 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePercept-Aware Surgical Planning for Visual Cortical Prostheses with Vascular Avoidance
Feb 27, 2026Cortical visual prostheses aim to restore sight by electrically stimulating neurons in early visual cortex (V1). With the emergence of high-density and flexible neural interfaces, electrode placement within three-dimensional cortex has become a critical surgical planning problem. Existing strategies emphasize visual field coverage and anatomical heuristics but do not directly optimize predicted perceptual outcomes under safety constraints. We present a percept-aware framework for surgical planning of cortical visual prostheses that formulates electrode placement as a constrained optimization problem in anatomical space. Electrode coordinates are treated as learnable parameters and optimized end-to-end using a differentiable forward model of prosthetic vision. The objective minimizes task-level perceptual error while incorporating vascular avoidance and gray matter feasibility constraints. Evaluated on simulated reading and natural image tasks using realistic folded cortical geometry (FreeSurfer fsaverage), percept-aware optimization consistently improves reconstruction fidelity relative to coverage-based placement strategies. Importantly, vascular safety constraints eliminate margin violations while preserving perceptual performance. The framework further enables co-optimization of multi-electrode thread configurations under fixed insertion budgets. These results demonstrate how differentiable percept models can inform anatomically grounded, safety-aware computer-assisted planning for cortical neural interfaces and provide a foundation for optimizing next-generation visual prostheses.
SymbolSight: Minimizing Inter-Symbol Interference for Reading with Prosthetic Vision
Jan 24, 2026Retinal prostheses restore limited visual perception, but low spatial resolution and temporal persistence make reading difficult. In sequential letter presentation, the afterimage of one symbol can interfere with perception of the next, leading to systematic recognition errors. Rather than relying on future hardware improvements, we investigate whether optimizing the visual symbols themselves can mitigate this temporal interference. We present SymbolSight, a computational framework that selects symbol-to-letter mappings to minimize confusion among frequently adjacent letters. Using simulated prosthetic vision (SPV) and a neural proxy observer, we estimate pairwise symbol confusability and optimize assignments using language-specific bigram statistics. Across simulations in Arabic, Bulgarian, and English, the resulting heterogeneous symbol sets reduced predicted confusion by a median factor of 22 relative to native alphabets. These results suggest that standard typography is poorly matched to serial, low-bandwidth prosthetic vision and demonstrate how computational modeling can efficiently narrow the design space of visual encodings to generate high-potential candidates for future psychophysical and clinical evaluation.
BIRD: Behavior Induction via Representation-structure Distillation
May 29, 2025Human-aligned deep learning models exhibit behaviors consistent with human values, such as robustness, fairness, and honesty. Transferring these behavioral properties to models trained on different tasks or data distributions remains challenging: aligned behavior is easily forgotten during fine-tuning, and collecting task-specific data that preserves this behavior can be prohibitively costly. We introduce BIRD (Behavior Induction via Representation-structure Distillation), a flexible framework for transferring aligned behavior by matching the internal representation structure of a student model to that of a teacher. Applied to out-of-distribution robustness in image classification, BIRD outperforms fine-tuning, transfer learning, and continual learning methods, improving robust accuracy by up to 16% over the next strongest baseline. It remains effective even when the teacher is trained on a much simpler dataset and is $25 \times$ smaller than the student. In a large-scale study of over 400 teacher-student pairs, we show that three interpretable and computable properties of the teacher's representations (i.e., task relevance, behavioral relevance, and complementary knowledge) explain up to 85% of the variance in transfer success. These insights offer practical guidance for teacher selection and design. BIRD turns small, well-aligned models into scalable alignment seeds, removing a key bottleneck in deploying safe AI systems in the wild.
Human-in-the-Loop Optimization for Deep Stimulus Encoding in Visual Prostheses
Jun 16, 2023



Neuroprostheses show potential in restoring lost sensory function and enhancing human capabilities, but the sensations produced by current devices often seem unnatural or distorted. Exact placement of implants and differences in individual perception lead to significant variations in stimulus response, making personalized stimulus optimization a key challenge. Bayesian optimization could be used to optimize patient-specific stimulation parameters with limited noisy observations, but is not feasible for high-dimensional stimuli. Alternatively, deep learning models can optimize stimulus encoding strategies, but typically assume perfect knowledge of patient-specific variations. Here we propose a novel, practically feasible approach that overcomes both of these fundamental limitations. First, a deep encoder network is trained to produce optimal stimuli for any individual patient by inverting a forward model mapping electrical stimuli to visual percepts. Second, a preferential Bayesian optimization strategy utilizes this encoder to optimize patient-specific parameters for a new patient, using a minimal number of pairwise comparisons between candidate stimuli. We demonstrate the viability of this approach on a novel, state-of-the-art visual prosthesis model. We show that our approach quickly learns a personalized stimulus encoder, leads to dramatic improvements in the quality of restored vision, and is robust to noisy patient feedback and misspecifications in the underlying forward model. Overall, our results suggest that combining the strengths of deep learning and Bayesian optimization could significantly improve the perceptual experience of patients fitted with visual prostheses and may prove a viable solution for a range of neuroprosthetic technologies.
