 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Federated Anomaly Detection for Multivariate Time Series Data
May 09, 2022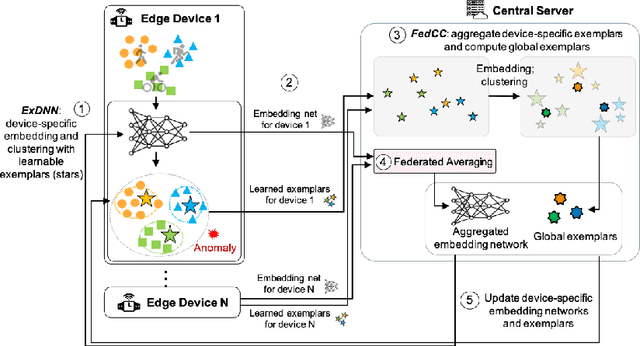
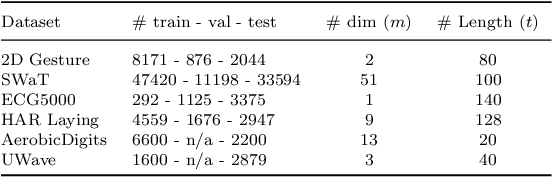
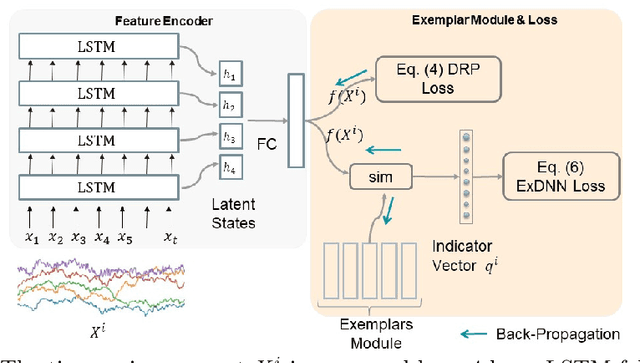
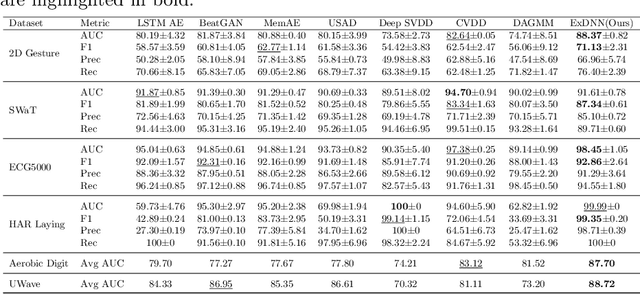
Despite the fact that many anomaly detection approaches have been developed for multivariate time series data, limited effort has been made on federated settings in which multivariate time series data are heterogeneously distributed among different edge devices while data sharing is prohibited. In this paper, we investigate the problem of federated unsupervised anomaly detection and present a Federated Exemplar-based Deep Neural Network (Fed-ExDNN) to conduct anomaly detection for multivariate time series data on different edge devices. Specifically, we first design an Exemplar-based Deep Neural network (ExDNN) to learn local time series representations based on their compatibility with an exemplar module which consists of hidden parameters learned to capture varieties of normal patterns on each edge device. Next, a constrained clustering mechanism (FedCC) is employed on the centralized server to align and aggregate the parameters of different local exemplar modules to obtain a unified global exemplar module. Finally, the global exemplar module is deployed together with a shared feature encoder to each edge device and anomaly detection is conducted by examining the compatibility of testing data to the exemplar module. Fed-ExDNN captures local normal time series patterns with ExDNN and aggregates these patterns by FedCC, and thus can handle the heterogeneous data distributed over different edge devices simultaneously. Thoroughly empirical studies on six public datasets show that ExDNN and Fed-ExDNN can outperform state-of-the-art anomaly detection algorithms and federated learning techniques.
Do Multi-Lingual Pre-trained Language Models Reveal Consistent Token Attributions in Different Languages?
