 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-based Autoencoder with ID Constraint for Unsupervised Anomalous Sound Detection
Oct 13, 2023Unsupervised anomalous sound detection (ASD) aims to detect unknown anomalous sounds of devices when only normal sound data is available. The autoencoder (AE) and self-supervised learning based methods are two mainstream methods. However, the AE-based methods could be limited as the feature learned from normal sounds can also fit with anomalous sounds, reducing the ability of the model in detecting anomalies from sound. The self-supervised methods are not always stable and perform differently, even for machines of the same type. In addition, the anomalous sound may be short-lived, making it even harder to distinguish from normal sound. This paper proposes an ID constrained Transformer-based autoencoder (IDC-TransAE) architecture with weighted anomaly score computation for unsupervised ASD. Machine ID is employed to constrain the latent space of the Transformer-based autoencoder (TransAE) by introducing a simple ID classifier to learn the difference in the distribution for the same machine type and enhance the ability of the model in distinguishing anomalous sound. Moreover, weighted anomaly score computation is introduced to highlight the anomaly scores of anomalous events that only appear for a short time. Experiments performed on DCASE 2020 Challenge Task2 development dataset demonstrate the effectiveness and superiority of our proposed method.
Anomalous Sound Detection Using Self-Attention-Based Frequency Pattern Analysis of Machine Sounds
Sep 06, 2023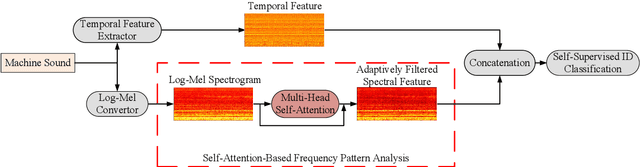



Different machines can exhibit diverse frequency patterns in their emitted sound. This feature has been recently explored in anomaly sound detection and reached state-of-the-art performance. However, existing methods rely on the manual or empirical determination of the frequency filter by observing the effective frequency range in the training data, which may be impractical for general application. This paper proposes an anomalous sound detection method using self-attention-based frequency pattern analysis and spectral-temporal information fusion. Our experiments demonstrate that the self-attention module automatically and adaptively analyses the effective frequencies of a machine sound and enhances that information in the spectral feature representation. With spectral-temporal information fusion, the obtained audio feature eventually improves the anomaly detection performance on the DCASE 2020 Challenge Task 2 dataset.
Time-weighted Frequency Domain Audio Representation with GMM Estimator for Anomalous Sound Detection
May 05, 2023Although deep learning is the mainstream method in unsupervised anomalous sound detection, Gaussian Mixture Model (GMM) with statistical audio frequency representation as input can achieve comparable results with much lower model complexity and fewer parameters. Existing statistical frequency representations, e.g, the log-Mel spectrogram's average or maximum over time, do not always work well for different machines. This paper presents Time-Weighted Frequency Domain Representation (TWFR) with the GMM method (TWFR-GMM) for anomalous sound detection. The TWFR is a generalized statistical frequency domain representation that can adapt to different machine types, using the global weighted ranking pooling over time-domain. This allows GMM estimator to recognize anomalies, even under domain-shift conditions, as visualized with a Mahalanobis distance-based metric. Experiments on DCASE 2022 Challenge Task2 dataset show that our method has better detection performance than recent deep learning methods. TWFR-GMM is the core of our submission that achieved the 3rd place in DCASE 2022 Challenge Task2.
Anomalous Sound Detection using Audio Representation with Machine ID based Contrastive Learning Pretraining
Apr 10, 2023Existing contrastive learning methods for anomalous sound detection refine the audio representation of each audio sample by using the contrast between the samples' augmentations (e.g., with time or frequency masking). However, they might be biased by the augmented data, due to the lack of physical properties of machine sound, thereby limiting the detection performance. This paper uses contrastive learning to refine audio representations for each machine ID, rather than for each audio sample. The proposed two-stage method uses contrastive learning to pretrain the audio representation model by incorporating machine ID and a self-supervised ID classifier to fine-tune the learnt model, while enhancing the relation between audio features from the same ID. Experiments show that our method outperforms the state-of-the-art methods using contrastive learning or self-supervised classification in overall anomaly detection performance and stability on DCASE 2020 Challenge Task2 dataset.
Anomalous Sound Detection using Spectral-Temporal Information Fusion
Jan 14, 2022


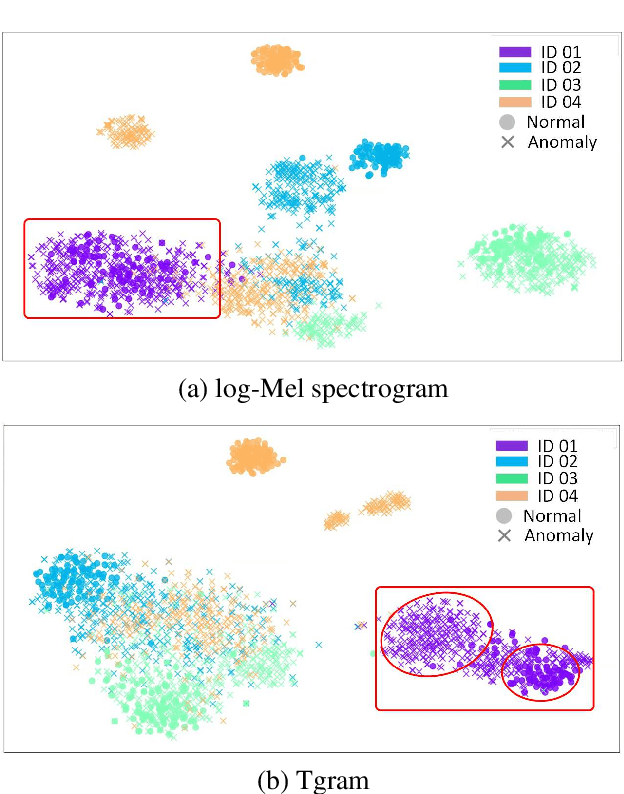
Unsupervised anomalous sound detection aims to detect unknown abnormal sounds of machines from normal sounds. However, the state-of-the-art approaches are not always stable and perform dramatically differently even for machines of the same type, making it impractical for general applications. This paper proposes a spectral-temporal fusion based self-supervised method to model the feature of the normal sound, which improves the stability and performance consistency in detection of anomalous sounds from individual machines, even of the same type. Experiments on the DCASE 2020 Challenge Task 2 dataset show that the proposed method achieved 81.39%, 83.48%, 98.22% and 98.83% in terms of the minimum AUC (worst-case detection performance amongst individuals) in four types of real machines (fan, pump, slider and valve), respectively, giving 31.79%, 17.78%, 10.42% and 21.13% improvement compared to the state-of-the-art method, i.e., Glow_Aff. Moreover, the proposed method has improved AUC (average performance of individuals) for all the types of machines in the dataset.