 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRECITYGEN -- Interactive and Generative Participatory Urban Design Tool with Latent Diffusion and Segment Anything
Feb 04, 2026Urban design profoundly impacts public spaces and community engagement. Traditional top-down methods often overlook public input, creating a gap in design aspirations and reality. Recent advancements in digital tools, like City Information Modelling and augmented reality, have enabled a more participatory process involving more stakeholders in urban design. Further, deep learning and latent diffusion models have lowered barriers for design generation, providing even more opportunities for participatory urban design. Combining state-of-the-art latent diffusion models with interactive semantic segmentation, we propose RECITYGEN, a novel tool that allows users to interactively create variational street view images of urban environments using text prompts. In a pilot project in Beijing, users employed RECITYGEN to suggest improvements for an ongoing Urban Regeneration project. Despite some limitations, RECITYGEN has shown significant potential in aligning with public preferences, indicating a shift towards more dynamic and inclusive urban planning methods. The source code for the project can be found at RECITYGEN GitHub.
No Global Plan in Chain-of-Thought: Uncover the Latent Planning Horizon of LLMs
Feb 02, 2026This work stems from prior complementary observations on the dynamics of Chain-of-Thought (CoT): Large Language Models (LLMs) is shown latent planning of subsequent reasoning prior to CoT emergence, thereby diminishing the significance of explicit CoT; whereas CoT remains critical for tasks requiring multi-step reasoning. To deepen the understanding between LLM's internal states and its verbalized reasoning trajectories, we investigate the latent planning strength of LLMs, through our probing method, Tele-Lens, applying to hidden states across diverse task domains. Our empirical results indicate that LLMs exhibit a myopic horizon, primarily conducting incremental transitions without precise global planning. Leveraging this characteristic, we propose a hypothesis on enhancing uncertainty estimation of CoT, which we validate that a small subset of CoT positions can effectively represent the uncertainty of the entire path. We further underscore the significance of exploiting CoT dynamics, and demonstrate that automatic recognition of CoT bypass can be achieved without performance degradation. Our code, data and models are released at https://github.com/lxucs/tele-lens.
ComoRAG: A Cognitive-Inspired Memory-Organized RAG for Stateful Long Narrative Reasoning
Aug 14, 2025



Narrative comprehension on long stories and novels has been a challenging domain attributed to their intricate plotlines and entangled, often evolving relations among characters and entities. Given the LLM's diminished reasoning over extended context and high computational cost, retrieval-based approaches remain a pivotal role in practice. However, traditional RAG methods can fall short due to their stateless, single-step retrieval process, which often overlooks the dynamic nature of capturing interconnected relations within long-range context. In this work, we propose ComoRAG, holding the principle that narrative reasoning is not a one-shot process, but a dynamic, evolving interplay between new evidence acquisition and past knowledge consolidation, analogous to human cognition when reasoning with memory-related signals in the brain. Specifically, when encountering a reasoning impasse, ComoRAG undergoes iterative reasoning cycles while interacting with a dynamic memory workspace. In each cycle, it generates probing queries to devise new exploratory paths, then integrates the retrieved evidence of new aspects into a global memory pool, thereby supporting the emergence of a coherent context for the query resolution. Across four challenging long-context narrative benchmarks (200K+ tokens), ComoRAG outperforms strong RAG baselines with consistent relative gains up to 11% compared to the strongest baseline. Further analysis reveals that ComoRAG is particularly advantageous for complex queries requiring global comprehension, offering a principled, cognitively motivated paradigm for retrieval-based long context comprehension towards stateful reasoning. Our code is publicly released at https://github.com/EternityJune25/ComoRAG
Dense Retrievers Can Fail on Simple Queries: Revealing The Granularity Dilemma of Embeddings
Jun 10, 2025



