 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Loss Based Frame-wise Feature disentanglement for Polyphonic Sound Event Detection
Jan 11, 2024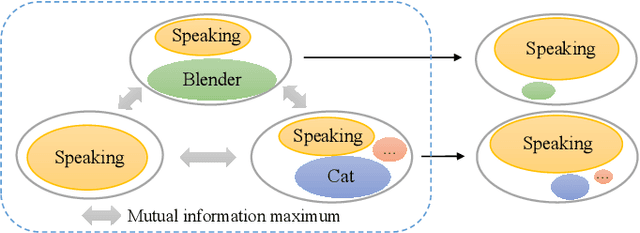
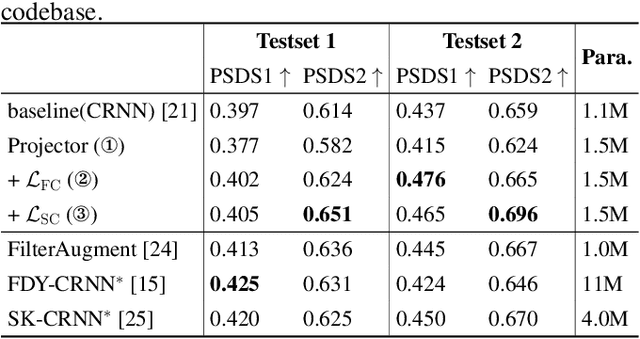
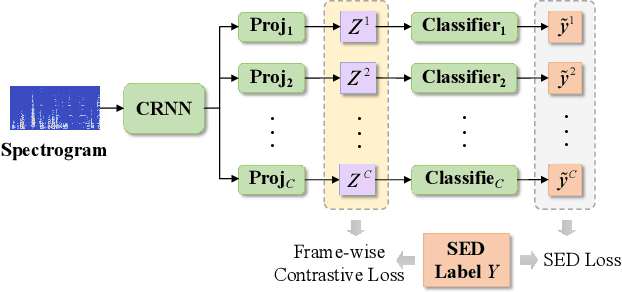
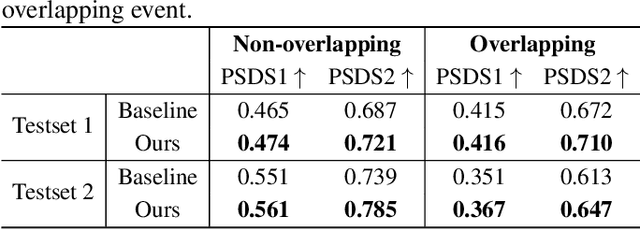
Overlapping sound events are ubiquitous in real-world environments, but existing end-to-end sound event detection (SED) methods still struggle to detect them effectively. A critical reason is that these methods represent overlapping events using shared and entangled frame-wise features, which degrades the feature discrimination. To solve the problem, we propose a disentangled feature learning framework to learn a category-specific representation. Specifically, we employ different projectors to learn the frame-wise features for each category. To ensure that these feature does not contain information of other categories, we maximize the common information between frame-wise features within the same category and propose a frame-wise contrastive loss. In addition, considering that the labeled data used by the proposed method is limited, we propose a semi-supervised frame-wise contrastive loss that can leverage large amounts of unlabeled data to achieve feature disentanglement. The experimental results demonstrate the effectiveness of our method.
Fuzzy inference system application for oil-water flow patterns identification
May 24, 2021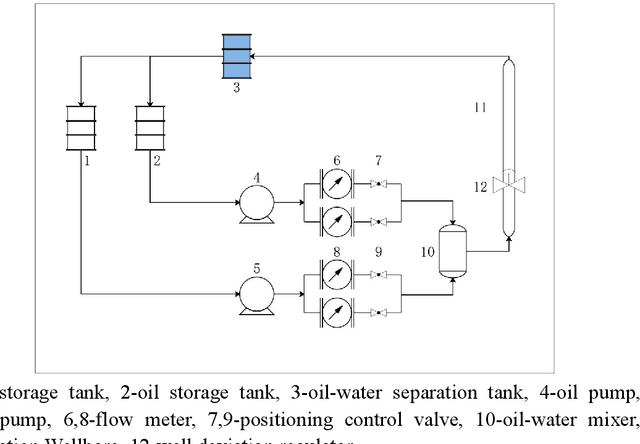
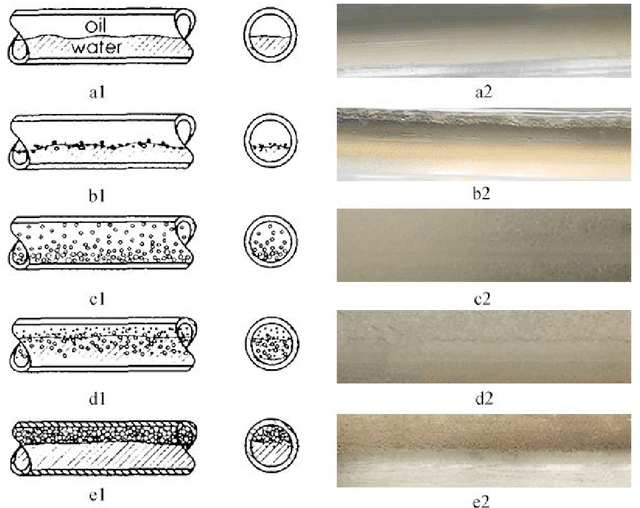
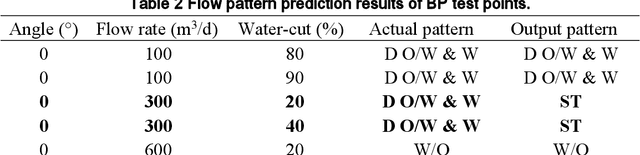
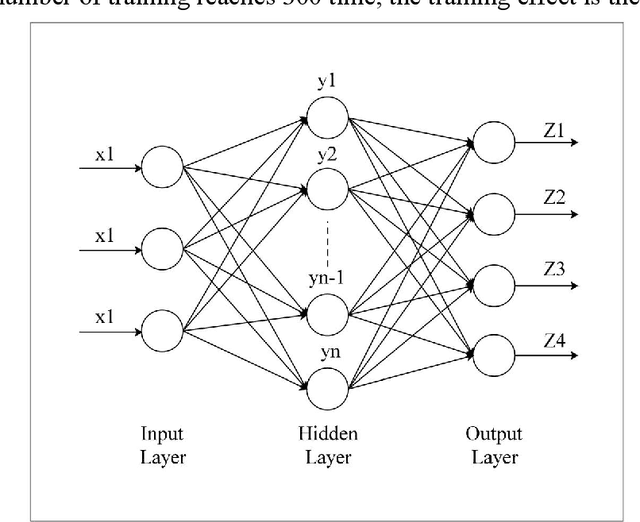
With the continuous development of the petroleum industry, long-distance transportation of oil and gas has been the norm. Due to gravity differentiation in horizontal wells and highly deviated wells (non-vertical wells), the water phase at the bottom of the pipeline will cause scaling and corrosion in the pipeline. Scaling and corrosion will make the transportation process difficult, and transportation costs will be considerably increased. Therefore, the study of the oil-water two-phase flow pattern is of great importance to oil production. In this paper, a fuzzy inference system is used