 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMBisect: Breaking Barriers in Bug Bisection with A Comparative Analysis Pipeline
Oct 30, 2025
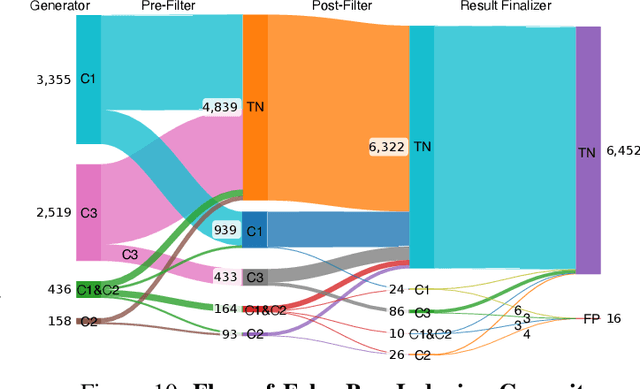
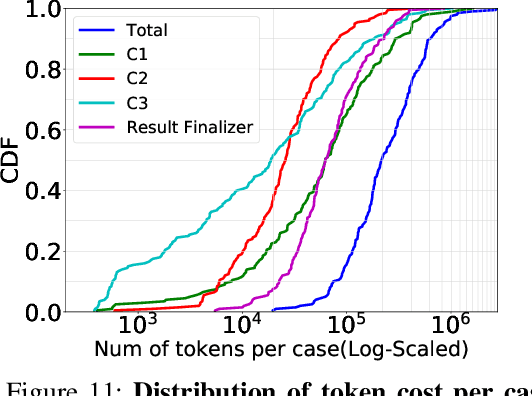
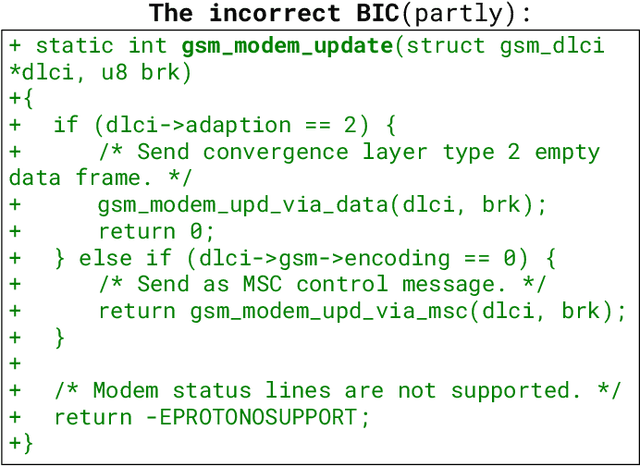
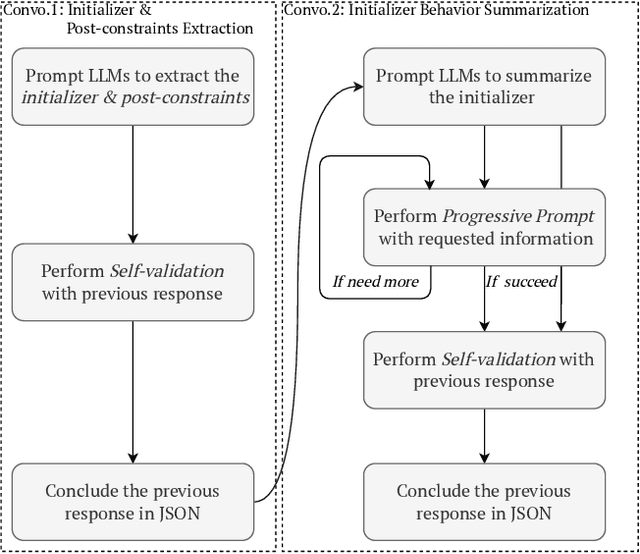
Bug bisection has been an important security task that aims to understand the range of software versions impacted by a bug, i.e., identifying the commit that introduced the bug. However, traditional patch-based bisection methods are faced with several significant barriers: For example, they assume that the bug-inducing commit (BIC) and the patch commit modify the same functions, which is not always true. They often rely solely on code changes, while the commit message frequently contains a wealth of vulnerability-related information. They are also based on simple heuristics (e.g., assuming the BIC initializes lines deleted in the patch) and lack any logical analysis of the vulnerability. In this paper, we make the observation that Large Language Models (LLMs) are well-positioned to break the barriers of existing solutions, e.g., comprehend both textual data and code in patches and commits. Unlike previous BIC identification approaches, which yield poor results, we propose a comprehensive multi-stage pipeline that leverages LLMs to: (1) fully utilize patch information, (2) compare multiple candidate commits in context, and (3) progressively narrow down the candidates through a series of down-selection steps. In our evaluation, we demonstrate that our approach achieves significantly better accuracy than the state-of-the-art solution by more than 38\%. Our results further confirm that the comprehensive multi-stage pipeline is essential, as it improves accuracy by 60\% over a baseline LLM-based bisection method.
