 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-based Video Editing via Multi-Modal Multi-Level Transformer
Apr 02, 2021
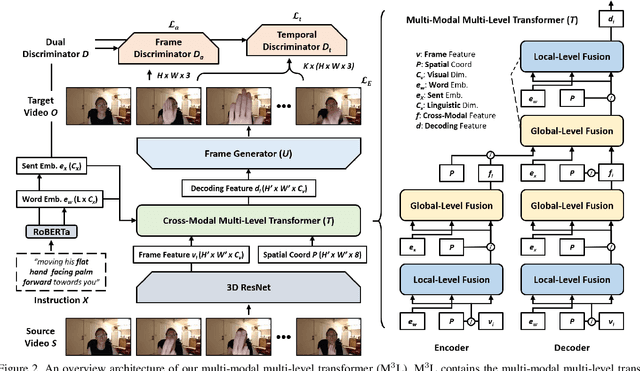

Video editing tools are widely used nowadays for digital design. Although the demand for these tools is high, the prior knowledge required makes it difficult for novices to get started. Systems that could follow natural language instructions to perform automatic editing would significantly improve accessibility. This paper introduces the language-based video editing (LBVE) task, which allows the model to edit, guided by text instruction, a source video into a target video. LBVE contains two features: 1) the scenario of the source video is preserved instead of generating a completely different video; 2) the semantic is presented differently in the target video, and all changes are controlled by the given instruction. We propose a Multi-Modal Multi-Level Transformer (M$^3$L-Transformer) to carry out LBVE. The M$^3$L-Transformer dynamically learns the correspondence between video perception and language semantic at different levels, which benefits both the video understanding and video frame synthesis. We build three new datasets for evaluation, including two diagnostic and one from natural videos with human-labeled text. Extensive experimental results show that M$^3$L-Transformer is effective for video editing and that LBVE can lead to a new field toward vision-and-language research.
StressNet: Detecting Stress in Thermal Videos
Nov 23, 2020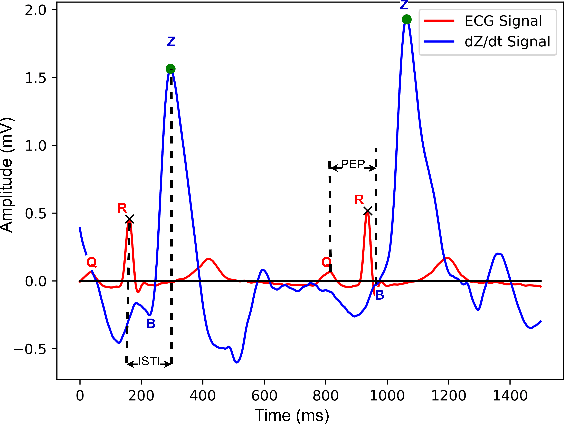
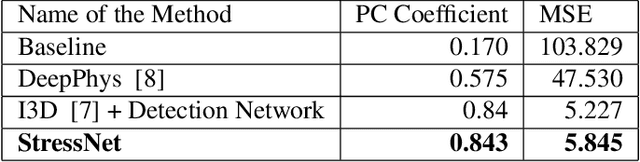
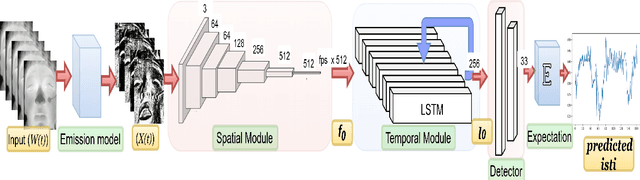
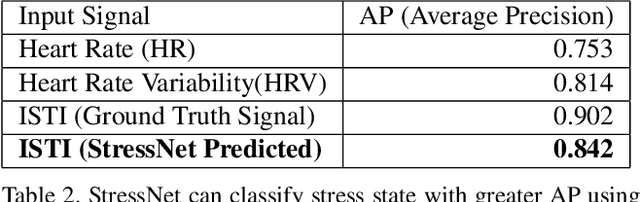
Precise measurement of physiological signals is critical for the effective monitoring of human vital signs. Recent developments in computer vision have demonstrated that signals such as pulse rate and respiration rate can be extracted from digital video of humans, increasing the possibility of contact-less monitoring. This paper presents a novel approach to obtaining physiological signals and classifying stress states from thermal video. The proposed network--"StressNet"--features a hybrid emission representation model that models the direct emission and absorption of heat by the skin and underlying blood vessels. This results in an information-rich feature representation of the face, which is used by spatio-temporal network for reconstructing the ISTI ( Initial Systolic Time Interval: a measure of change in cardiac sympathetic activity that is considered to be a quantitative index of stress in humans ). The reconstructed ISTI signal is fed into a stress-detection model to detect and classify the individual's stress state ( i.e. stress or no stress ). A detailed evaluation demonstrates that StressNet achieves estimated the ISTI signal with 95% accuracy and detect stress with average precision of 0.842. The source code is available on Github.
