under the CC BY-NC 4.0 license.
Forward Attention in Sequence-to-sequence Acoustic Modelling for Speech Synthesis
Jul 18, 2018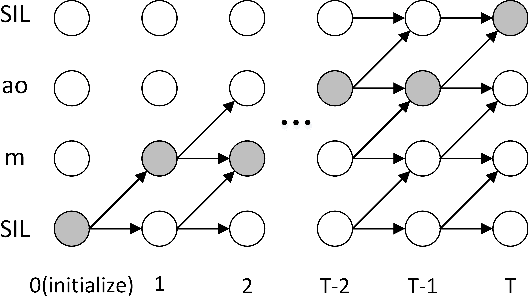
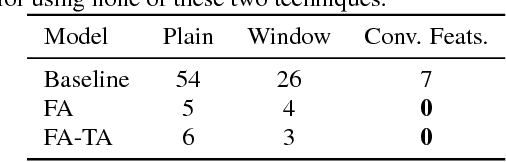
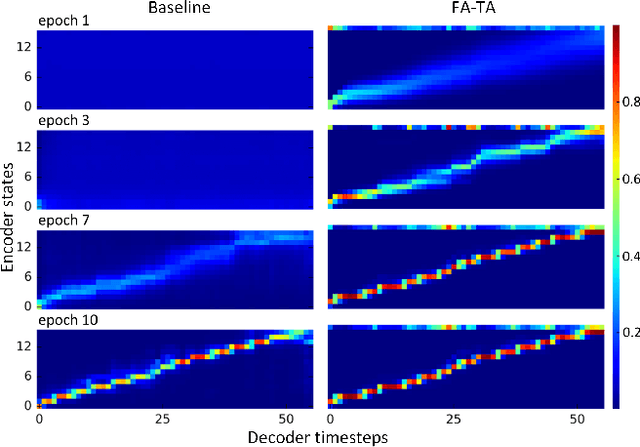

This paper proposes a forward attention method for the sequenceto- sequence acoustic modeling of speech synthesis. This method is motivated by the nature of the monotonic alignment from phone sequences to acoustic sequences. Only the alignment paths that satisfy the monotonic condition are taken into consideration at each decoder timestep. The modified attention probabilities at each timestep are computed recursively using a forward algorithm. A transition agent for forward attention is further proposed, which helps the attention mechanism to make decisions whether to move forward or stay at each decoder timestep. Experimental results show that the proposed forward attention method achieves faster convergence speed and higher stability than the baseline attention method. Besides, the method of forward attention with transition agent can also help improve the naturalness of synthetic speech and control the speed of synthetic speech effectively.
* 5 pages, 3 figures, 2 tables. Published in IEEE International Conference on Acoustics, Speech and Signal Processing 2018 (ICASSP2018)