 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisible Singularities Guided Correlation Network for Limited-Angle CT Reconstruction
Jan 30, 2026Limited-angle computed tomography (LACT) offers the advantages of reduced radiation dose and shortened scanning time. Traditional reconstruction algorithms exhibit various inherent limitations in LACT. Currently, most deep learning-based LACT reconstruction methods focus on multi-domain fusion or the introduction of generic priors, failing to fully align with the core imaging characteristics of LACT-such as the directionality of artifacts and directional loss of structural information, which are caused by the absence of projection angles in certain directions. Inspired by the theory of visible and invisible singularities, taking into account the aforementioned core imaging characteristics of LACT, we propose a Visible Singularities Guided Correlation network for LACT reconstruction (VSGC). The design philosophy of VSGC consists of two core steps: First, extract VS edge features from LACT images and focus the model's attention on these VS. Second, establish correlations between the VS edge features and other regions of the image. Additionally, a multi-scale loss function with anisotropic constraint is employed to constrain the model to converge in multiple aspects. Finally, qualitative and quantitative validations are conducted on both simulated and real datasets to verify the effectiveness and feasibility of the proposed design. Particularly, in comparison with alternative methods, VSGC delivers more prominent performance in small angular ranges, with the PSNR improvement of 2.45 dB and the SSIM enhancement of 1.5\%. The code is publicly available at https://github.com/yqx7150/VSGC.
Anatomy Aware Cascade Network: Bridging Epistemic Uncertainty and Geometric Manifold for 3D Tooth Segmentation
Jan 12, 2026Accurate three-dimensional (3D) tooth segmentation from Cone-Beam Computed Tomography (CBCT) is a prerequisite for digital dental workflows. However, achieving high-fidelity segmentation remains challenging due to adhesion artifacts in naturally occluded scans, which are caused by low contrast and indistinct inter-arch boundaries. To address these limitations, we propose the Anatomy Aware Cascade Network (AACNet), a coarse-to-fine framework designed to resolve boundary ambiguity while maintaining global structural consistency. Specifically, we introduce two mechanisms: the Ambiguity Gated Boundary Refiner (AGBR) and the Signed Distance Map guided Anatomical Attention (SDMAA). The AGBR employs an entropy based gating mechanism to perform targeted feature rectification in high uncertainty transition zones. Meanwhile, the SDMAA integrates implicit geometric constraints via signed distance map to enforce topological consistency, preventing the loss of spatial details associated with standard pooling. Experimental results on a dataset of 125 CBCT volumes demonstrate that AACNet achieves a Dice Similarity Coefficient of 90.17 \% and a 95\% Hausdorff Distance of 3.63 mm, significantly outperforming state-of-the-art methods. Furthermore, the model exhibits strong generalization on an external dataset with an HD95 of 2.19 mm, validating its reliability for downstream clinical applications such as surgical planning. Code for AACNet is available at https://github.com/shiliu0114/AACNet.
LaminoDiff: Artifact-Free Computed Laminography in Non-Destructive Testing via Diffusion Model
Jan 12, 2026Computed Laminography (CL) is a key non-destructive testing technology for the visualization of internal structures in large planar objects. The inherent scanning geometry of CL inevitably results in inter-layer aliasing artifacts, limiting its practical application, particularly in electronic component inspection. While deep learning (DL) provides a powerful paradigm for artifact removal, its effectiveness is often limited by the domain gap between synthetic data and real-world data. In this work, we present LaminoDiff, a framework to integrate a diffusion model with a high-fidelity prior representation to bridge the domain gap in CL imaging. This prior, generated via a dual-modal CT-CL fusion strategy, is integrated into the proposed network as a conditional constraint. This integration ensures high-precision preservation of circuit structures and geometric fidelity while suppressing artifacts. Extensive experiments on both simulated and real PCB datasets demonstrate that LaminoDiff achieves high-fidelity reconstruction with competitive performance in artifact suppression and detail recovery. More importantly, the results facilitate reliable automated defect recognition.