Estimating localized complexity of white-matter wiring with GANs
Oct 02, 2019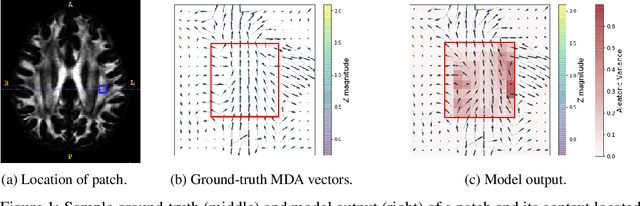
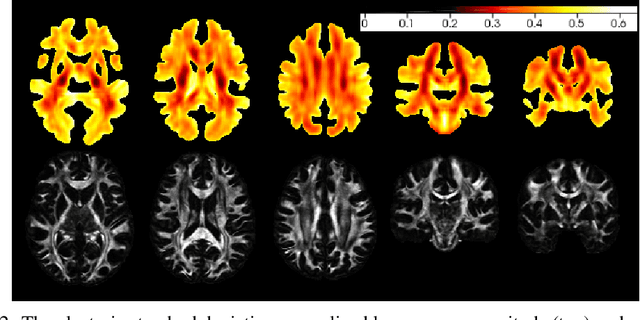
In-vivo examination of the physical connectivity of axonal projections through the white matter of the human brain is made possible by diffusion weighted magnetic resonance imaging (dMRI) Analysis of dMRI commonly considers derived scalar metrics such as fractional anisotrophy as proxies for "white matter integrity," and differences of such measures have been observed as significantly correlating with various neurological diagnosis and clinical measures such as executive function, presence of multiple sclerosis, and genetic similarity. The analysis of such voxel measures is confounded in areas of more complicated fiber wiring due to crossing, kissing, and dispersing fibers. Recently, Volz et al. introduced a simple probabilistic measure of the count of distinct fiber populations within a voxel, which was shown to reduce variance in group comparisons. We propose a complementary measure that considers the complexity of a voxel in context of its local region, with an aim to quantify the localized wiring complexity of every part of white matter. This allows, for example, identification of particularly ambiguous regions of the brain for tractographic approaches of modeling global wiring connectivity. Our method builds on recent advances in image inpainting, in which the task is to plausibly fill in a missing region of an image. Our proposed method builds on a Bayesian estimate of heteroscedastic aleatoric uncertainty of a region of white matter by inpainting it from its context. We define the localized wiring complexity of white matter as how accurately and confidently a well-trained model can predict the missing patch. In our results, we observe low aleatoric uncertainty along major neuronal pathways which increases at junctions and towards cortex boundaries. This directly quantifies the difficulty of lesion inpainting of dMRI images at all parts of white matter.