The Hitchhiker's Guide to Program Analysis, Part II: Deep Thoughts by LLMs
Apr 16, 2025Static analysis is a cornerstone for software vulnerability detection, yet it often struggles with the classic precision-scalability trade-off. In practice, such tools often produce high false positive rates, particularly in large codebases like the Linux kernel. This imprecision can arise from simplified vulnerability modeling and over-approximation of path and data constraints. While large language models (LLMs) show promise in code understanding, their naive application to program analysis yields unreliable results due to inherent reasoning limitations. We introduce BugLens, a post-refinement framework that significantly improves static analysis precision. BugLens guides an LLM to follow traditional analysis steps by assessing buggy code patterns for security impact and validating the constraints associated with static warnings. Evaluated on real-world Linux kernel bugs, BugLens raises precision from 0.10 (raw) and 0.50 (semi-automated refinement) to 0.72, substantially reducing false positives and revealing four previously unreported vulnerabilities. Our results suggest that a structured LLM-based workflow can meaningfully enhance the effectiveness of static analysis tools.
The Hitchhiker's Guide to Program Analysis: A Journey with Large Language Models
Aug 01, 2023


Static analysis is a widely used technique in software engineering for identifying and mitigating bugs. However, a significant hurdle lies in achieving a delicate balance between precision and scalability. Large Language Models (LLMs) offer a promising alternative, as recent advances demonstrate remarkable capabilities in comprehending, generating, and even debugging code. Yet, the logic of bugs can be complex and require sophisticated reasoning and a large analysis scope spanning multiple functions. Therefore, at this point, LLMs are better used in an assistive role to complement static analysis. In this paper, we take a deep dive into the open space of LLM-assisted static analysis, using use-before-initialization (UBI) bugs as a case study. To this end, we develop LLift, a fully automated agent that interfaces with both a static analysis tool and an LLM. By carefully designing the agent and the prompts, we are able to overcome a number of challenges, including bug-specific modeling, the large problem scope, the non-deterministic nature of LLMs, etc. Tested in a real-world scenario analyzing nearly a thousand potential UBI bugs produced by static analysis, LLift demonstrates an extremely potent capability, showcasing a high precision (50%) and recall rate (100%). It even identified 13 previously unknown UBI bugs in the Linux kernel. This research paves the way for new opportunities and methodologies in the use of LLMs for bug discovery in extensive, real-world datasets.