Dec 23, 2021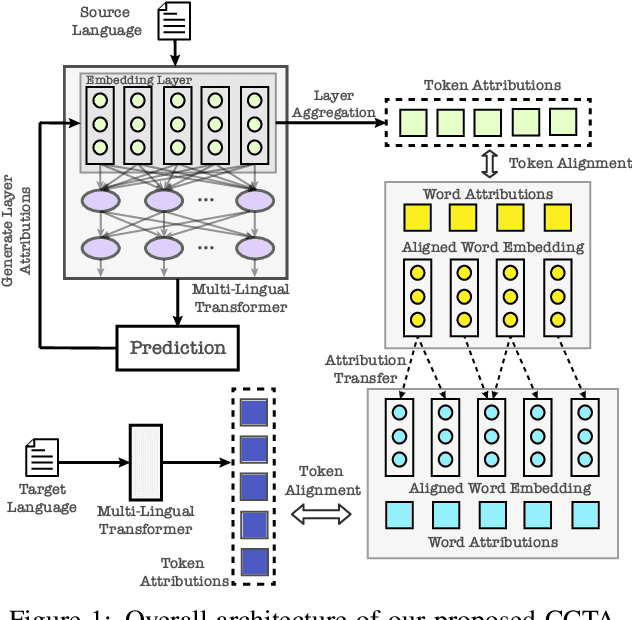
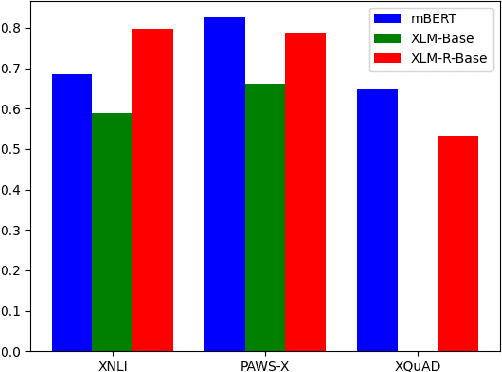
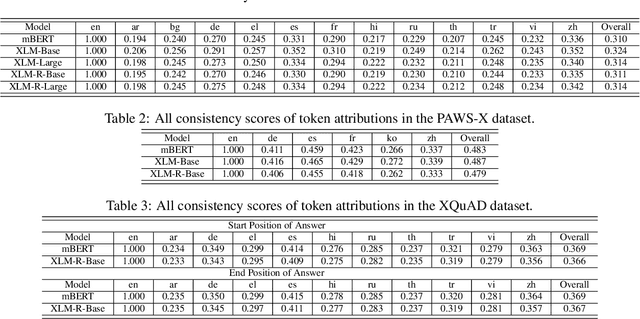
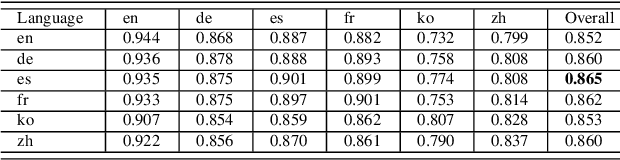
During the past several years, a surge of multi-lingual Pre-trained Language Models (PLMs) has been proposed to achieve state-of-the-art performance in many cross-lingual downstream tasks. However, the understanding of why multi-lingual PLMs perform well is still an open domain. For example, it is unclear whether multi-Lingual PLMs reveal consistent token attributions in different languages. To address this, in this paper, we propose a Cross-lingual Consistency of Token Attributions (CCTA) evaluation framework. Extensive experiments in three downstream tasks demonstrate that multi-lingual PLMs assign significantly different attributions to multi-lingual synonyms. Moreover, we have the following observations: 1) the Spanish achieves the most consistent token attributions in different languages when it is used for training PLMs; 2) the consistency of token attributions strongly correlates with performance in downstream tasks.