Spatial Coherence of Oriented White Matter Microstructure: Applications to White Matter Regions Associated with Genetic Similarity
Feb 14, 2018
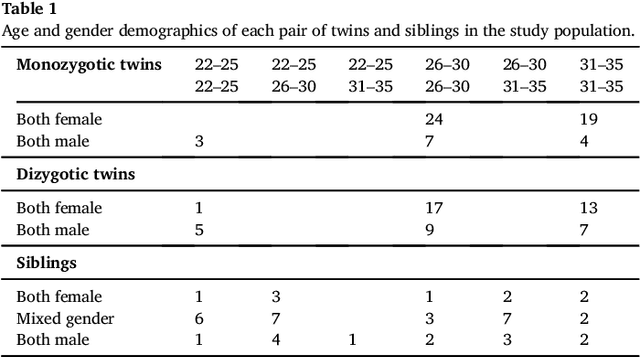
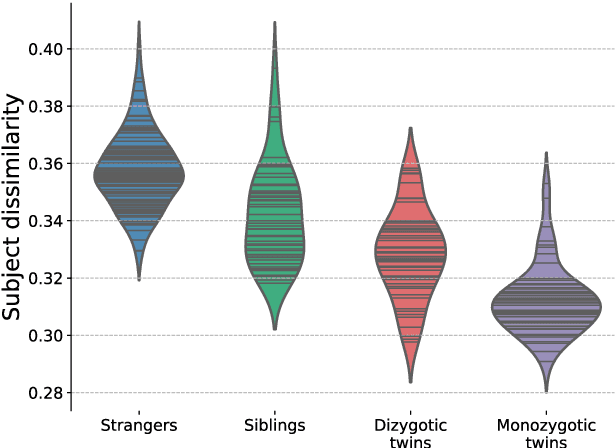
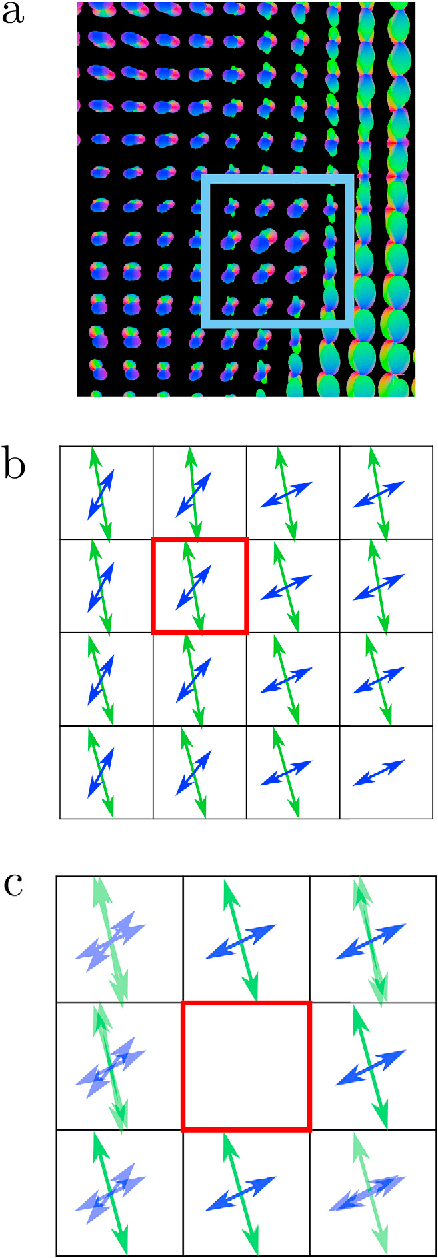
We present a method to discover differences between populations with respect to the spatial coherence of their oriented white matter microstructure in arbitrarily shaped white matter regions. This method is applied to diffusion MRI scans of a subset of the Human Connectome Project dataset: 57 pairs of monozygotic and 52 pairs of dizygotic twins. After controlling for morphological similarity between twins, we identify 3.7% of all white matter as being associated with genetic similarity (35.1k voxels, $p < 10^{-4}$, false discovery rate 1.5%), 75% of which spatially clusters into twenty-two contiguous white matter regions. Furthermore, we show that the orientation similarity within these regions generalizes to a subset of 47 pairs of non-twin siblings, and show that these siblings are on average as similar as dizygotic twins. The regions are located in deep white matter including the superior longitudinal fasciculus, the optic radiations, the middle cerebellar peduncle, the corticospinal tract, and within the anterior temporal lobe, as well as the cerebellum, brain stem, and amygdalae. These results extend previous work using undirected fractional anisotrophy for measuring putative heritable influences in white matter. Our multidirectional extension better accounts for crossing fiber connections within voxels. This bottom up approach has at its basis a novel measurement of coherence within neighboring voxel dyads between subjects, and avoids some of the fundamental ambiguities encountered with tractographic approaches to white matter analysis that estimate global connectivity.
