 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Online Learning on the Edge by Transforming Knowledge from Teacher Models
Dec 18, 2025Edge machine learning (Edge ML) enables training ML models using the vast data distributed across network edges. However, many existing approaches assume static models trained centrally and then deployed, making them ineffective against unseen data. To address this, Online Edge ML allows models to be trained directly on edge devices and updated continuously with new data. This paper explores a key challenge of Online Edge ML: "How to determine labels for truly future, unseen data points". We propose Knowledge Transformation (KT), a hybrid method combining Knowledge Distillation, Active Learning, and causal reasoning. In short, KT acts as the oracle in active learning by transforming knowledge from a teacher model to generate pseudo-labels for training a student model. To verify the validity of the method, we conducted simulation experiments with two setups: (1) using a less stable teacher model and (2) a relatively more stable teacher model. Results indicate that when a stable teacher model is given, the student model can eventually reach its expected maximum performance. KT is potentially beneficial for scenarios that meet the following circumstances: (1) when the teacher's task is generic, which means existing pre-trained models might be adequate for its task, so there will be no need to train the teacher model from scratch; and/or (2) when the label for the student's task is difficult or expensive to acquire.
Reducing the gap between streaming and non-streaming Transducer-based ASR by adaptive two-stage knowledge distillation
Jun 27, 2023Transducer is one of the mainstream frameworks for streaming speech recognition. There is a performance gap between the streaming and non-streaming transducer models due to limited context. To reduce this gap, an effective way is to ensure that their hidden and output distributions are consistent, which can be achieved by hierarchical knowledge distillation. However, it is difficult to ensure the distribution consistency simultaneously because the learning of the output distribution depends on the hidden one. In this paper, we propose an adaptive two-stage knowledge distillation method consisting of hidden layer learning and output layer learning. In the former stage, we learn hidden representation with full context by applying mean square error loss function. In the latter stage, we design a power transformation based adaptive smoothness method to learn stable output distribution. It achieved 19\% relative reduction in word error rate, and a faster response for the first token compared with the original streaming model in LibriSpeech corpus.
A Multi-Task Learning Framework for Overcoming the Catastrophic Forgetting in Automatic Speech Recognition
