 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Loss Based Frame-wise Feature disentanglement for Polyphonic Sound Event Detection
Jan 11, 2024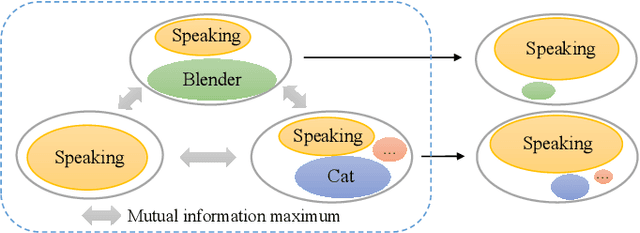
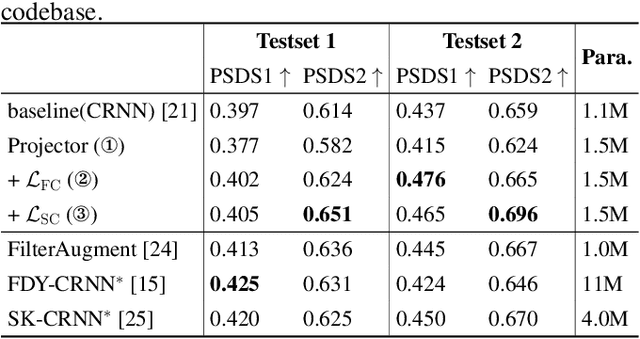
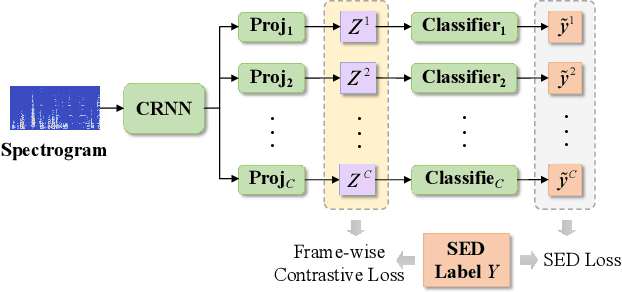
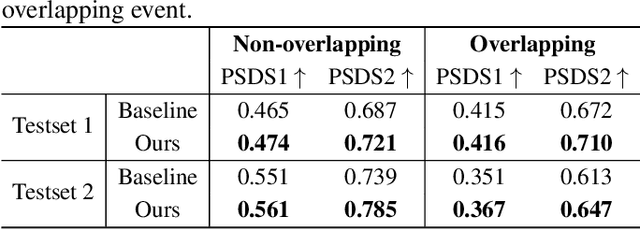
Overlapping sound events are ubiquitous in real-world environments, but existing end-to-end sound event detection (SED) methods still struggle to detect them effectively. A critical reason is that these methods represent overlapping events using shared and entangled frame-wise features, which degrades the feature discrimination. To solve the problem, we propose a disentangled feature learning framework to learn a category-specific representation. Specifically, we employ different projectors to learn the frame-wise features for each category. To ensure that these feature does not contain information of other categories, we maximize the common information between frame-wise features within the same category and propose a frame-wise contrastive loss. In addition, considering that the labeled data used by the proposed method is limited, we propose a semi-supervised frame-wise contrastive loss that can leverage large amounts of unlabeled data to achieve feature disentanglement. The experimental results demonstrate the effectiveness of our method.
Time-weighted Frequency Domain Audio Representation with GMM Estimator for Anomalous Sound Detection
May 05, 2023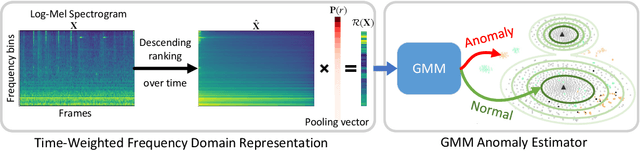
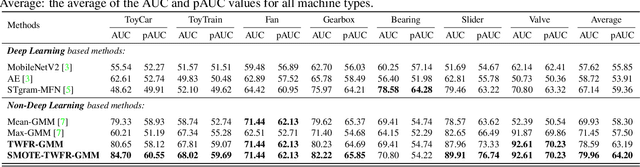
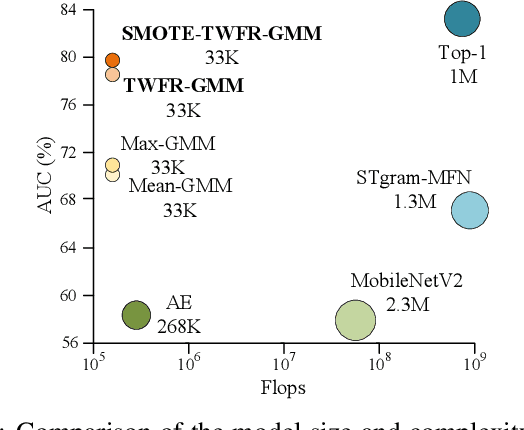
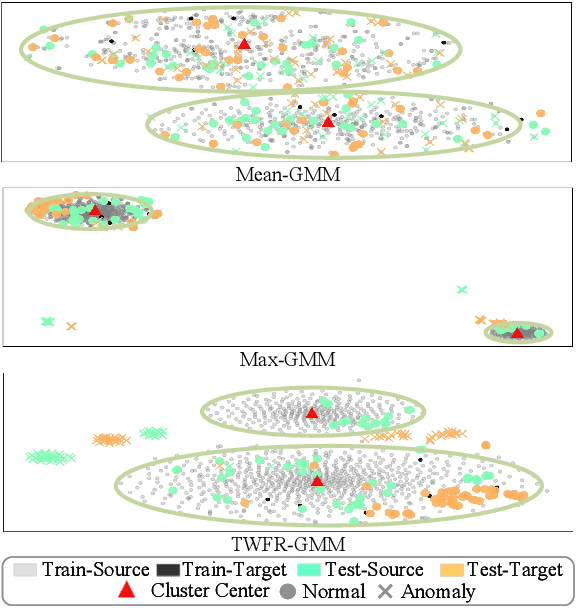
Although deep learning is the mainstream method in unsupervised anomalous sound detection, Gaussian Mixture Model (GMM) with statistical audio frequency representation as input can achieve comparable results with much lower model complexity and fewer parameters. Existing statistical frequency representations, e.g, the log-Mel spectrogram's average or maximum over time, do not always work well for different machines. This paper presents Time-Weighted Frequency Domain Representation (TWFR) with the