Riemannian-geometry-based modeling and clustering of network-wide non-stationary time series: The brain-network case
Jan 26, 2017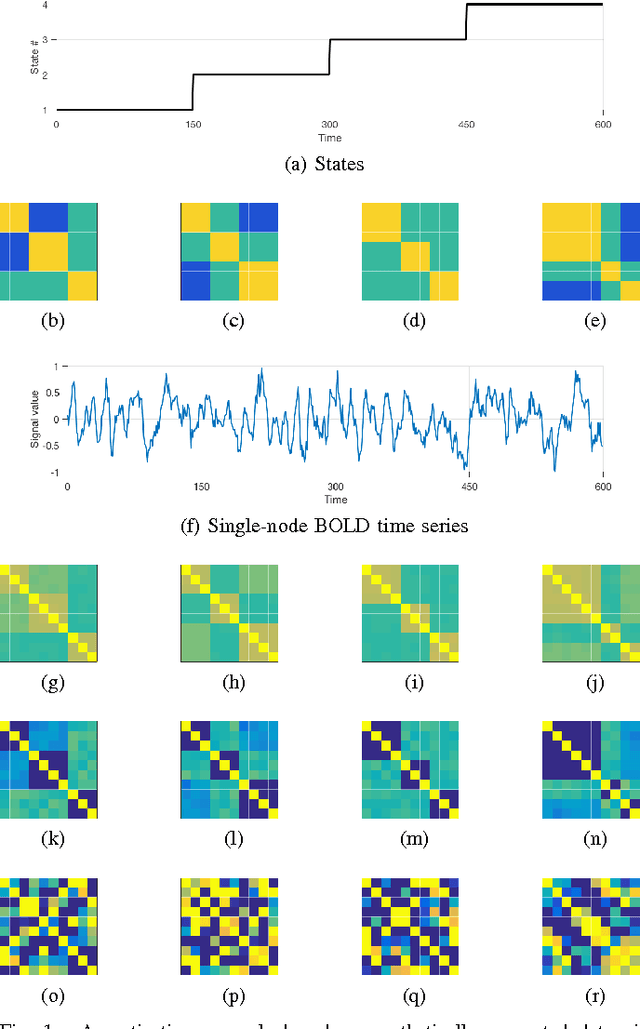
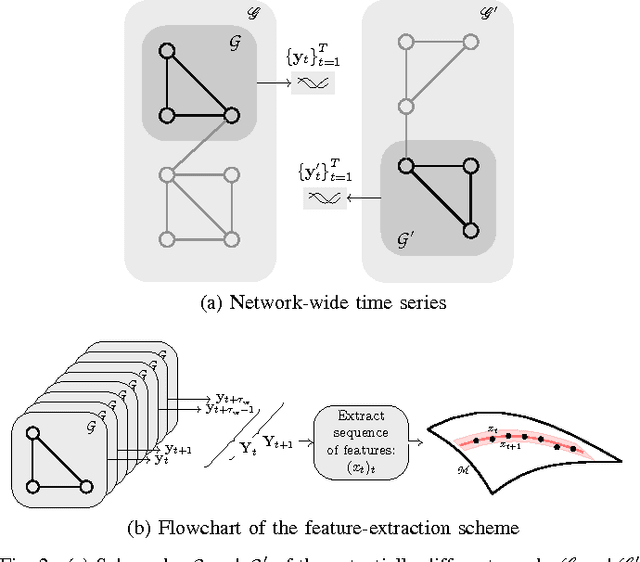
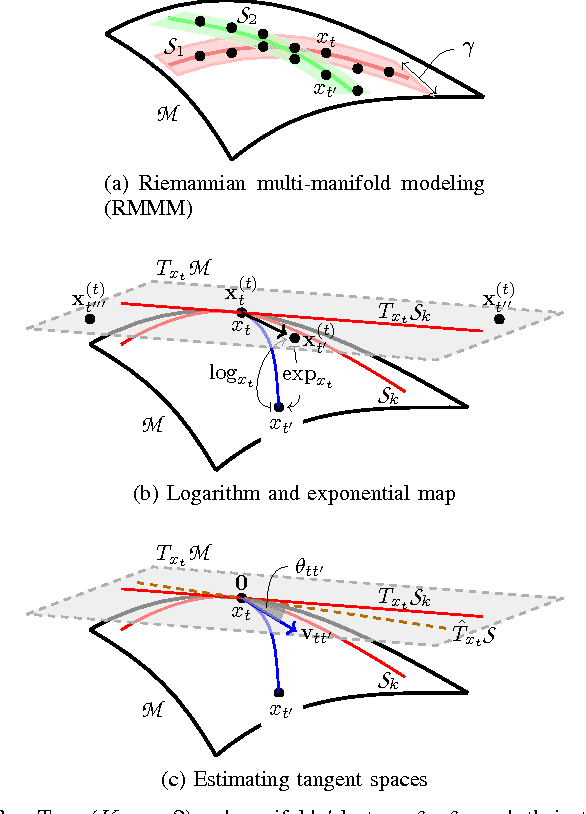
This paper advocates Riemannian multi-manifold modeling in the context of network-wide non-stationary time-series analysis. Time-series data, collected sequentially over time and across a network, yield features which are viewed as points in or close to a union of multiple submanifolds of a Riemannian manifold, and distinguishing disparate time series amounts to clustering multiple Riemannian submanifolds. To support the claim that exploiting the latent Riemannian geometry behind many statistical features of time series is beneficial to learning from network data, this paper focuses on brain networks and puts forth two feature-generation schemes for network-wide dynamic time series. The first is motivated by Granger-causality arguments and uses an auto-regressive moving average model to map low-rank linear vector subspaces, spanned by column vectors of appropriately defined observability matrices, to points into the Grassmann manifold. The second utilizes (non-linear) dependencies among network nodes by introducing kernel-based partial correlations to generate points in the manifold of positive-definite matrices. Capitilizing on recently developed research on clustering Riemannian submanifolds, an algorithm is provided for distinguishing time series based on their geometrical properties, revealed within Riemannian feature spaces. Extensive numerical tests demonstrate that the proposed framework outperforms classical and state-of-the-art techniques in clustering brain-network states/structures hidden beneath synthetic fMRI time series and brain-activity signals generated from real brain-network structural connectivity matrices.