ESDiff: Encoding Strategy-inspired Diffusion Model with Few-shot Learning for Color Image Inpainting
Apr 24, 2025Image inpainting is a technique used to restore missing or damaged regions of an image. Traditional methods primarily utilize information from adjacent pixels for reconstructing missing areas, while they struggle to preserve complex details and structures. Simultaneously, models based on deep learning necessitate substantial amounts of training data. To address this challenge, an encoding strategy-inspired diffusion model with few-shot learning for color image inpainting is proposed in this paper. The main idea of this novel encoding strategy is the deployment of a "virtual mask" to construct high-dimensional objects through mutual perturbations between channels. This approach enables the diffusion model to capture diverse image representations and detailed features from limited training samples. Moreover, the encoding strategy leverages redundancy between channels, integrates with low-rank methods during iterative inpainting, and incorporates the diffusion model to achieve accurate information output. Experimental results indicate that our method exceeds current techniques in quantitative metrics, and the reconstructed images quality has been improved in aspects of texture and structural integrity, leading to more precise and coherent results.
Virtual-mask Informed Prior for Sparse-view Dual-Energy CT Reconstruction
Apr 10, 2025Sparse-view sampling in dual-energy computed tomography (DECT) significantly reduces radiation dose and increases imaging speed, yet is highly prone to artifacts. Although diffusion models have demonstrated potential in effectively handling incomplete data, most existing methods in this field focus on the image do-main and lack global constraints, which consequently leads to insufficient reconstruction quality. In this study, we propose a dual-domain virtual-mask in-formed diffusion model for sparse-view reconstruction by leveraging the high inter-channel correlation in DECT. Specifically, the study designs a virtual mask and applies it to the high-energy and low-energy data to perform perturbation operations, thus constructing high-dimensional tensors that serve as the prior information of the diffusion model. In addition, a dual-domain collaboration strategy is adopted to integrate the information of the randomly selected high-frequency components in the wavelet domain with the information in the projection domain, for the purpose of optimizing the global struc-tures and local details. Experimental results indicated that the present method exhibits excellent performance across multiple datasets.
GTS-LUM: Reshaping User Behavior Modeling with LLMs in Telecommunications Industry
Apr 09, 2025

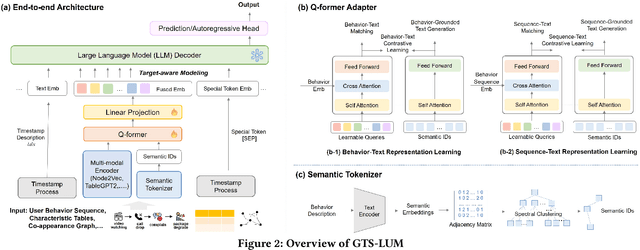

As telecommunication service providers shifting their focus to analyzing user behavior for package design and marketing interventions, a critical challenge lies in developing a unified, end-to-end framework capable of modeling long-term and periodic user behavior sequences with diverse time granularities, multi-modal data inputs, and heterogeneous labels. This paper introduces GTS-LUM, a novel user behavior model that redefines modeling paradigms in telecommunication settings. GTS-LUM adopts a (multi-modal) encoder-adapter-LLM decoder architecture, enhanced with several telecom-specific innovations. Specifically, the model incorporates an advanced timestamp processing method to handle varying time granularities. It also supports multi-modal data inputs -- including structured tables and behavior co-occurrence graphs -- and aligns these with semantic information extracted by a tokenizer using a Q-former structure. Additionally, GTS-LUM integrates a front-placed target-aware mechanism to highlight historical behaviors most relevant to the target. Extensive experiments on industrial dataset validate the effectiveness of this end-to-end framework and also demonstrate that GTS-LUM outperforms LLM4Rec approaches which are popular in recommendation systems, offering an effective and generalizing solution for user behavior modeling in telecommunications.
