 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget Speaker Lipreading by Audio-Visual Self-Distillation Pretraining and Speaker Adaptation
Feb 09, 2025



Lipreading is an important technique for facilitating human-computer interaction in noisy environments. Our previously developed self-supervised learning method, AV2vec, which leverages multimodal self-distillation, has demonstrated promising performance in speaker-independent lipreading on the English LRS3 dataset. However, AV2vec faces challenges such as high training costs and a potential scarcity of audio-visual data for lipreading in languages other than English, such as Chinese. Additionally, most studies concentrate on speakerindependent lipreading models, which struggle to account for the substantial variation in speaking styles across di?erent speakers. To address these issues, we propose a comprehensive approach. First, we investigate cross-lingual transfer learning, adapting a pre-trained AV2vec model from a source language and optimizing it for the lipreading task in a target language. Second, we enhance the accuracy of lipreading for specific target speakers through a speaker adaptation strategy, which is not extensively explored in previous research. Third, after analyzing the complementary performance of lipreading with lip region-of-interest (ROI) and face inputs, we introduce a model ensembling strategy that integrates both, signi?cantly boosting model performance. Our method achieved a character error rate (CER) of 77.3% on the evaluation set of the ChatCLR dataset, which is lower than the top result from the 2024 Chat-scenario Chinese Lipreading Challenge.
Approaches to Improving Recognition of Underrepresented Named Entities in Hybrid ASR Systems
May 18, 2020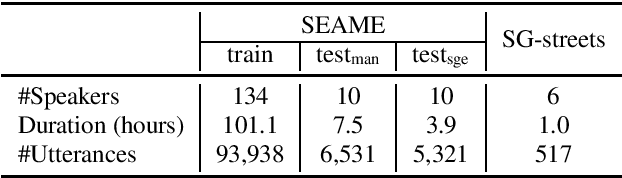

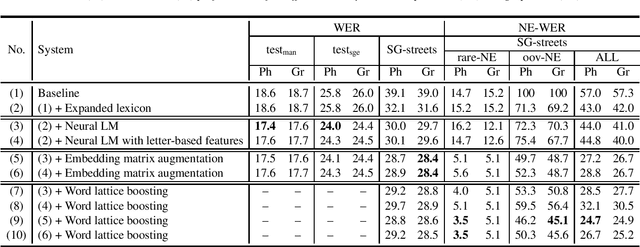
In this paper, we present a series of complementary approaches to improve the recognition of underrepresented named entities (NE) in hybrid ASR systems without compromising overall word error rate performance. The underrepresented words correspond to rare or out-of-vocabulary (OOV) words in the training data, and thereby can't be modeled reliably. We begin with graphemic lexicon which allows to drop the necessity of phonetic models in hybrid ASR. We study it under different settings and demonstrate its effectiveness in dealing with underrepresented NEs. Next, we study the impact of neural language model (LM) with letter-based features derived to handle infrequent words. After that, we attempt to enrich representations of underrepresented NEs in pretrained neural LM by borrowing the embedding representations of rich-represented words. This let us gain significant performance improvement on underrepresented NE recognition. Finally, we boost the likelihood scores of utterances containing NEs in the word lattices rescored by neural LMs and gain further performance improvement. The combination of the aforementioned approaches improves NE recognition by up to 42% relatively.