 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Discrete Modeling via Boundary Conditional Diffusion Processes
Oct 29, 2024

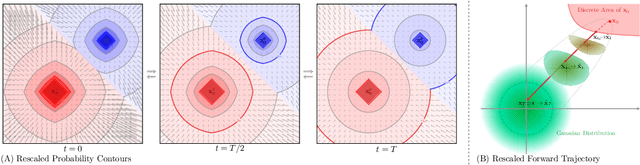

We present an novel framework for efficiently and effectively extending the powerful continuous diffusion processes to discrete modeling. Previous approaches have suffered from the discrepancy between discrete data and continuous modeling. Our study reveals that the absence of guidance from discrete boundaries in learning probability contours is one of the main reasons. To address this issue, we propose a two-step forward process that first estimates the boundary as a prior distribution and then rescales the forward trajectory to construct a boundary conditional diffusion model. The reverse process is proportionally adjusted to guarantee that the learned contours yield more precise discrete data. Experimental results indicate that our approach achieves strong performance in both language modeling and discrete image generation tasks. In language modeling, our approach surpasses previous state-of-the-art continuous diffusion language models in three translation tasks and a summarization task, while also demonstrating competitive performance compared to auto-regressive transformers. Moreover, our method achieves comparable results to continuous diffusion models when using discrete ordinal pixels and establishes a new state-of-the-art for categorical image generation on the Cifar-10 dataset.
Hierarchical Catalogue Generation for Literature Review: A Benchmark
Apr 10, 2023



Multi-document scientific summarization can extract and organize important information from an abundant collection of papers, arousing widespread attention recently. However, existing efforts focus on producing lengthy overviews lacking a clear and logical hierarchy. To alleviate this problem, we present an atomic and challenging task named Hierarchical Catalogue Generation for Literature Review (HiCatGLR), which aims to generate a hierarchical catalogue for a review paper given various references. We carefully construct a novel English Hierarchical Catalogues of Literature Reviews Dataset (HiCaD) with 13.8k literature review catalogues and 120k reference papers, where we benchmark diverse experiments via the end-to-end and pipeline methods. To accurately assess the model performance, we design evaluation metrics for similarity to ground truth from semantics and structure. Besides, our extensive analyses verify the high quality of our dataset and the effectiveness of our evaluation metrics. Furthermore, we discuss potential directions for this task to motivate future research.