Zero-Shot Cross-Lingual Machine Reading Comprehension via Inter-Sentence Dependency Graph
Dec 09, 2021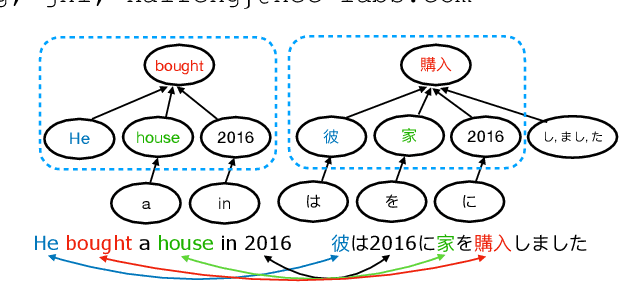
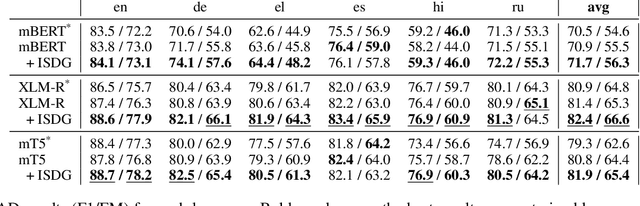
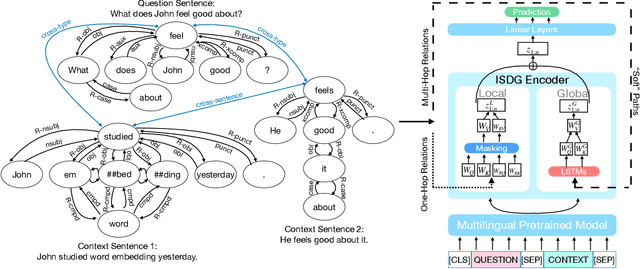
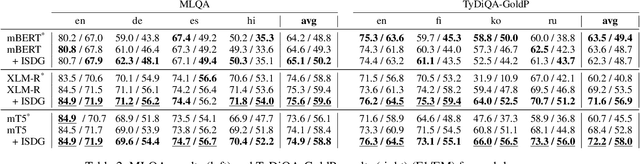
We target the task of cross-lingual Machine Reading Comprehension (MRC) in the direct zero-shot setting, by incorporating syntactic features from Universal Dependencies (UD), and the key features we use are the syntactic relations within each sentence. While previous work has demonstrated effective syntax-guided MRC models, we propose to adopt the inter-sentence syntactic relations, in addition to the rudimentary intra-sentence relations, to further utilize the syntactic dependencies in the multi-sentence input of the MRC task. In our approach, we build the Inter-Sentence Dependency Graph (ISDG) connecting dependency trees to form global syntactic relations across sentences. We then propose the ISDG encoder that encodes the global dependency graph, addressing the inter-sentence relations via both one-hop and multi-hop dependency paths explicitly. Experiments on three multilingual MRC datasets (XQuAD, MLQA, TyDiQA-GoldP) show that our encoder that is only trained on English is able to improve the zero-shot performance on all 14 test sets covering 8 languages, with up to 3.8 F1 / 5.2 EM improvement on-average, and 5.2 F1 / 11.2 EM on certain languages. Further analysis shows the improvement can be attributed to the attention on the cross-linguistically consistent syntactic path.
Merlion: A Machine Learning Library for Time Series
Sep 20, 2021
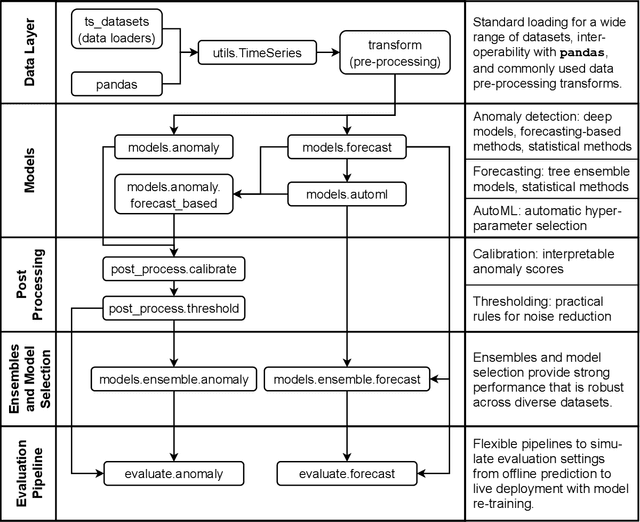

We introduce Merlion, an open-source machine learning library for time series. It features a unified interface for many commonly used models and datasets for anomaly detection and forecasting on both univariate and multivariate time series, along with standard pre/post-processing layers. It has several modules to improve ease-of-use, including visualization, anomaly score calibration to improve interpetability, AutoML for hyperparameter tuning and model selection, and model ensembling. Merlion also provides a unique evaluation framework that simulates the live deployment and re-training of a model in production. This library aims to provide engineers and researchers a one-stop solution to rapidly develop models for their specific time series needs and benchmark them across multiple time series datasets. In this technical report, we highlight Merlion's architecture and major functionalities, and we report benchmark numbers across different baseline models and ensembles.