A4 : Evading Learning-based Adblockers
Jan 29, 2020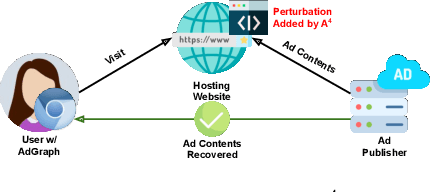
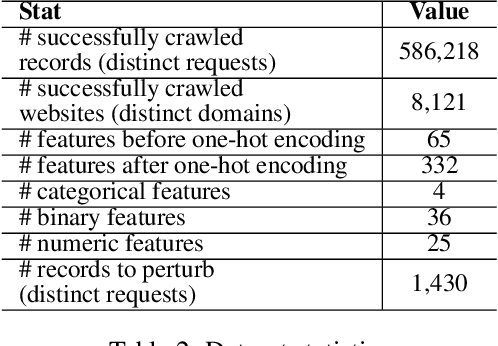
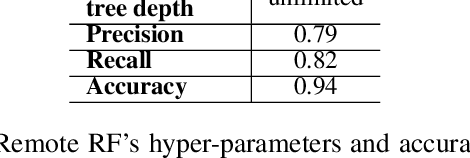
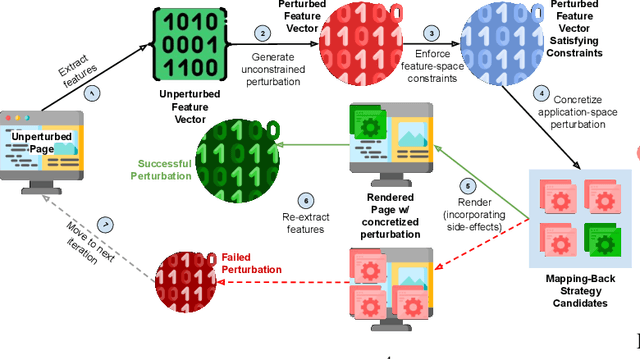
Efforts by online ad publishers to circumvent traditional ad blockers towards regaining fiduciary benefits, have been demonstrably successful. As a result, there have recently emerged a set of adblockers that apply machine learning instead of manually curated rules and have been shown to be more robust in blocking ads on websites including social media sites such as Facebook. Among these, AdGraph is arguably the state-of-the-art learning-based adblocker. In this paper, we develop A4, a tool that intelligently crafts adversarial samples of ads to evade AdGraph. Unlike the popular research on adversarial samples against images or videos that are considered less- to un-restricted, the samples that A4 generates preserve application semantics of the web page, or are actionable. Through several experiments we show that A4 can bypass AdGraph about 60% of the time, which surpasses the state-of-the-art attack by a significant margin of 84.3%; in addition, changes to the visual layout of the web page due to these perturbations are imperceptible. We envision the algorithmic framework proposed in A4 is also promising in improving adversarial attacks against other learning-based web applications with similar requirements.
AdGraph: A Machine Learning Approach to Automatic and Effective Adblocking
May 22, 2018
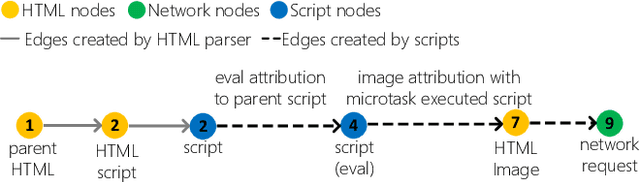
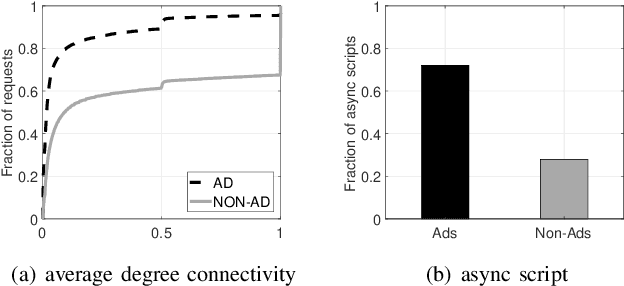
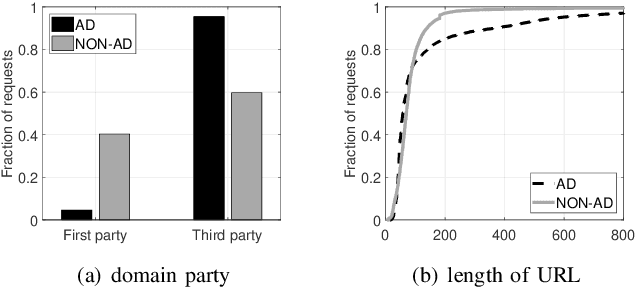
Filter lists are widely deployed by adblockers to block ads and other forms of undesirable content in web browsers. However, these filter lists are manually curated based on informal crowdsourced feedback, which brings with it a significant number of maintenance challenges. To address these challenges, we propose a machine learning approach for automatic and effective adblocking called AdGraph. Our approach relies on information obtained from multiple layers of the web stack (HTML, HTTP, and JavaScript) to train a machine learning classifier to block ads and trackers. Our evaluation on Alexa top-10K websites shows that AdGraph automatically and effectively blocks ads and trackers with 97.7% accuracy. Our manual analysis shows that AdGraph has better recall than filter lists, it blocks 16% more ads and trackers with 65% accuracy. We also show that AdGraph is fairly robust against adversarial obfuscation by publishers and advertisers that bypass filter lists.