On the geometric structure of fMRI searchlight-based information maps
Oct 23, 2012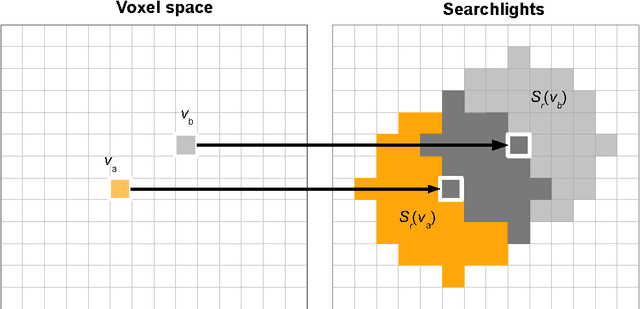
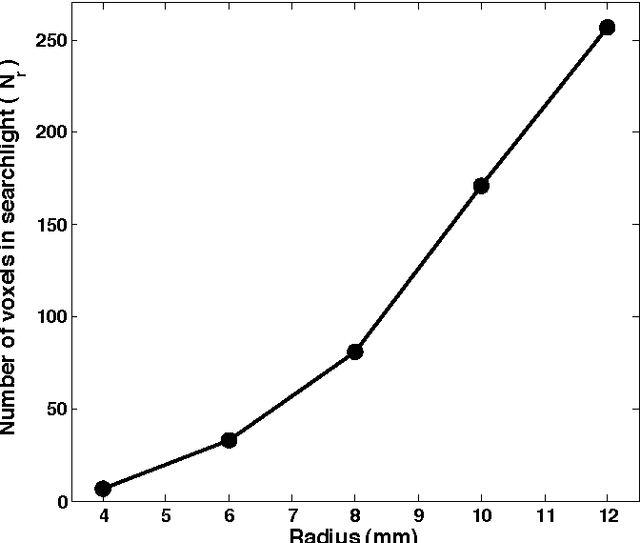
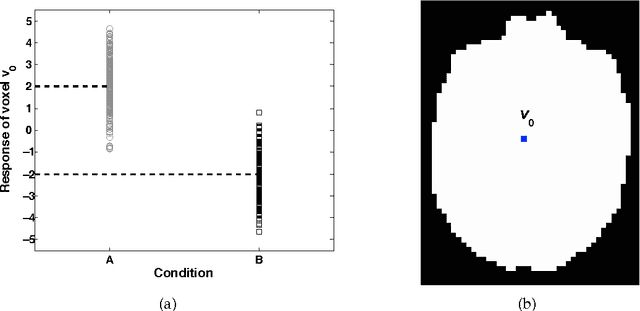
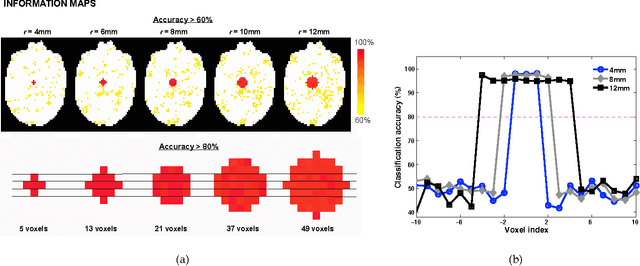
Information mapping is a popular application of Multivoxel Pattern Analysis (MVPA) to fMRI. Information maps are constructed using the so called searchlight method, where the spherical multivoxel neighborhood of every voxel (i.e., a searchlight) in the brain is evaluated for the presence of task-relevant response patterns. Despite their widespread use, information maps present several challenges for interpretation. One such challenge has to do with inferring the size and shape of a multivoxel pattern from its signature on the information map. To address this issue, we formally examined the geometric basis of this mapping relationship. Based on geometric considerations, we show how and why small patterns (i.e., having smaller spatial extents) can produce a larger signature on the information map as compared to large patterns, independent of the size of the searchlight radius. Furthermore, we show that the number of informative searchlights over the brain increase as a function of searchlight radius, even in the complete absence of any multivariate response patterns. These properties are unrelated to the statistical capabilities of the pattern-analysis algorithms used but are obligatory geometric properties arising from using the searchlight procedure.