 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Federated Anomaly Detection for Multivariate Time Series Data
May 09, 2022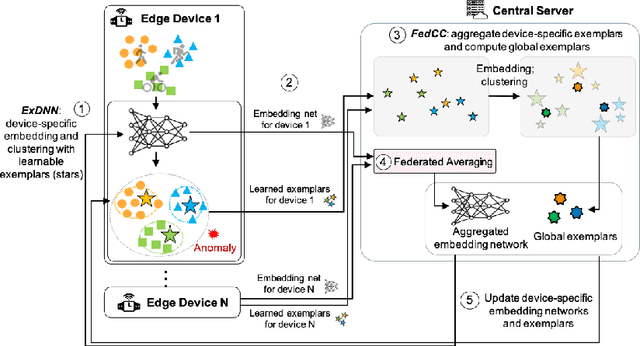
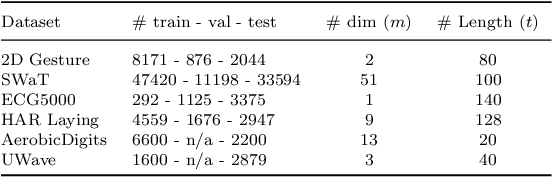
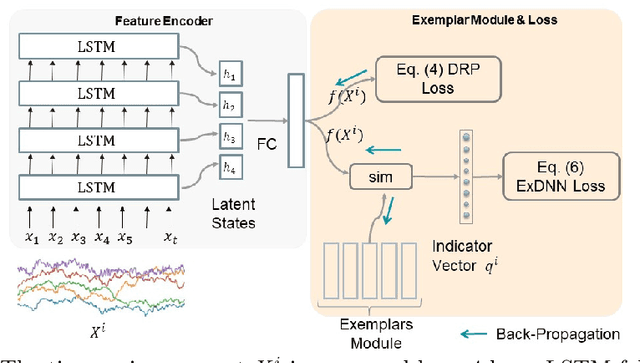
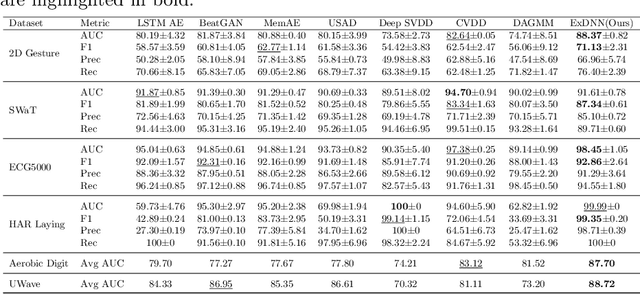
Despite the fact that many anomaly detection approaches have been developed for multivariate time series data, limited effort has been made on federated settings in which multivariate time series data are heterogeneously distributed among different edge devices while data sharing is prohibited. In this paper, we investigate the problem of federated unsupervised anomaly detection and present a Federated Exemplar-based Deep Neural Network (Fed-ExDNN) to conduct anomaly detection for multivariate time series data on different edge devices. Specifically, we first design an Exemplar-based Deep Neural network (ExDNN) to learn local time series representations based on their compatibility with an exemplar module which consists of hidden parameters learned to capture varieties of normal patterns on each edge device. Next, a constrained clustering mechanism (FedCC) is employed on the centralized server to align and aggregate the parameters of different local exemplar modules to obtain a unified global exemplar module. Finally, the global exemplar module is deployed together with a shared feature encoder to each edge device and anomaly detection is conducted by examining the compatibility of testing data to the exemplar module. Fed-ExDNN captures local normal time series patterns with ExDNN and aggregates these patterns by FedCC, and thus can handle the heterogeneous data distributed over different edge devices simultaneously. Thoroughly empirical studies on six public datasets show that ExDNN and Fed-ExDNN can outperform state-of-the-art anomaly detection algorithms and federated learning techniques.
Ordinal-Quadruplet: Retrieval of Missing Classes in Ordinal Time Series
Jan 24, 2022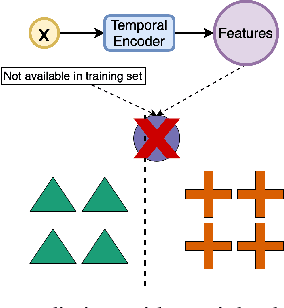

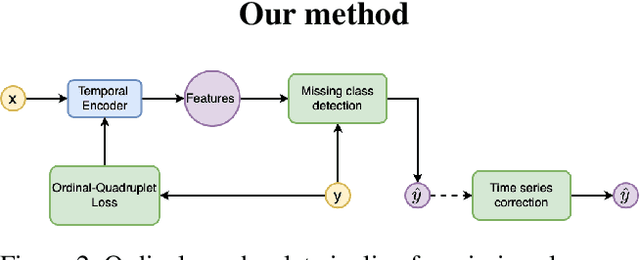
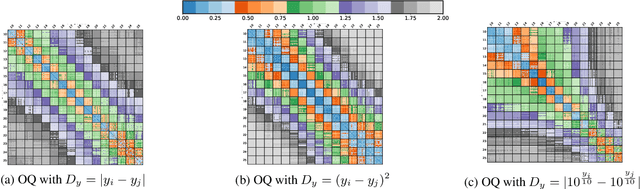
In this paper, we propose an ordered time series classification framework that is robust against missing classes in the training data, i.e., during testing we can prescribe classes that are missing during training. This framework relies on two main components: (1) our newly proposed ordinal-quadruplet loss, which forces the model to learn latent representation while preserving the ordinal relation among labels, (2) testing procedure, which utilizes the property of latent representation (order preservation). We conduct experiments based on real world multivariate time series data and show the significant improvement in the prediction of missing labels even with 40% of the classes are missing from training. Compared with the well-known triplet loss optimization augmented with interpolation for missing information, in some cases, we nearly double the accuracy.