 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Multi-Lingual Pre-trained Language Models Reveal Consistent Token Attributions in Different Languages?
Paper and Code
Dec 23, 2021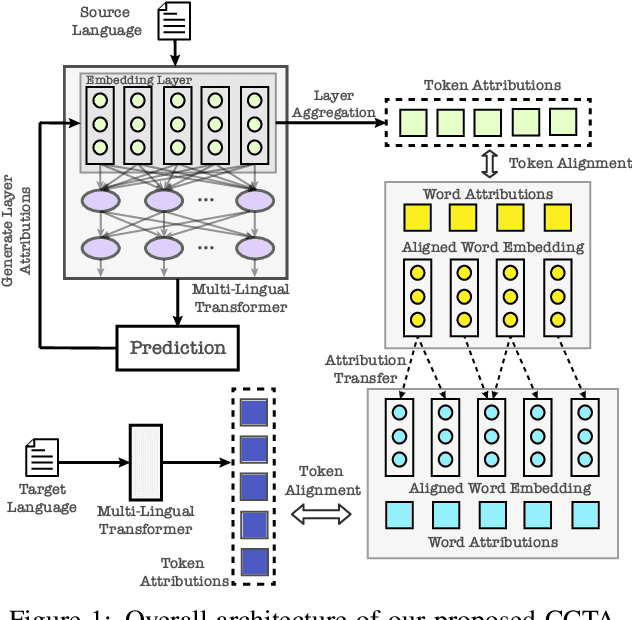
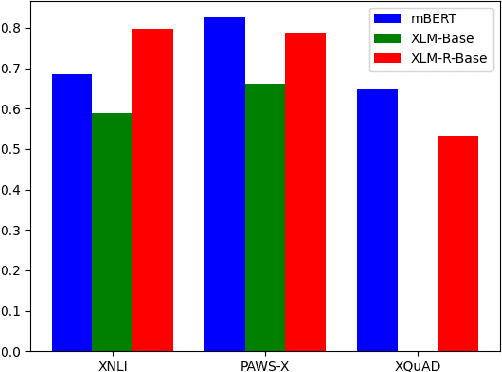
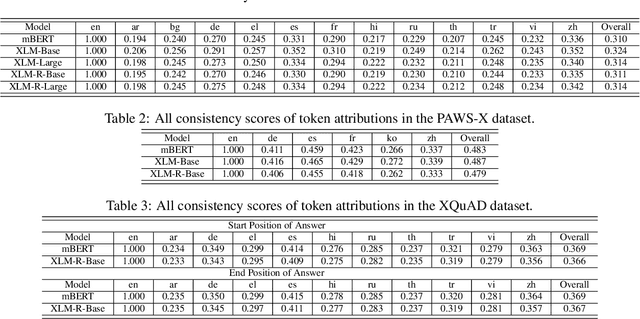
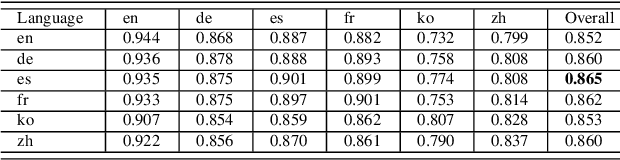
During the past several years, a surge of multi-lingual Pre-trained Language Models (PLMs) has been proposed to achieve state-of-the-art performance in many cross-lingual downstream tasks. However, the understanding of why multi-lingual PLMs perform well is still an open domain. For example, it is unclear whether multi-Lingual PLMs reveal consistent token attributions in different languages. To address this, in this paper, we propose a Cross-lingual Consistency of Token Attributions (CCTA) evaluation framework. Extensive experiments in three downstream tasks demonstrate that multi-lingual PLMs assign significantly different attributions to multi-lingual synonyms. Moreover, we have the following observations: 1) the Spanish achieves the most consistent token attributions in different languages when it is used for training PLMs; 2) the consistency of token attributions strongly correlates with performance in downstream tasks.