Apr 17, 2019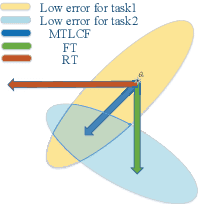
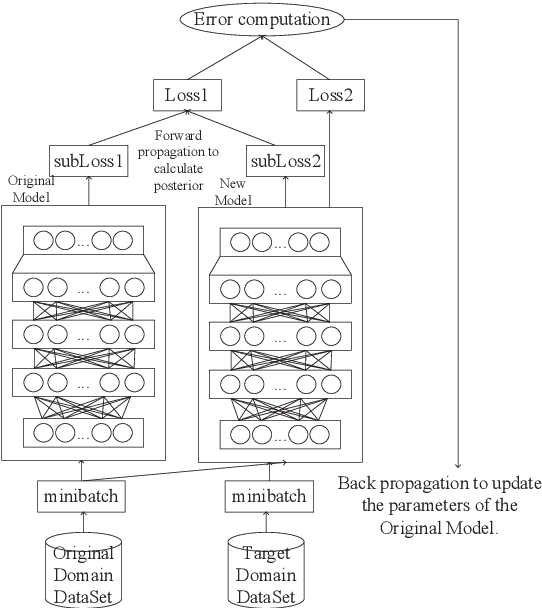
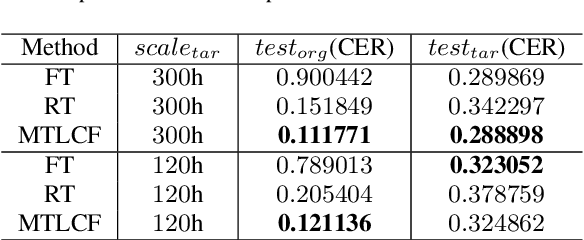
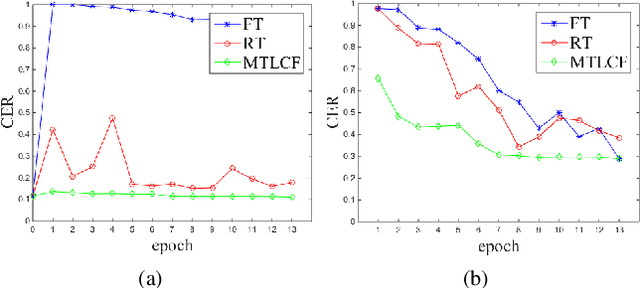
Recently, data-driven based Automatic Speech Recognition (ASR) systems have achieved state-of-the-art results. And transfer learning is often used when those existing systems are adapted to the target domain, e.g., fine-tuning, retraining. However, in the processes, the system parameters may well deviate too much from the previously learned parameters. Thus, it is difficult for the system training process to learn knowledge from target domains meanwhile not forgetting knowledge from the previous learning process, which is called as catastrophic forgetting (CF). In this paper, we attempt to solve the CF problem with the lifelong learning and propose a novel multi-task learning (MTL) training framework for ASR. It considers reserving original knowledge and learning new knowledge as two independent tasks, respectively. On the one hand, we constrain the new parameters not to deviate too far from the original parameters and punish the new system when forgetting original knowledge. On the other hand, we force the new system to solve new knowledge quickly. Then, a MTL mechanism is employed to get the balance between the two tasks. We applied our method to an End2End ASR task and obtained the best performance in both target and original datasets.
Hard Sample Mining for the Improved Retraining of Automatic Speech Recognition
Apr 17, 2019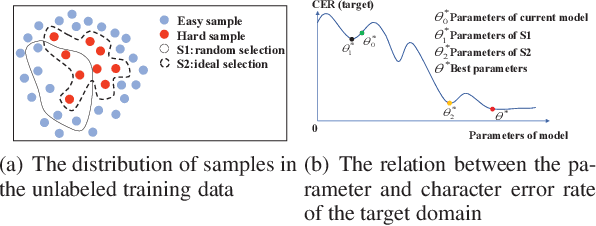
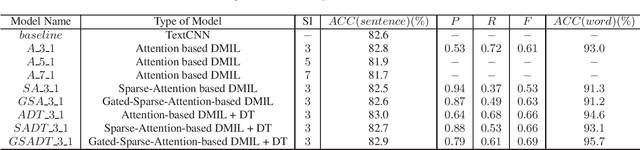
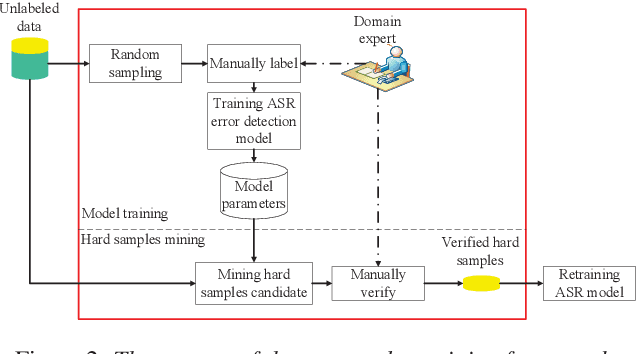

It is an effective way that improves the performance of the existing Automatic Speech Recognition (ASR) systems by retraining with more and more new training data in the target domain. Recently, Deep Neural Network (DNN) has become a successful model in the ASR field. In the training process of the DNN based methods, a back propagation of error between the transcription and the corresponding annotated text is used to update and optimize the parameters. Thus, the parameters are more influenced by the training samples with a big propagation error than the samples with a small one. In this paper, we define the samples with significant error as the hard samples and try to improve the performance of the ASR system by adding many of them. Unfortunately, the hard samples are sparse in the training data of the target domain, and manually label them is expensive. Therefore, we propose a hard samples mining method based on an enhanced deep multiple instance learning, which can find the hard samples from unlabeled training data by using a small subset of the dataset with manual labeling in the target domain. We applied our method to an End2End ASR task and obtained the best performance.