 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLM-Combiner: A Contextual Rewriting Model for Chinese Grammatical Error Correction
Paper and Code

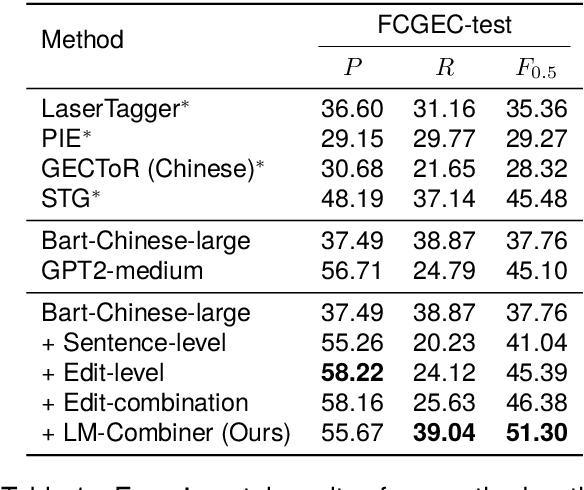
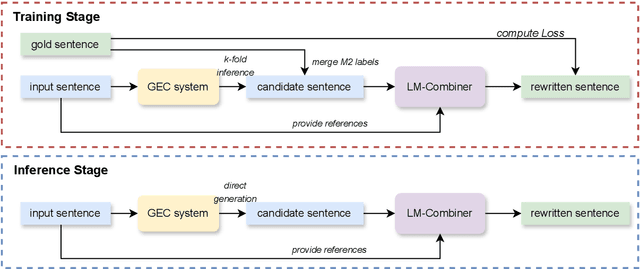
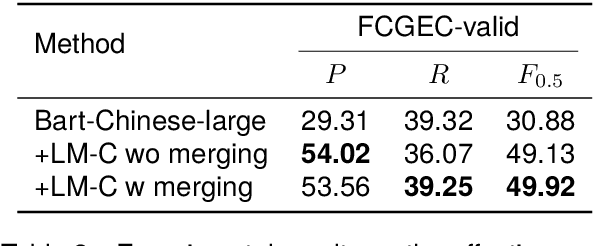
Over-correction is a critical problem in Chinese grammatical error correction (CGEC) task. Recent work using model ensemble methods based on voting can effectively mitigate over-correction and improve the precision of the GEC system. However, these methods still require the output of several GEC systems and inevitably lead to reduced error recall. In this light, we propose the LM-Combiner, a rewriting model that can directly modify the over-correction of GEC system outputs without a model ensemble. Specifically, we train the model on an over-correction dataset constructed through the proposed K-fold cross inference method, which allows it to directly generate filtered sentences by combining the original and the over-corrected text. In the inference stage, we directly take the original sentences and the output results of other systems as input and then obtain the filtered sentences through LM-Combiner. Experiments on the FCGEC dataset show that our proposed method effectively alleviates the over-correction of the original system (+18.2 Precision) while ensuring the error recall remains unchanged. Besides, we find that LM-Combiner still has a good rewriting performance even with small parameters and few training data, and thus can cost-effectively mitigate the over-correction of black-box GEC systems (e.g., ChatGPT).