Physics-informed DeepCT: Sinogram Wavelet Decomposition Meets Masked Diffusion
Jan 17, 2025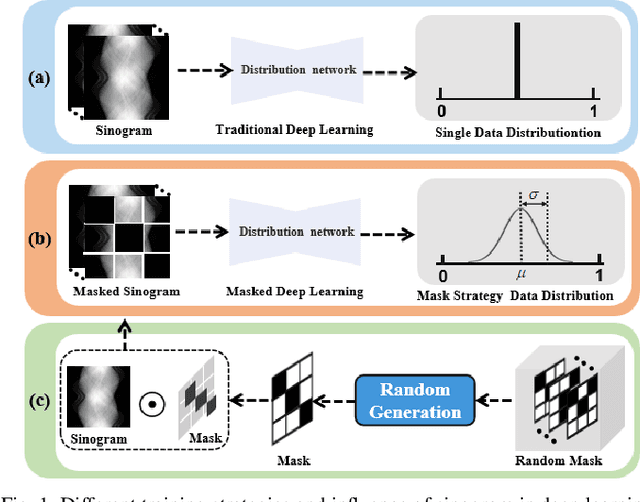
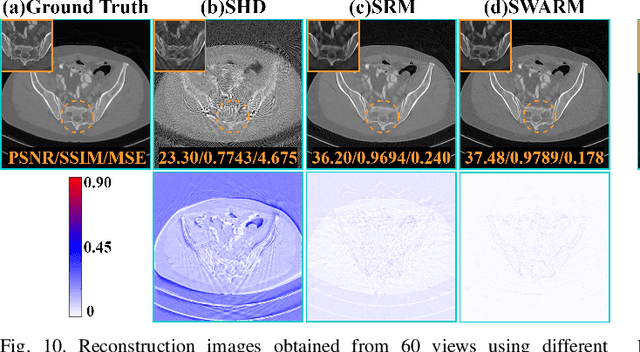
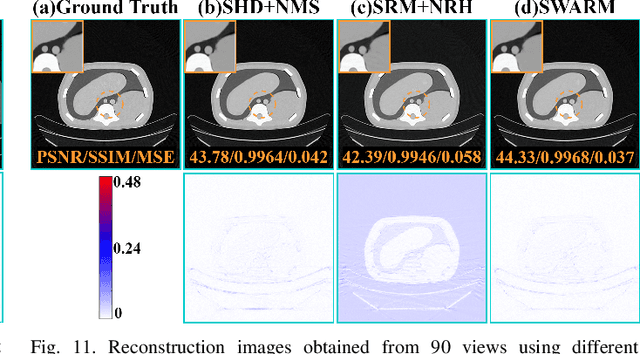
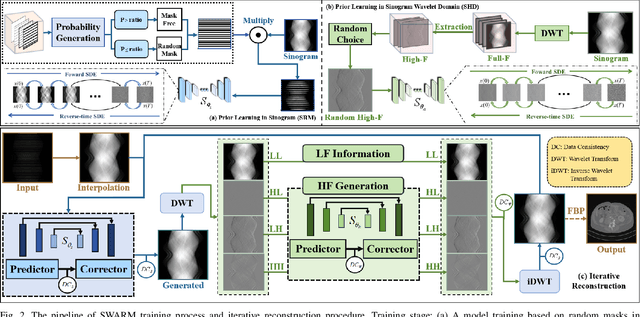
Diffusion model shows remarkable potential on sparse-view computed tomography (SVCT) reconstruction. However, when a network is trained on a limited sample space, its generalization capability may be constrained, which degrades performance on unfamiliar data. For image generation tasks, this can lead to issues such as blurry details and inconsistencies between regions. To alleviate this problem, we propose a Sinogram-based Wavelet random decomposition And Random mask diffusion Model (SWARM) for SVCT reconstruction. Specifically, introducing a random mask strategy in the sinogram effectively expands the limited training sample space. This enables the model to learn a broader range of data distributions, enhancing its understanding and generalization of data uncertainty. In addition, applying a random training strategy to the high-frequency components of the sinogram wavelet enhances feature representation and improves the ability to capture details in different frequency bands, thereby improving performance and robustness. Two-stage iterative reconstruction method is adopted to ensure the global consistency of the reconstructed image while refining its details. Experimental results demonstrate that SWARM outperforms competing approaches in both quantitative and qualitative performance across various datasets.