This work focuses on an observed limitation of text encoders: embeddings may not be able to recognize fine-grained entities or events within the semantics, resulting in failed dense retrieval on even simple cases. To examine such behaviors, we first introduce a new evaluation dataset in Chinese, named CapRetrieval, whose passages are image captions, and queries are phrases inquiring entities or events in various forms. Zero-shot evaluation suggests that encoders may fail on these fine-grained matching, regardless of training sources or model sizes. Aiming for enhancement, we proceed to finetune encoders with our proposed data generation strategies, which obtains the best performance on CapRetrieval. Within this process, we further identify an issue of granularity dilemma, a challenge for embeddings to express fine-grained salience while aligning with overall semantics. Our dataset, code and models in this work are publicly released at https://github.com/lxucs/CapRetrieval.
ScEdit: Script-based Assessment of Knowledge Editing
May 29, 2025Knowledge Editing (KE) has gained increasing attention, yet current KE tasks remain relatively simple. Under current evaluation frameworks, many editing methods achieve exceptionally high scores, sometimes nearing perfection. However, few studies integrate KE into real-world application scenarios (e.g., recent interest in LLM-as-agent). To support our analysis, we introduce a novel script-based benchmark -- ScEdit (Script-based Knowledge Editing Benchmark) -- which encompasses both counterfactual and temporal edits. We integrate token-level and text-level evaluation methods, comprehensively analyzing existing KE techniques. The benchmark extends traditional fact-based ("What"-type question) evaluation to action-based ("How"-type question) evaluation. We observe that all KE methods exhibit a drop in performance on established metrics and face challenges on text-level metrics, indicating a challenging task. Our benchmark is available at https://github.com/asdfo123/ScEdit.
DBudgetKV: Dynamic Budget in KV Cache Compression for Ensuring Optimal Performance
Feb 24, 2025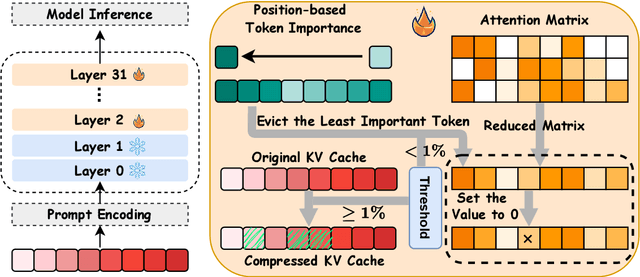
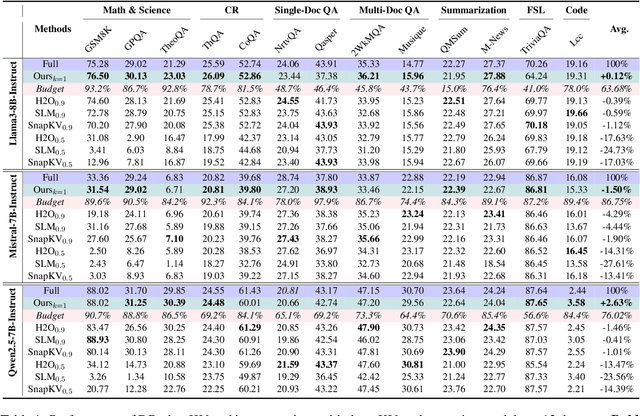
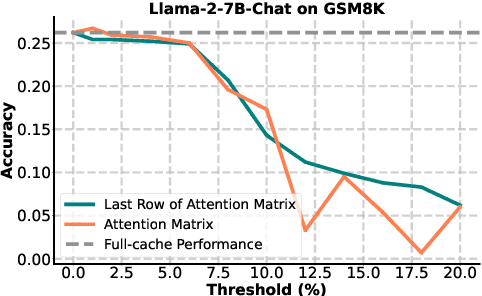
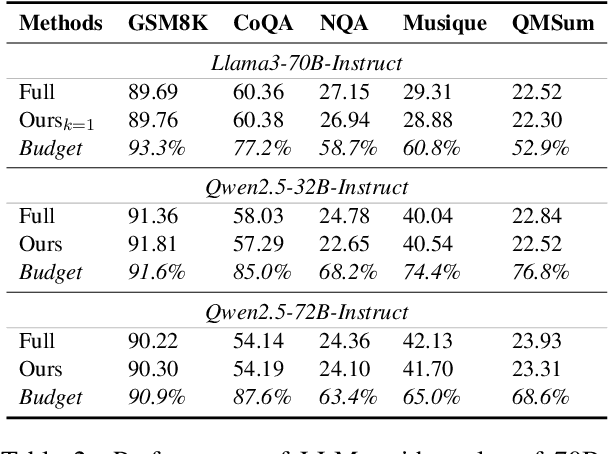
To alleviate memory burden during inference of large language models (LLMs), numerous studies have focused on compressing the KV cache by exploring aspects such as attention sparsity. However, these techniques often require a pre-defined cache budget; as the optimal budget varies with different input lengths and task types, it limits their practical deployment accepting open-domain instructions. To address this limitation, we propose a new KV cache compression objective: to always ensure the full-cache performance regardless of specific inputs, while maximizing KV cache pruning as much as possible. To achieve this goal, we introduce a novel KV cache compression method dubbed DBudgetKV, which features an attention-based metric to signal when the remaining KV cache is unlikely to match the full-cache performance, then halting the pruning process. Empirical evaluation spanning diverse context lengths, task types, and model sizes suggests that our method achieves lossless KV pruning effectively and robustly, exceeding 25% compression ratio on average. Furthermore, our method is easy to integrate within LLM inference, not only optimizing memory space, but also showing reduced inference time compared to existing methods.
Vehicles, Pedestrians, and E-bikes: a Three-party Game at Right-turn-on-red Crossroads Revealing the Dual and Irrational Role of E-bikes that Risks Traffic Safety
Nov 04, 2024