Unsupervised Document Embedding via Contrastive Augmentation
Mar 26, 2021
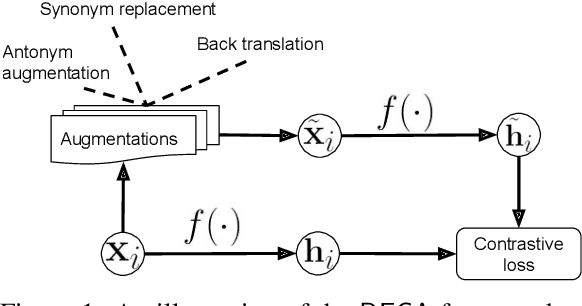

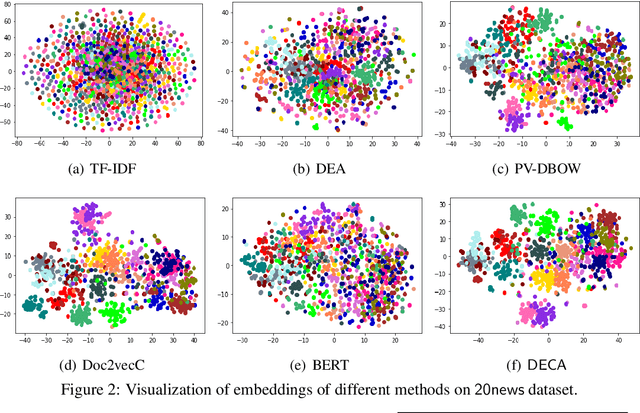
We present a contrasting learning approach with data augmentation techniques to learn document representations in an unsupervised manner. Inspired by recent contrastive self-supervised learning algorithms used for image and NLP pretraining, we hypothesize that high-quality document embedding should be invariant to diverse paraphrases that preserve the semantics of the original document. With different backbones and contrastive learning frameworks, our study reveals the enormous benefits of contrastive augmentation for document representation learning with two additional insights: 1) including data augmentation in a contrastive way can substantially improve the embedding quality in unsupervised document representation learning, and 2) in general, stochastic augmentations generated by simple word-level manipulation work much better than sentence-level and document-level ones. We plug our method into a classifier and compare it with a broad range of baseline methods on six benchmark datasets. Our method can decrease the classification error rate by up to 6.4% over the SOTA approaches on the document classification task, matching or even surpassing fully-supervised methods.
Dynamic Gaussian Mixture based Deep Generative Model For Robust Forecasting on Sparse Multivariate Time Series
Mar 03, 2021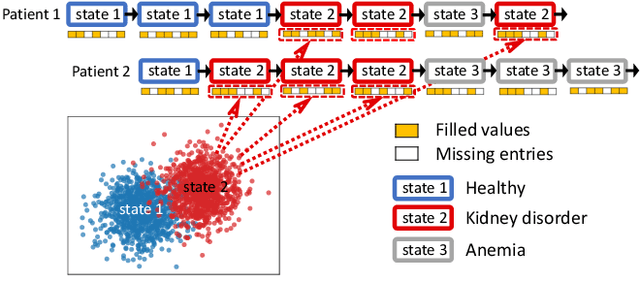
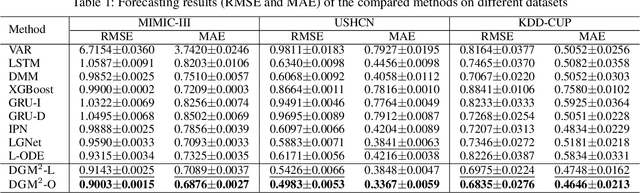
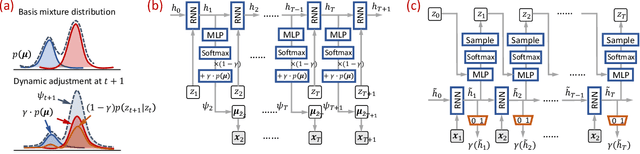
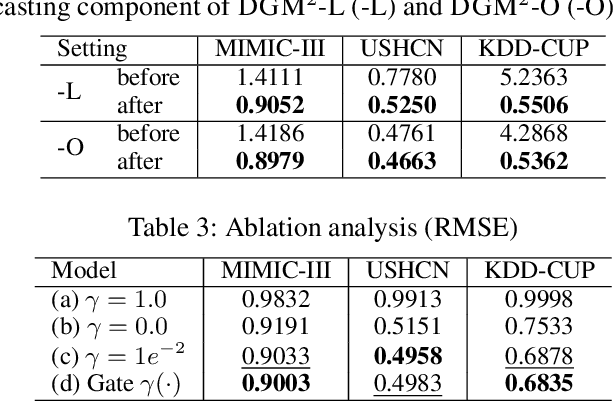
Forecasting on sparse multivariate time series (MTS) aims to model the predictors of future values of time series given their incomplete past, which is important for many emerging applications. However, most existing methods process MTS's individually, and do not leverage the dynamic distributions underlying the MTS's, leading to sub-optimal results when the sparsity is high. To address this challenge, we propose a novel generative model, which tracks the transition of latent clusters, instead of isolated feature representations, to achieve robust modeling. It is characterized by a newly designed dynamic Gaussian mixture distribution, which captures the dynamics of clustering structures, and is used for emitting timeseries. The generative model is parameterized by neural networks. A structured inference network is also designed for enabling inductive analysis. A gating mechanism is further introduced to dynamically tune the Gaussian mixture distributions. Extensive experimental results on a variety of real-life datasets demonstrate the effectiveness of our method.