Explaining V1 Properties with a Biologically Constrained Deep Learning Architecture
May 25, 2023


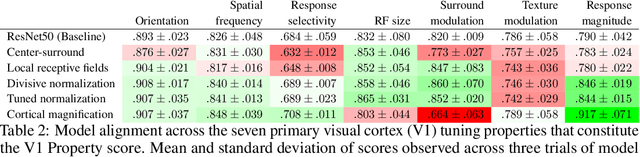
Convolutional neural networks (CNNs) have recently emerged as promising models of the ventral visual stream, despite their lack of biological specificity. While current state-of-the-art models of the primary visual cortex (V1) have surfaced from training with adversarial examples and extensively augmented data, these models are still unable to explain key neural properties observed in V1 that arise from biological circuitry. To address this gap, we systematically incorporated neuroscience-derived architectural components into CNNs to identify a set of mechanisms and architectures that comprehensively explain neural activity in V1. We show drastic improvements in model-V1 alignment driven by the integration of architectural components that simulate center-surround antagonism, local receptive fields, tuned normalization, and cortical magnification. Upon enhancing task-driven CNNs with a collection of these specialized components, we uncover models with latent representations that yield state-of-the-art explanation of V1 neural activity and tuning properties. Our results highlight an important advancement in the field of NeuroAI, as we systematically establish a set of architectural components that contribute to unprecedented explanation of V1. The neuroscience insights that could be gleaned from increasingly accurate in-silico models of the brain have the potential to greatly advance the fields of both neuroscience and artificial intelligence.
Adapting Brain-Like Neural Networks for Modeling Cortical Visual Prostheses
Sep 27, 2022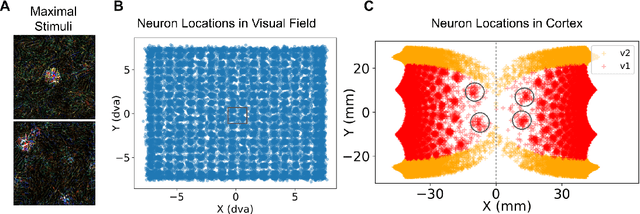
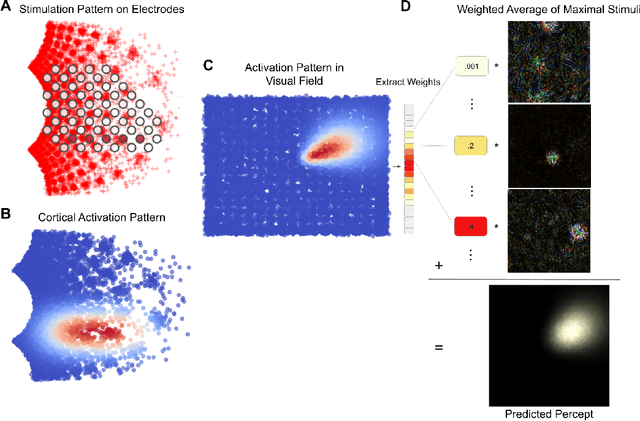
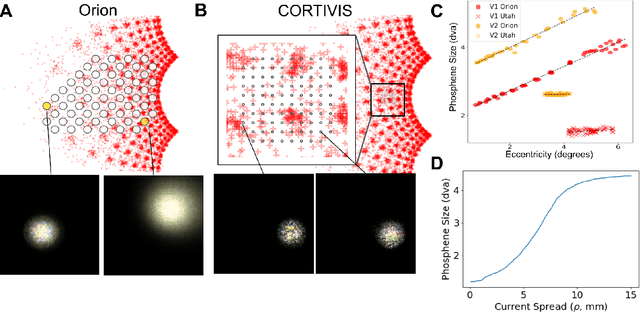
Cortical prostheses are devices implanted in the visual cortex that attempt to restore lost vision by electrically stimulating neurons. Currently, the vision provided by these devices is limited, and accurately predicting the visual percepts resulting from stimulation is an open challenge. We propose to address this challenge by utilizing 'brain-like' convolutional neural networks (CNNs), which have emerged as promising models of the visual system. To investigate the feasibility of adapting brain-like CNNs for modeling visual prostheses, we developed a proof-of-concept model to predict the perceptions resulting from electrical stimulation. We show that a neurologically-inspired decoding of CNN activations produces qualitatively accurate phosphenes, comparable to phosphenes reported by real patients. Overall, this is an essential first step towards building brain-like models of electrical stimulation, which may not just improve the quality of vision provided by cortical prostheses but could also further our understanding of the neural code of vision.