GMM method (TWFR-GMM) for anomalous sound detection. The TWFR is a generalized statistical frequency domain representation that can adapt to different machine types, using the global weighted ranking pooling over time-domain. This allows GMM estimator to recognize anomalies, even under domain-shift conditions, as visualized with a Mahalanobis distance-based metric. Experiments on DCASE 2022 Challenge Task2 dataset show that our method has better detection performance than recent deep learning methods. TWFR-GMM is the core of our submission that achieved the 3rd place in DCASE 2022 Challenge Task2.
A Multi-Task Learning Framework for Overcoming the Catastrophic Forgetting in Automatic Speech Recognition
Apr 17, 2019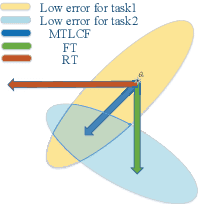
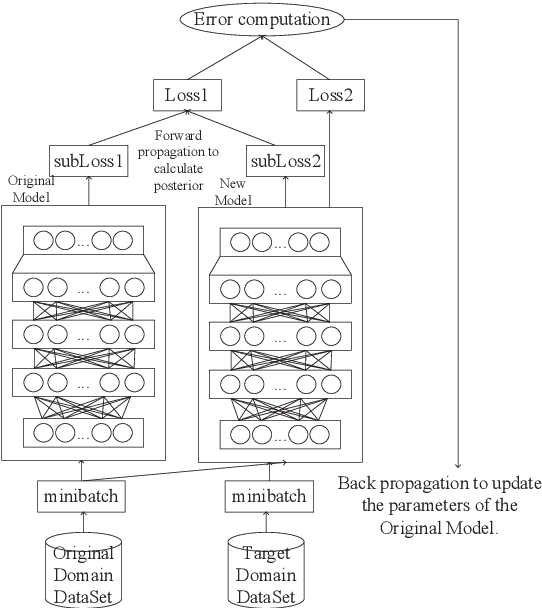
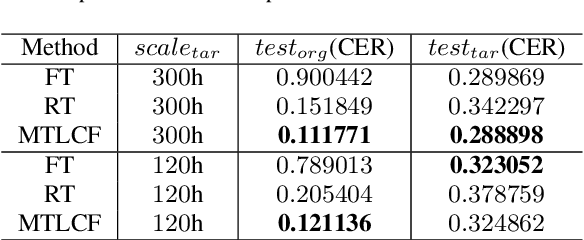
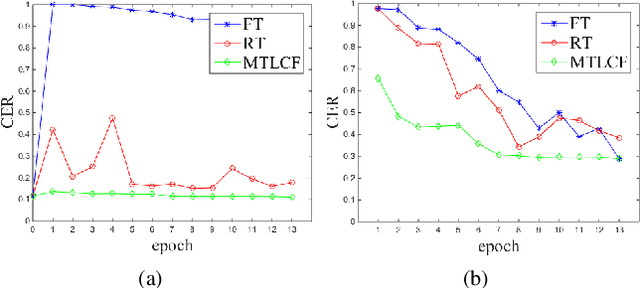
Recently, data-driven based Automatic Speech Recognition (ASR) systems have achieved state-of-the-art results. And transfer learning is often used when those existing systems are adapted to the target domain, e.g., fine-tuning, retraining. However, in the processes, the system parameters may well deviate too much from the previously learned parameters. Thus, it is difficult for the system training process to learn knowledge from target domains meanwhile not forgetting knowledge from the previous learning process, which is called as catastrophic forgetting (CF). In this paper, we attempt to solve the CF problem with the lifelong learning and propose a novel multi-task learning (MTL) training framework for ASR. It considers reserving original knowledge and learning new knowledge as two independent tasks, respectively. On the one hand, we constrain the new parameters not to deviate too far from the original parameters and punish the new system when forgetting original knowledge. On the other hand, we force the new system to solve new knowledge quickly. Then, a MTL mechanism is employed to get the balance between the two tasks. We applied our method to an End2End ASR task and obtained the best performance in both target and original datasets.