Learning to Drop: Robust Graph Neural Network via Topological Denoising
Nov 13, 2020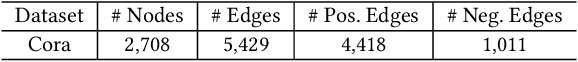

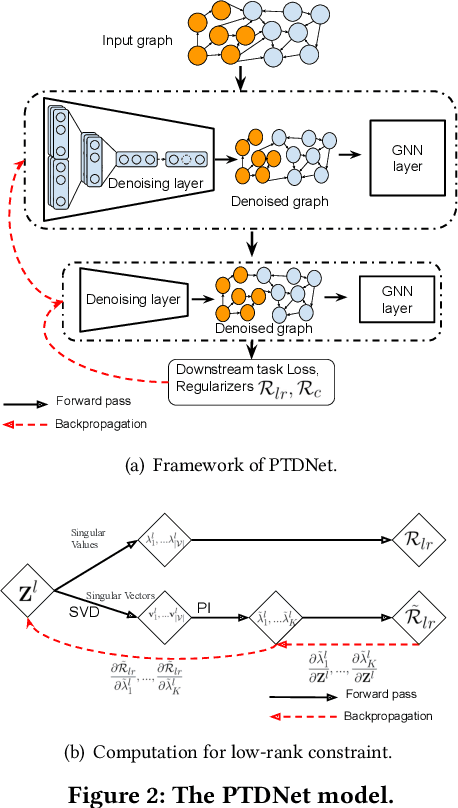
Graph Neural Networks (GNNs) have shown to be powerful tools for graph analytics. The key idea is to recursively propagate and aggregate information along edges of the given graph. Despite their success, however, the existing GNNs are usually sensitive to the quality of the input graph. Real-world graphs are often noisy and contain task-irrelevant edges, which may lead to suboptimal generalization performance in the learned GNN models. In this paper, we propose PTDNet, a parameterized topological denoising network, to improve the robustness and generalization performance of GNNs by learning to drop task-irrelevant edges. PTDNet prunes task-irrelevant edges by penalizing the number of edges in the sparsified graph with parameterized networks. To take into consideration of the topology of the entire graph, the nuclear norm regularization is applied to impose the low-rank constraint on the resulting sparsified graph for better generalization. PTDNet can be used as a key component in GNN models to improve their performances on various tasks, such as node classification and link prediction. Experimental studies on both synthetic and benchmark datasets show that PTDNet can improve the performance of GNNs significantly and the performance gain becomes larger for more noisy datasets.