Behavior Query Discovery in System-Generated Temporal Graphs
Nov 19, 2015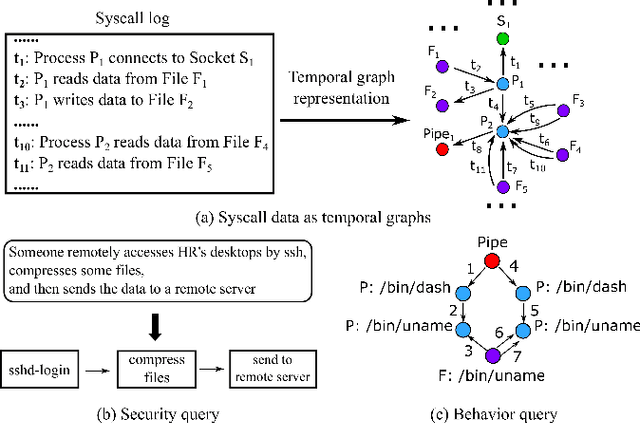
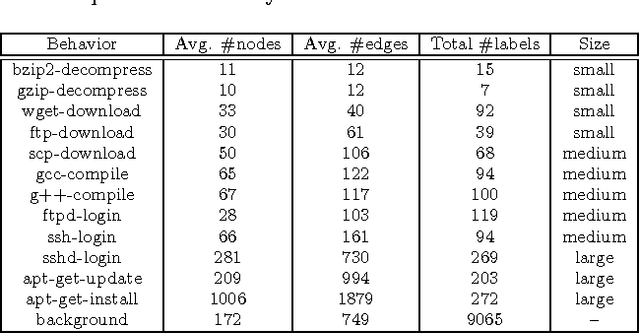
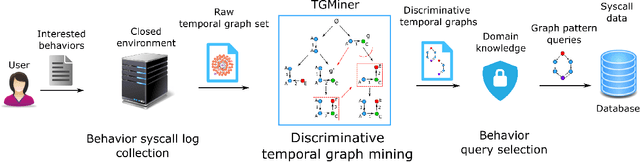
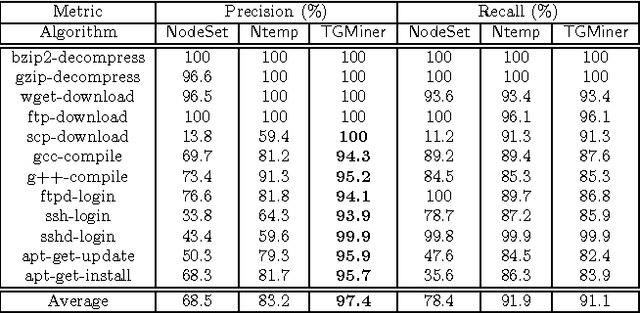
Computer system monitoring generates huge amounts of logs that record the interaction of system entities. How to query such data to better understand system behaviors and identify potential system risks and malicious behaviors becomes a challenging task for system administrators due to the dynamics and heterogeneity of the data. System monitoring data are essentially heterogeneous temporal graphs with nodes being system entities and edges being their interactions over time. Given the complexity of such graphs, it becomes time-consuming for system administrators to manually formulate useful queries in order to examine abnormal activities, attacks, and vulnerabilities in computer systems. In this work, we investigate how to query temporal graphs and treat query formulation as a discriminative temporal graph pattern mining problem. We introduce TGMiner to mine discriminative patterns from system logs, and these patterns can be taken as templates for building more complex queries. TGMiner leverages temporal information in graphs to prune graph patterns that share similar growth trend without compromising pattern quality. Experimental results on real system data show that TGMiner is 6-32 times faster than baseline methods. The discovered patterns were verified by system experts; they achieved high precision (97%) and recall (91%).