 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRank Supervised Contrastive Learning for Time Series Classification
Jan 31, 2024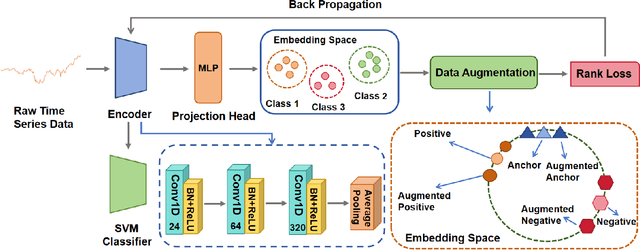

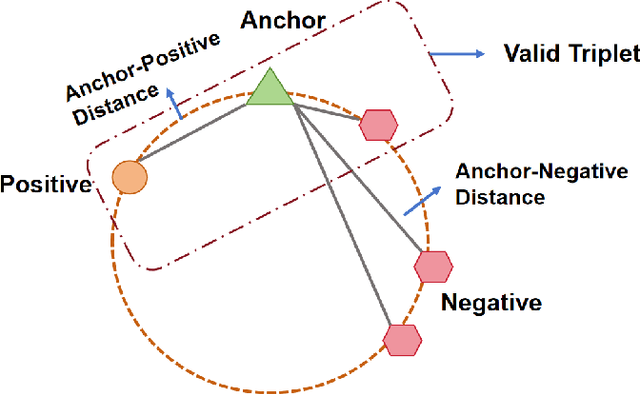
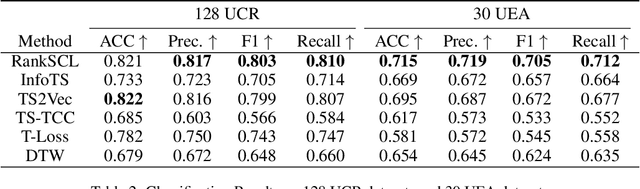
Recently, various contrastive learning techniques have been developed to categorize time series data and exhibit promising performance. A general paradigm is to utilize appropriate augmentations and construct feasible positive samples such that the encoder can yield robust and discriminative representations by mapping similar data points closer together in the feature space while pushing dissimilar data points farther apart. Despite its efficacy, the fine-grained relative similarity (e.g., rank) information of positive samples is largely ignored, especially when labeled samples are limited. To this end, we present Rank Supervised Contrastive Learning (RankSCL) to perform time series classification. Different from conventional contrastive learning frameworks, RankSCL augments raw data in a targeted way in the embedding space and adopts certain filtering rules to select more informative positive and negative pairs of samples. Moreover, a novel rank loss is developed to assign different weights for different levels of positive samples, enable the encoder to extract the fine-grained information of the same class, and produce a clear boundary among different classes. Thoroughly empirical studies on 128 UCR datasets and 30 UEA datasets demonstrate that the proposed RankSCL can achieve state-of-the-art performance compared to existing baseline methods.
Ordinal-Quadruplet: Retrieval of Missing Classes in Ordinal Time Series
Jan 24, 2022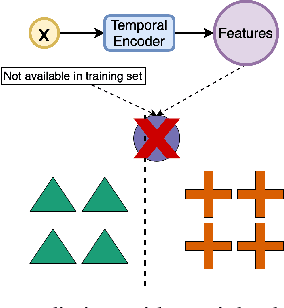

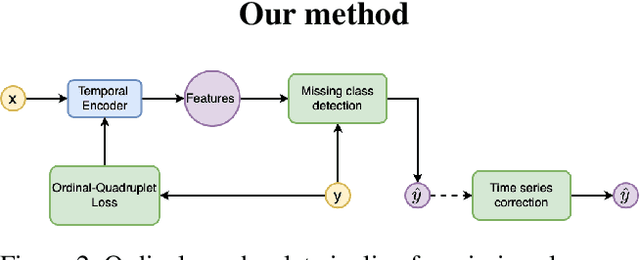
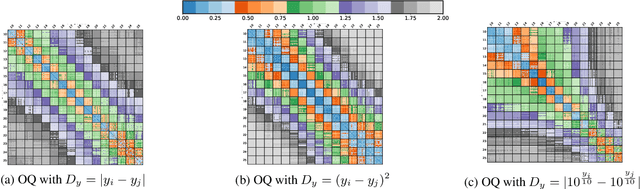
In this paper, we propose an ordered time series classification framework that is robust against missing classes in the training data, i.e., during testing we can prescribe classes that are missing during training. This framework relies on two main components: (1) our newly proposed ordinal-quadruplet loss, which forces the model to learn latent representation while preserving the ordinal relation among labels, (2) testing procedure, which utilizes the property of latent representation (order preservation). We conduct experiments based on real world multivariate time series data and show the significant improvement in the prediction of missing labels even with 40% of the classes are missing from training. Compared with the well-known triplet loss optimization augmented with interpolation for missing information, in some cases, we nearly double the accuracy.