Parameterized Explainer for Graph Neural Network
Nov 09, 2020

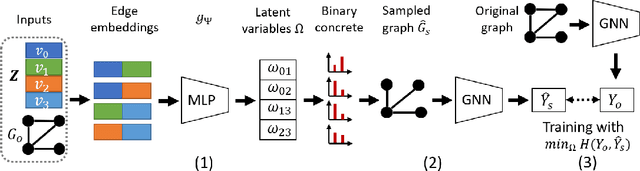
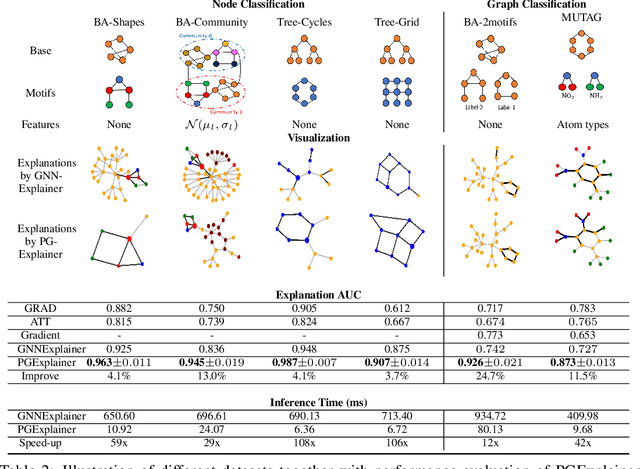
Despite recent progress in Graph Neural Networks (GNNs), explaining predictions made by GNNs remains a challenging open problem. The leading method independently addresses the local explanations (i.e., important subgraph structure and node features) to interpret why a GNN model makes the prediction for a single instance, e.g. a node or a graph. As a result, the explanation generated is painstakingly customized for each instance. The unique explanation interpreting each instance independently is not sufficient to provide a global understanding of the learned GNN model, leading to a lack of generalizability and hindering it from being used in the inductive setting. Besides, as it is designed for explaining a single instance, it is challenging to explain a set of instances naturally (e.g., graphs of a given class). In this study, we address these key challenges and propose PGExplainer, a parameterized explainer for GNNs. PGExplainer adopts a deep neural network to parameterize the generation process of explanations, which enables PGExplainer a natural approach to explaining multiple instances collectively. Compared to the existing work, PGExplainer has better generalization ability and can be utilized in an inductive setting easily. Experiments on both synthetic and real-life datasets show highly competitive performance with up to 24.7\% relative improvement in AUC on explaining graph classification over the leading baseline.
T$^2$-Net: A Semi-supervised Deep Model for Turbulence Forecasting
Oct 26, 2020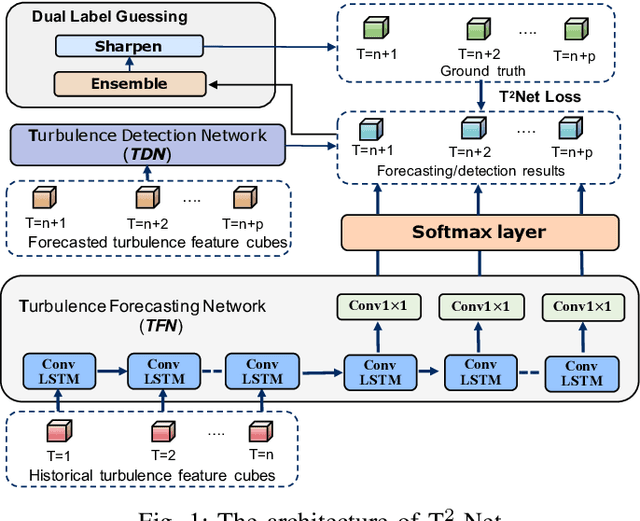
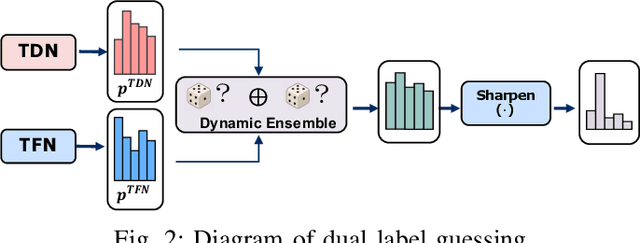
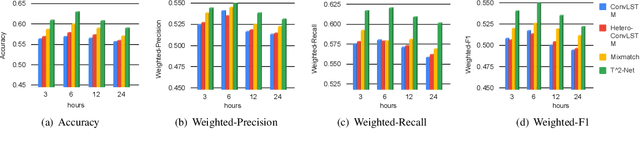
Accurate air turbulence forecasting can help airlines avoid hazardous turbulence, guide the routes that keep passengers safe, maximize efficiency, and reduce costs. Traditional turbulence forecasting approaches heavily rely on painstakingly customized turbulence indexes, which are less effective in dynamic and complex weather conditions. The recent availability of high-resolution weather data and turbulence records allows more accurate forecasting of the turbulence in a data-driven way. However, it is a non-trivial task for developing a machine learning based turbulence forecasting system due to two challenges: (1) Complex spatio-temporal correlations, turbulence is caused by air movement with complex spatio-temporal patterns, (2) Label scarcity, very limited turbulence labels can be obtained. To this end, in this paper, we develop a unified semi-supervised framework, T$^2$-Net, to address the above challenges. Specifically, we first build an encoder-decoder paradigm based on the convolutional LSTM to model the spatio-temporal correlations. Then, to tackle the label scarcity problem, we propose a novel Dual Label Guessing method to take advantage of massive unlabeled turbulence data. It integrates complementary signals from the main Turbulence Forecasting task and the auxiliary Turbulence Detection task to generate pseudo-labels, which are dynamically utilized as additional training data. Finally, extensive experimental results on a real-world turbulence dataset validate the superiority of our method on turbulence forecasting.