to predict the flow pattern of the fluid, get the prediction result, and compares it with the prediction result of the BP neural network. From the comparison of the results, we found that the prediction results of the fuzzy inference system are more accurate and reliable than the prediction results of the BP neural network. At the same time, it can realize real-time monitoring and has less error control. Experimental results demonstrate that in the entire production logging process of non-vertical wells, the use of a fuzzy inference system to predict fluid flow patterns can greatly save production costs while ensuring the safe operation of production equipment.
Acoustic Scene Classification by Implicitly Identifying Distinct Sound Events
Apr 27, 2019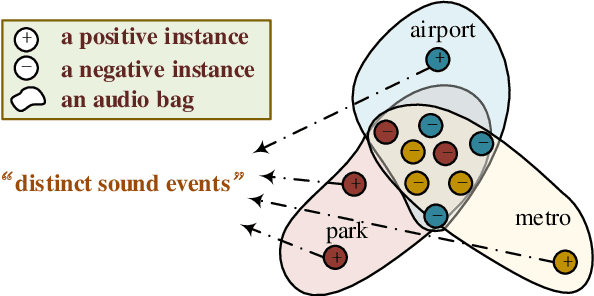

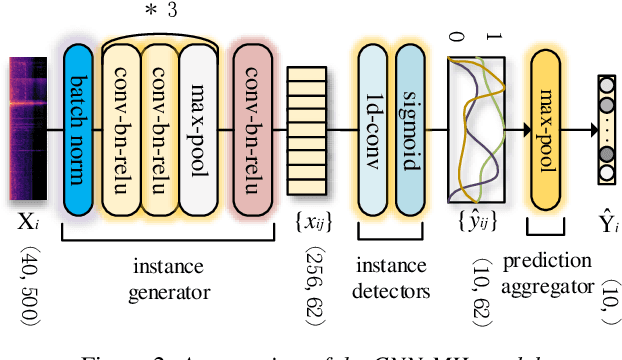
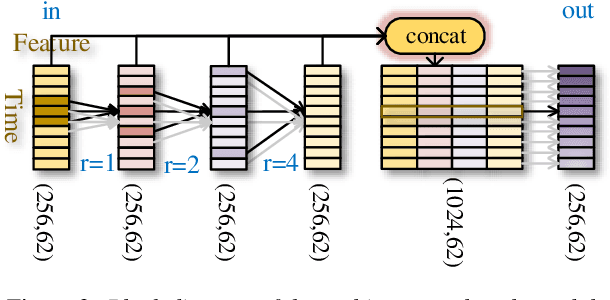
In this paper, we propose a new strategy for acoustic scene classification (ASC) , namely recognizing acoustic scenes through identifying distinct sound events. This differs from existing strategies, which focus on characterizing global acoustical distributions of audio or the temporal evolution of short-term audio features, without analysis down to the level of sound events. To identify distinct sound events for each scene, we formulate ASC in a multi-instance learning (MIL) framework, where each audio recording is mapped into a bag-of-instances representation. Here, instances can be seen as high-level representations for sound events inside a scene. We also propose a MIL neural networks model, which implicitly identifies distinct instances (i.e., sound events). Furthermore, we propose two specially designed modules that model the multi-temporal scale and multi-modal natures of the sound events respectively. The experiments were conducted on the official development set of the DCASE2018 Task1 Subtask B, and our best-performing model improves over the official baseline by 9.4% (68.3% vs 58.9%) in terms of classification accuracy. This study indicates that recognizing acoustic scenes by identifying distinct sound events is effective and paves the way for future studies that combine this strategy with previous ones.