A Hybrid Neural Autoencoder for Sensory Neuroprostheses and Its Applications in Bionic Vision
May 26, 2022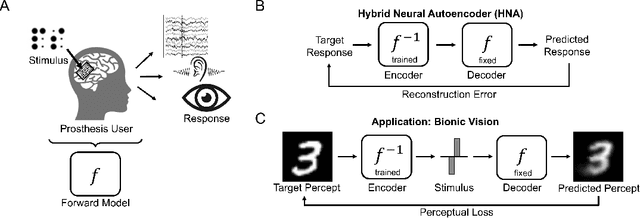
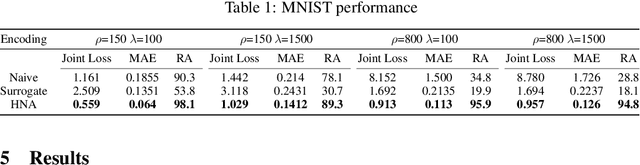
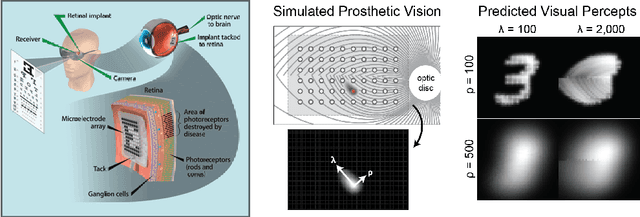
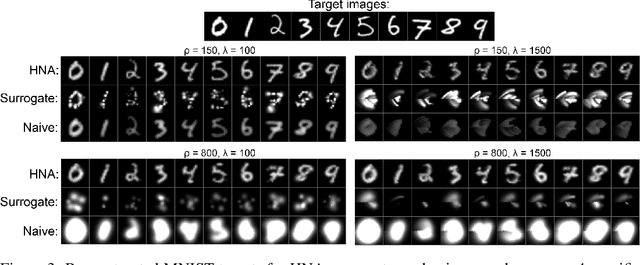
Sensory neuroprostheses are emerging as a promising technology to restore lost sensory function or augment human capacities. However, sensations elicited by current devices often appear artificial and distorted. Although current models can often predict the neural or perceptual response to an electrical stimulus, an optimal stimulation strategy solves the inverse problem: what is the required stimulus to produce a desired response? Here we frame this as an end-to-end optimization problem, where a deep neural network encoder is trained to invert a known, fixed forward model that approximates the underlying biological system. As a proof of concept, we demonstrate the effectiveness of our hybrid neural autoencoder (HNA) on the use case of visual neuroprostheses. We found that HNA is able to produce high-fidelity stimuli from the MNIST and COCO datasets that outperform conventional encoding strategies and surrogate techniques across all tested conditions. Overall this is an important step towards the long-standing challenge of restoring high-quality vision to people living with incurable blindness and may prove a promising solution for a variety of neuroprosthetic technologies.
Efficient visual object representation using a biologically plausible spike-latency code and winner-take-all inhibition
May 20, 2022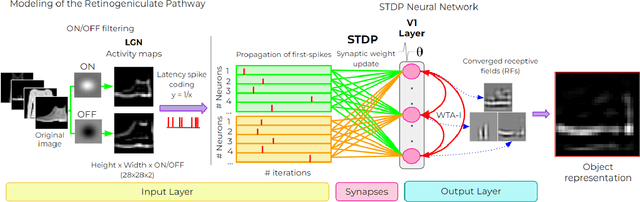

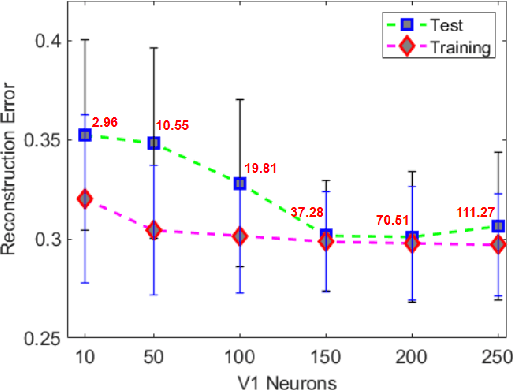
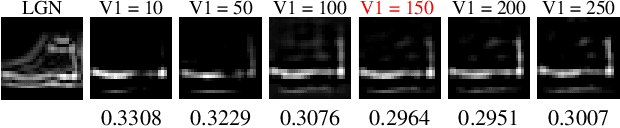
Deep neural networks have surpassed human performance in key visual challenges such as object recognition, but require a large amount of energy, computation, and memory. In contrast, spiking neural networks (SNNs) have the potential to improve both the efficiency and biological plausibility of object recognition systems. Here we present a SNN model that uses spike-latency coding and winner-take-all inhibition (WTA-I) to efficiently represent visual stimuli from the Fashion MNIST dataset. Stimuli were preprocessed with center-surround receptive fields and then fed to a layer of spiking neurons whose synaptic weights were updated using spike-timing-dependent-plasticity (STDP). We investigate how the quality of the represented objects changes under different WTA-I schemes and demonstrate that a network of 150 spiking neurons can efficiently represent objects with as little as 40 spikes. Studying how core object recognition may be implemented using biologically plausible learning rules in SNNs may not only further our understanding of the brain, but also lead to novel and efficient artificial vision systems.
