 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic Scene Classification by Implicitly Identifying Distinct Sound Events
Paper and Code
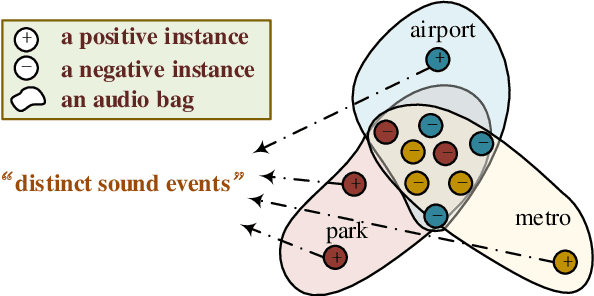

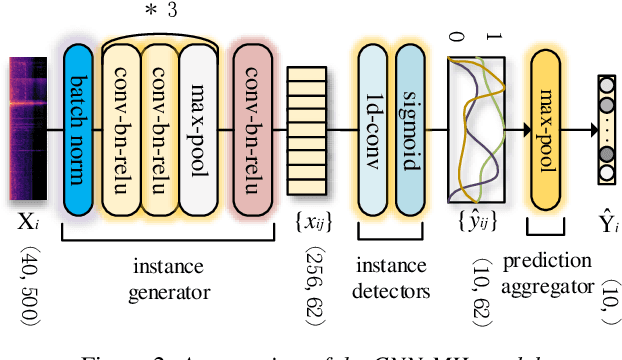
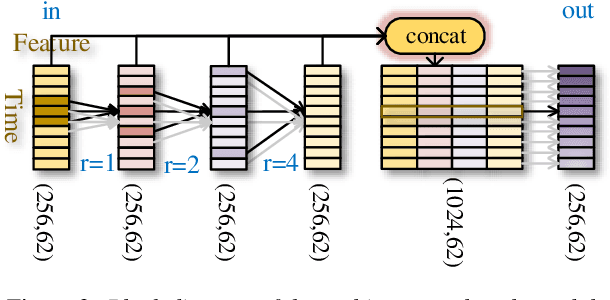
In this paper, we propose a new strategy for acoustic scene classification (ASC) , namely recognizing acoustic scenes through identifying distinct sound events. This differs from existing strategies, which focus on characterizing global acoustical distributions of audio or the temporal evolution of short-term audio features, without analysis down to the level of sound events. To identify distinct sound events for each scene, we formulate ASC in a multi-instance learning (MIL) framework, where each audio recording is mapped into a bag-of-instances representation. Here, instances can be seen as high-level representations for sound events inside a scene. We also propose a MIL neural networks model, which implicitly identifies distinct instances (i.e., sound events). Furthermore, we propose two specially designed modules that model the multi-temporal scale and multi-modal natures of the sound events respectively. The experiments were conducted on the official development set of the DCASE2018 Task1 Subtask B, and our best-performing model improves over the official baseline by 9.4% (68.3% vs 58.9%) in terms of classification accuracy. This study indicates that recognizing acoustic scenes by identifying distinct sound events is effective and paves the way for future studies that combine this strategy with previous ones.