Asymmetrical Hierarchical Networks with Attentive Interactions for Interpretable Review-Based Recommendation
Dec 18, 2019
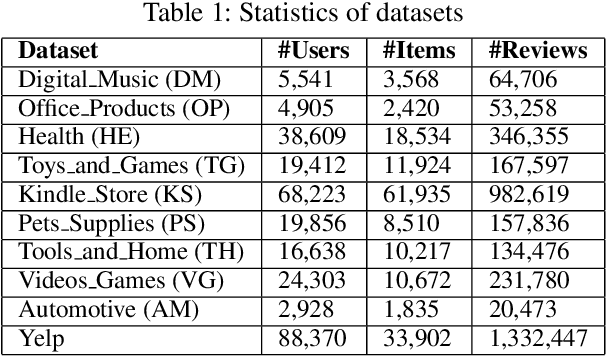
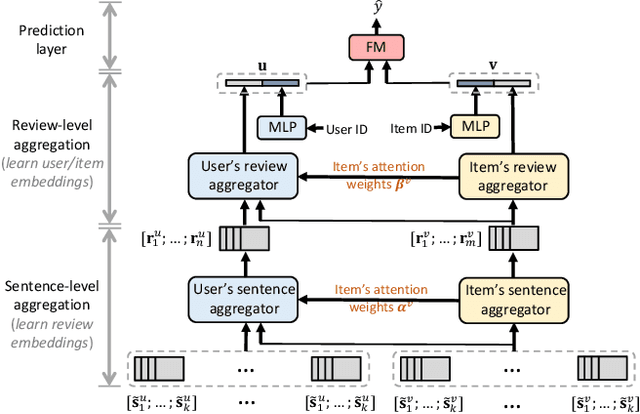
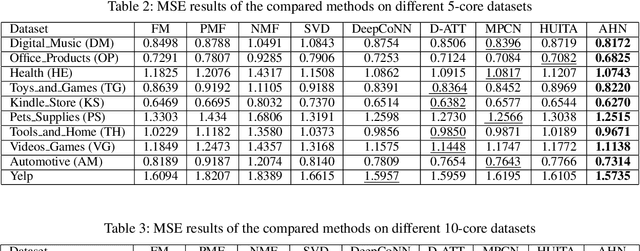
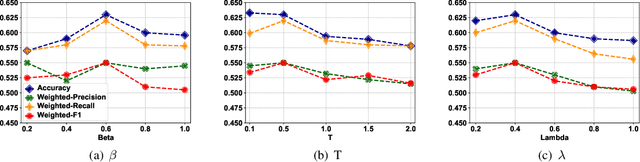
Recently, recommender systems have been able to emit substantially improved recommendations by leveraging user-provided reviews. Existing methods typically merge all reviews of a given user or item into a long document, and then process user and item documents in the same manner. In practice, however, these two sets of reviews are notably different: users' reviews reflect a variety of items that they have bought and are hence very heterogeneous in their topics, while an item's reviews pertain only to that single item and are thus topically homogeneous. In this work, we develop a novel neural network model that properly accounts for this important difference by means of asymmetric attentive modules. The user module learns to attend to only those signals that are relevant with respect to the target item, whereas the item module learns to extract the most salient contents with regard to properties of the item. Our multi-hierarchical paradigm accounts for the fact that neither are all reviews equally useful, nor are all sentences within each review equally pertinent. Extensive experimental results on a variety of real datasets demonstrate the effectiveness of our method.