RED: Residual Estimation Diffusion for Low-Dose PET Sinogram Reconstruction
Nov 08, 2024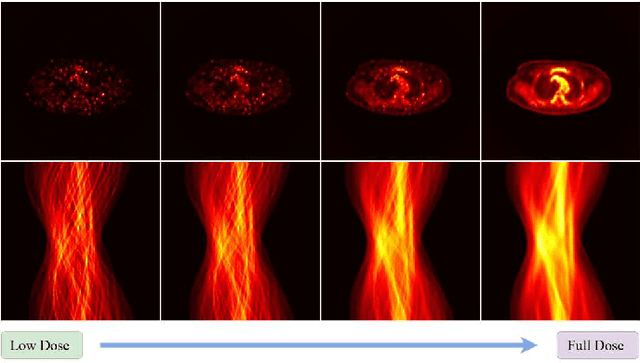

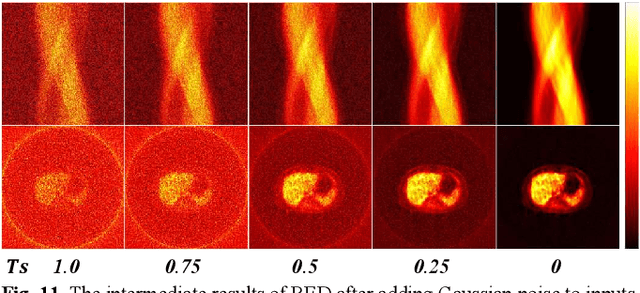
Recent advances in diffusion models have demonstrated exceptional performance in generative tasks across vari-ous fields. In positron emission tomography (PET), the reduction in tracer dose leads to information loss in sino-grams. Using diffusion models to reconstruct missing in-formation can improve imaging quality. Traditional diffu-sion models effectively use Gaussian noise for image re-constructions. However, in low-dose PET reconstruction, Gaussian noise can worsen the already sparse data by introducing artifacts and inconsistencies. To address this issue, we propose a diffusion model named residual esti-mation diffusion (RED). From the perspective of diffusion mechanism, RED uses the residual between sinograms to replace Gaussian noise in diffusion process, respectively sets the low-dose and full-dose sinograms as the starting point and endpoint of reconstruction. This mechanism helps preserve the original information in the low-dose sinogram, thereby enhancing reconstruction reliability. From the perspective of data consistency, RED introduces a drift correction strategy to reduce accumulated prediction errors during the reverse process. Calibrating the inter-mediate results of reverse iterations helps maintain the data consistency and enhances the stability of reconstruc-tion process. Experimental results show that RED effec-tively improves the quality of low-dose sinograms as well as the reconstruction results. The code is available at: https://github.com/yqx7150/RED.
MSDiff: Multi-Scale Diffusion Model for Ultra-Sparse View CT Reconstruction
May 09, 2024



Computed Tomography (CT) technology reduces radiation haz-ards to the human body through sparse sampling, but fewer sampling angles pose challenges for image reconstruction. Score-based generative models are widely used in sparse-view CT re-construction, performance diminishes significantly with a sharp reduction in projection angles. Therefore, we propose an ultra-sparse view CT reconstruction method utilizing multi-scale dif-fusion models (MSDiff), designed to concentrate on the global distribution of information and facilitate the reconstruction of sparse views with local image characteristics. Specifically, the proposed model ingeniously integrates information from both comprehensive sampling and selectively sparse sampling tech-niques. Through precise adjustments in diffusion model, it is capable of extracting diverse noise distribution, furthering the understanding of the overall structure of images, and aiding the fully sampled model in recovering image information more effec-tively. By leveraging the inherent correlations within the projec-tion data, we have designed an equidistant mask, enabling the model to focus its attention more effectively. Experimental re-sults demonstrated that the multi-scale model approach signifi-cantly improved the quality of image reconstruction under ultra-sparse angles, with good generalization across various datasets.