Hard Sample Mining for the Improved Retraining of Automatic Speech Recognition
Apr 17, 2019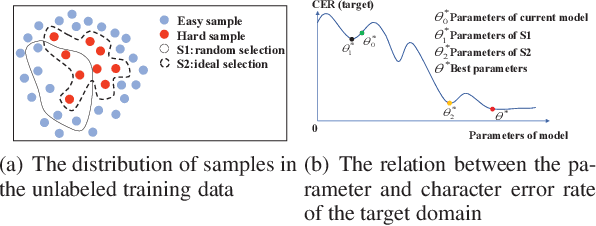
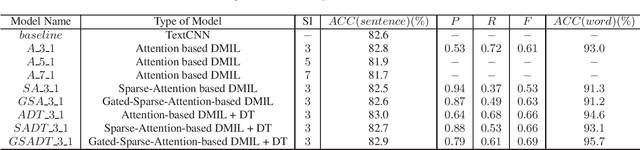
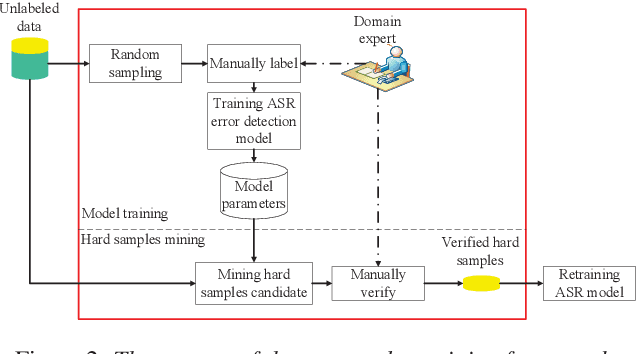

It is an effective way that improves the performance of the existing Automatic Speech Recognition (ASR) systems by retraining with more and more new training data in the target domain. Recently, Deep Neural Network (DNN) has become a successful model in the ASR field. In the training process of the DNN based methods, a back propagation of error between the transcription and the corresponding annotated text is used to update and optimize the parameters. Thus, the parameters are more influenced by the training samples with a big propagation error than the samples with a small one. In this paper, we define the samples with significant error as the hard samples and try to improve the performance of the ASR system by adding many of them. Unfortunately, the hard samples are sparse in the training data of the target domain, and manually label them is expensive. Therefore, we propose a hard samples mining method based on an enhanced deep multiple instance learning, which can find the hard samples from unlabeled training data by using a small subset of the dataset with manual labeling in the target domain. We applied our method to an End2End ASR task and obtained the best performance.
Guarantees of Augmented Trace Norm Models in Tensor Recovery
Jul 23, 2012
This paper studies the recovery guarantees of the models of minimizing $\|\mathcal{X}\|_*+\frac{1}{2\alpha}\|\mathcal{X}\|_F^2$ where $\mathcal{X}$ is a tensor and $\|\mathcal{X}\|_*$ and $\|\mathcal{X}\|_F$ are the trace and Frobenius norm of respectively. We show that they can efficiently recover low-rank tensors. In particular, they enjoy exact guarantees similar to those known for minimizing $\|\mathcal{X}\|_*$ under the conditions on the sensing operator such as its null-space property, restricted isometry property, or spherical section property. To recover a low-rank tensor $\mathcal{X}^0$, minimizing $\|\mathcal{X}\|_*+\frac{1}{2\alpha}\|\mathcal{X}\|_F^2$ returns the same solution as minimizing $\|\mathcal{X}\|_*$ almost whenever $\alpha\geq10\mathop {\max}\limits_{i}\|X^0_{(i)}\|_2$.
Online Learning for Classification of Low-rank Representation Features and Its Applications in Audio Segment Classification
Dec 19, 2011


In this paper, a novel framework based on trace norm minimization for audio segment is proposed. In this framework, both the feature extraction and classification are obtained by solving corresponding convex optimization problem with trace norm regularization. For feature extraction, robust principle component analysis (robust PCA) via minimization a combination of the nuclear norm and the $\ell_1$-norm is used to extract low-rank features which are robust to white noise and gross corruption for audio segments. These low-rank features are fed to a linear classifier where the weight and bias are learned by solving similar trace norm constrained problems. For this classifier, most methods find the weight and bias in batch-mode learning, which makes them inefficient for large-scale problems. In this paper, we propose an online framework using accelerated proximal gradient method. This framework has a main advantage in memory cost. In addition, as a result of the regularization formulation of matrix classification, the Lipschitz constant was given explicitly, and hence the step size estimation of general proximal gradient method was omitted in our approach. Experiments on real data sets for laugh/non-laugh and applause/non-applause classification indicate that this novel framework is effective and noise robust.