Deep Learning-Based Perceptual Stimulus Encoder for Bionic Vision
Mar 10, 2022

Retinal implants have the potential to treat incurable blindness, yet the quality of the artificial vision they produce is still rudimentary. An outstanding challenge is identifying electrode activation patterns that lead to intelligible visual percepts (phosphenes). Here we propose a PSE based on CNN that is trained in an end-to-end fashion to predict the electrode activation patterns required to produce a desired visual percept. We demonstrate the effectiveness of the encoder on MNIST using a psychophysically validated phosphene model tailored to individual retinal implant users. The present work constitutes an essential first step towards improving the quality of the artificial vision provided by retinal implants.
U-Net with Hierarchical Bottleneck Attention for Landmark Detection in Fundus Images of the Degenerated Retina
Jul 09, 2021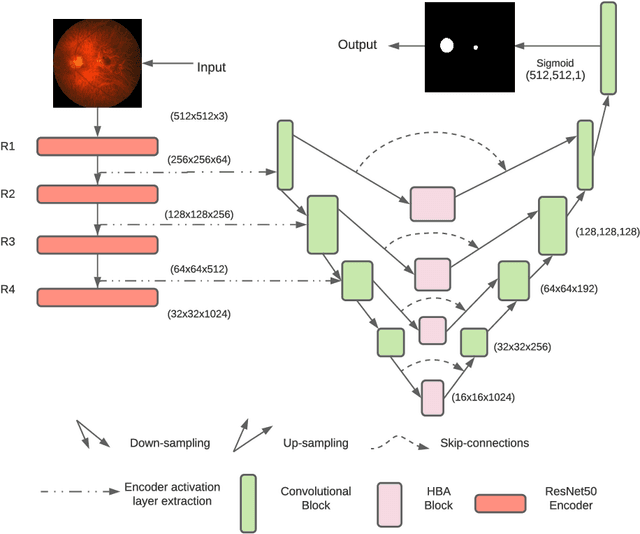

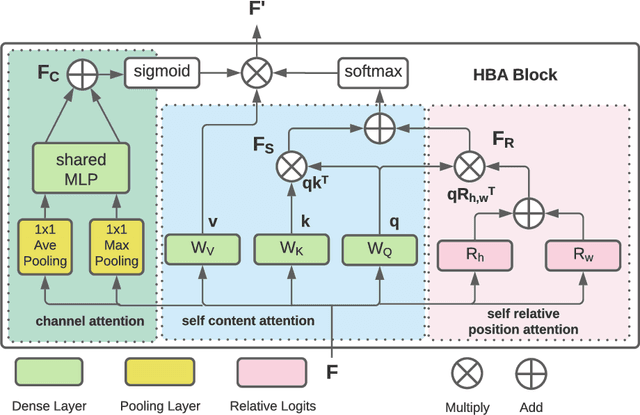

Fundus photography has routinely been used to document the presence and severity of retinal degenerative diseases such as age-related macular degeneration (AMD), glaucoma, and diabetic retinopathy (DR) in clinical practice, for which the fovea and optic disc (OD) are important retinal landmarks. However, the occurrence of lesions, drusen, and other retinal abnormalities during retinal degeneration severely complicates automatic landmark detection and segmentation. Here we propose HBA-U-Net: a U-Net backbone enriched with hierarchical bottleneck attention. The network consists of a novel bottleneck attention block that combines and refines self-attention, channel attention, and relative-position attention to highlight retinal abnormalities that may be important for fovea and OD segmentation in the degenerated retina. HBA-U-Net achieved state-of-the-art results on fovea detection across datasets and eye conditions (ADAM: Euclidean Distance (ED) of 25.4 pixels, REFUGE: 32.5 pixels, IDRiD: 32.1 pixels), on OD segmentation for AMD (ADAM: Dice Coefficient (DC) of 0.947), and on OD detection for DR (IDRiD: ED of 20.5 pixels). Our results suggest that HBA-U-Net may be well suited for landmark detection in the presence of a variety of retinal degenerative diseases.