The widespread use of e-bikes has facilitated short-distance travel yet led to confusion and safety problems in road traffic. This study focuses on the dual characteristics of e-bikes in traffic conflicts: they resemble pedestrians when interacting with motor vehicles and behave like motor vehicles when in conflict with pedestrians, which raises the right of way concerns when potential conflicts are at stake. Using the Quantal Response Equilibrium model, this research analyzes the behavioral choice differences of three groups of road users (vehicle-pedestrian, vehicle-e-bike, e-bike-pedestrian) at right-turn-on-red crossroads in right-turning lines and straight-going lines conflict scenarios. The results show that the behavior of e-bikes is more similar to that of motor vehicles than pedestrians overall, and their interactions with either pedestrians or motor vehicles do not establish a reasonable order, increasing the likelihood of confusion and conflict. In contrast, a mutual understanding has developed between motor vehicles and pedestrians, where motor vehicles tend to yield, and pedestrians tend to cross. By clarifying the game theoretical model and introducing the rationality parameter, this study precisely locates the role of e-bikes among road users, which provides a reliable theoretical basis for optimizing traffic regulations.
Graph Representation of Narrative Context: Coherence Dependency via Retrospective Questions
Feb 21, 2024
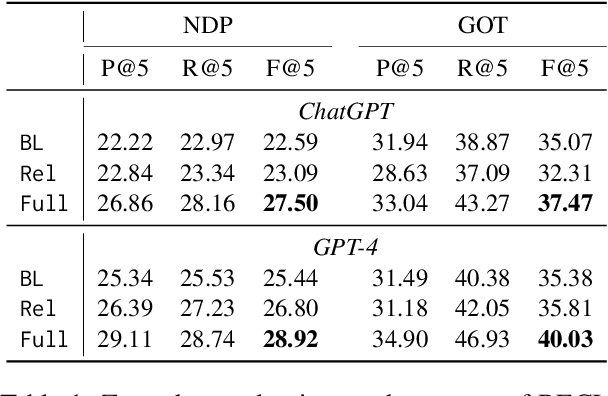
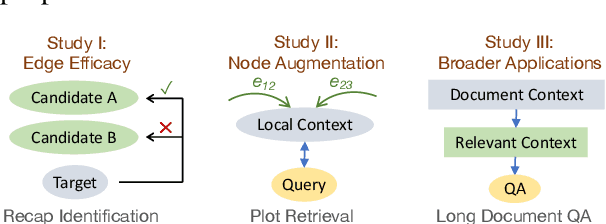
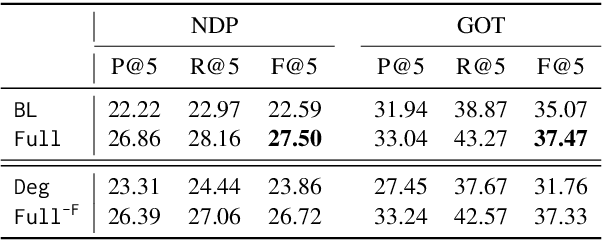
This work introduces a novel and practical paradigm for narrative comprehension, stemming from the observation that individual passages within narratives are often cohesively related than being isolated. We therefore propose to formulate a graph upon narratives dubbed NARCO that depicts a task-agnostic coherence dependency of the entire context. Especially, edges in NARCO encompass retrospective free-form questions between two context snippets reflecting high-level coherent relations, inspired by the cognitive perception of humans who constantly reinstate relevant events from prior context. Importantly, our graph is instantiated through our designed two-stage LLM prompting, thereby without reliance on human annotations. We present three unique studies on its practical utility, examining the edge efficacy via recap identification, local context augmentation via plot retrieval, and broader applications exemplified by long document QA. Experiments suggest that our approaches leveraging NARCO yield performance boost across all three tasks.
Identifying Factual Inconsistency in Summaries: Towards Effective Utilization of Large Language Model
Feb 20, 2024



Factual inconsistency poses a significant hurdle for the commercial deployment of abstractive summarizers. Under this Large Language Model (LLM) era, this work focuses around two important questions: what is the best way to leverage LLM for factual inconsistency detection, and how could we distill a smaller LLM with both high efficiency and efficacy? Three zero-shot paradigms are firstly proposed and evaluated across five diverse datasets: direct inference on the entire summary or each summary window; entity verification through question generation and answering. Experiments suggest that LLM itself is capable to resolve this task train-free under the proper paradigm design, surpassing strong trained baselines by 2.8% on average. To further promote practical utility, we then propose training strategies aimed at distilling smaller open-source LLM that learns to score the entire summary at once with high accuracy, which outperforms the zero-shot approaches by much larger LLM, serving as an effective and efficient ready-to-use scorer.
Previously on the Stories: Recap Snippet Identification for Story Reading
Feb 11, 2024



Similar to the "previously-on" scenes in TV shows, recaps can help book reading by recalling the readers' memory about the important elements in previous texts to better understand the ongoing plot. Despite its usefulness, this application has not been well studied in the NLP community. We propose the first benchmark on this useful task called Recap Snippet Identification with a hand-crafted evaluation dataset. Our experiments show that the proposed task is challenging to PLMs, LLMs, and proposed methods as the task requires a deep understanding of the plot correlation between snippets.