 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDBudgetKV: Dynamic Budget in KV Cache Compression for Ensuring Optimal Performance
Paper and Code
Feb 24, 2025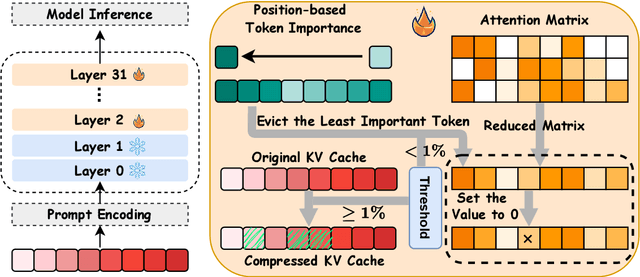
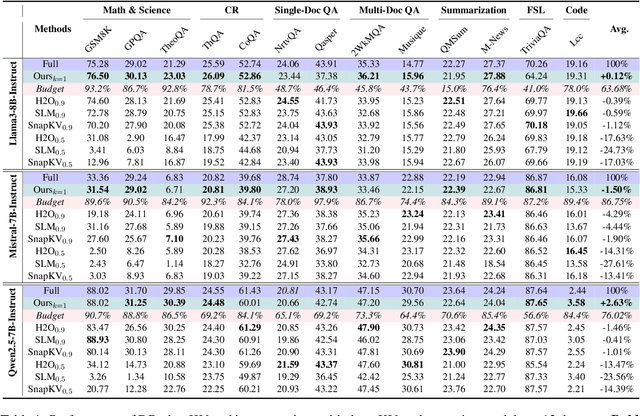
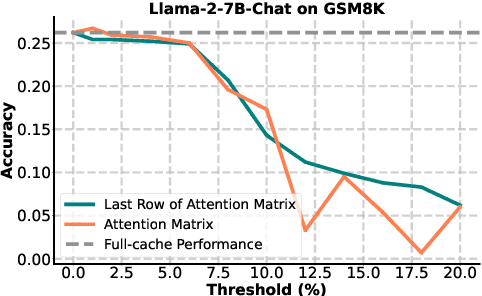
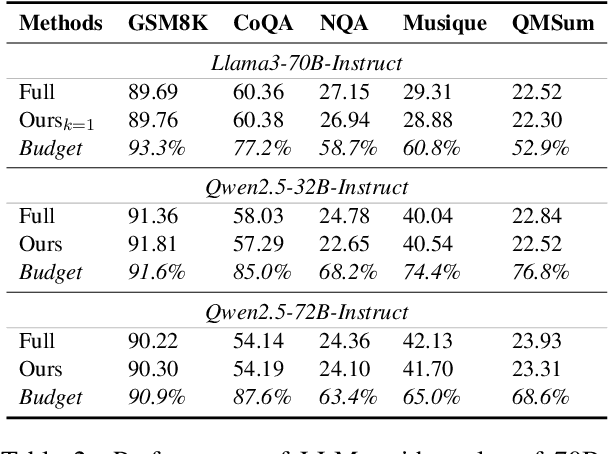
To alleviate memory burden during inference of large language models (LLMs), numerous studies have focused on compressing the KV cache by exploring aspects such as attention sparsity. However, these techniques often require a pre-defined cache budget; as the optimal budget varies with different input lengths and task types, it limits their practical deployment accepting open-domain instructions. To address this limitation, we propose a new KV cache compression objective: to always ensure the full-cache performance regardless of specific inputs, while maximizing KV cache pruning as much as possible. To achieve this goal, we introduce a novel KV cache compression method dubbed DBudgetKV, which features an attention-based metric to signal when the remaining KV cache is unlikely to match the full-cache performance, then halting the pruning process. Empirical evaluation spanning diverse context lengths, task types, and model sizes suggests that our method achieves lossless KV pruning effectively and robustly, exceeding 25% compression ratio on average. Furthermore, our method is easy to integrate within LLM inference, not only optimizing memory space, but also showing reduced inference time compared to existing methods.