 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Pre-trained Language Models with Syntactic Dependency Prediction Task for Chinese Semantic Error Recognition
Paper and Code
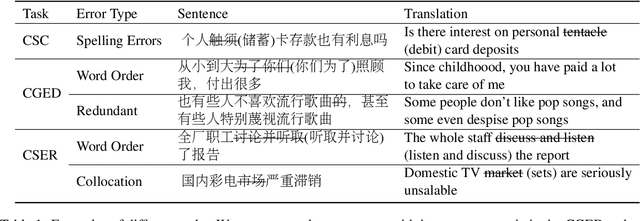
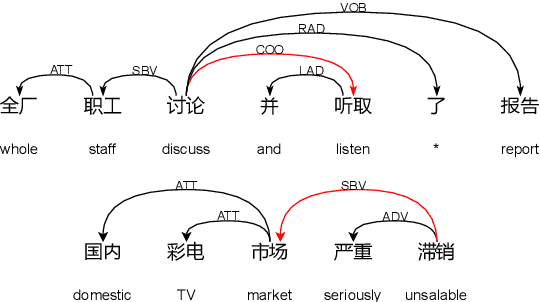

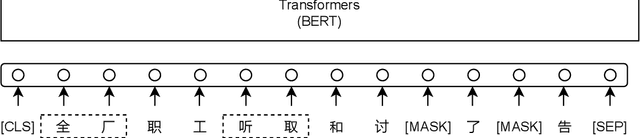
Existing Chinese text error detection mainly focuses on spelling and simple grammatical errors. These errors have been studied extensively and are relatively simple for humans. On the contrary, Chinese semantic errors are understudied and more complex that humans cannot easily recognize. The task of this paper is Chinese Semantic Error Recognition (CSER), a binary classification task to determine whether a sentence contains semantic errors. The current research has no effective method to solve this task. In this paper, we inherit the model structure of BERT and design several syntax-related pre-training tasks so that the model can learn syntactic knowledge. Our pre-training tasks consider both the directionality of the dependency structure and the diversity of the dependency relationship. Due to the lack of a published dataset for CSER, we build a high-quality dataset for CSER for the first time named Corpus of Chinese Linguistic Semantic Acceptability (CoCLSA). The experimental results on the CoCLSA show that our methods outperform universal pre-trained models and syntax-infused models.