 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfluence of field of view in visual prostheses design: Analysis with a VR system
Jan 28, 2025Visual prostheses are designed to restore partial functional vision in patients with total vision loss. Retinal visual prostheses provide limited capabilities as a result of low resolution, limited field of view and poor dynamic range. Understanding the influence of these parameters in the perception results can guide prostheses research and design. In this work, we evaluate the influence of field of view with respect to spatial resolution in visual prostheses, measuring the accuracy and response time in a search and recognition task. Twenty-four normally sighted participants were asked to find and recognize usual objects, such as furniture and home appliance in indoor room scenes. For the experiment, we use a new simulated prosthetic vision system that allows simple and effective experimentation. Our system uses a virtual-reality environment based on panoramic scenes. The simulator employs a head-mounted display which allows users to feel immersed in the scene by perceiving the entire scene all around. Our experiments use public image datasets and a commercial head-mounted display. We have also released the virtual-reality software for replicating and extending the experimentation. Results show that the accuracy and response time decrease when the field of view is increased. Furthermore, performance appears to be correlated with the angular resolution, but showing a diminishing return even with a resolution of less than 2.3 phosphenes per degree. Our results seem to indicate that, for the design of retinal prostheses, it is better to concentrate the phosphenes in a small area, to maximize the angular resolution, even if that implies sacrificing field of view.
Assessing visual acuity in visual prostheses through a virtual-reality system
May 20, 2022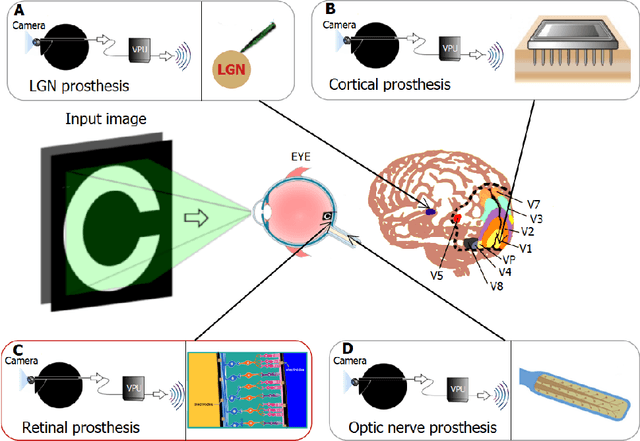
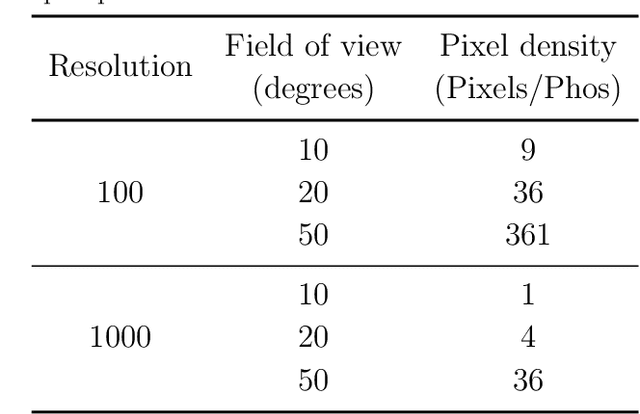
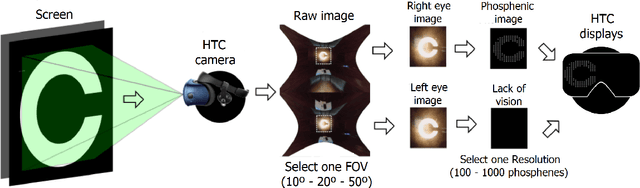
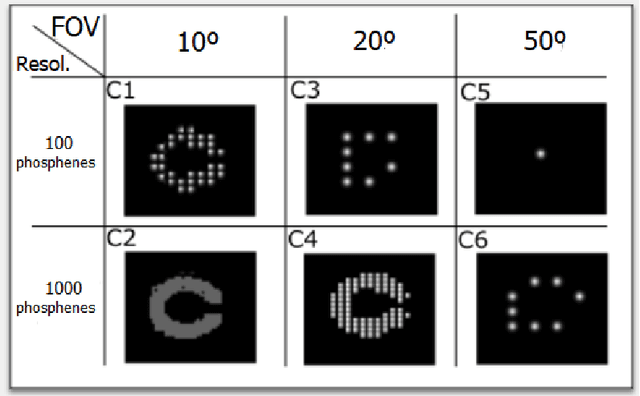
Current visual implants still provide very low resolution and limited field of view, thus limiting visual acuity in implanted patients. Developments of new strategies of artificial vision simulation systems by harnessing new advancements in technologies are of upmost priorities for the development of new visual devices. In this work, we take advantage of virtual-reality software paired with a portable head-mounted display and evaluated the performance of normally sighted participants under simulated prosthetic vision with variable field of view and number of pixels. Our simulated prosthetic vision system allows simple experimentation in order to study the design parameters of future visual prostheses. Ten normally sighted participants volunteered for a visual acuity study. Subjects were required to identify computer-generated Landolt-C gap orientation and different stimulus based on light perception, time-resolution, light location and motion perception commonly used for visual acuity examination in the sighted. Visual acuity scores were recorded across different conditions of number of electrodes and size of field of view. Our results showed that of all conditions tested, a field of view of 20{\deg} and 1000 phosphenes of resolution proved the best, with a visual acuity of 1.3 logMAR. Furthermore, performance appears to be correlated with phosphene density, but showing a diminishing return when field of view is less than 20{\deg}. The development of new artificial vision simulation systems can be useful to guide the development of new visual devices and the optimization of field of view and resolution to provide a helpful and valuable visual aid to profoundly or totally blind patients.
Efficient visual object representation using a biologically plausible spike-latency code and winner-take-all inhibition
May 20, 2022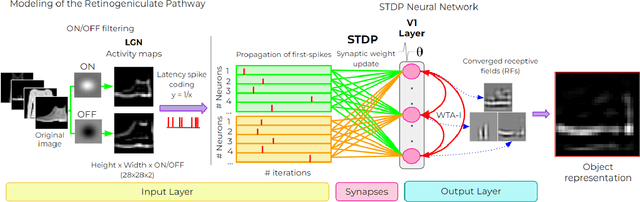

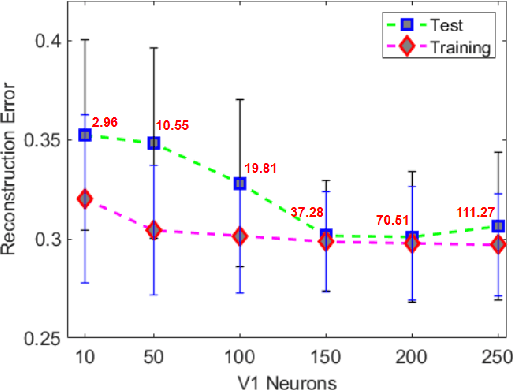
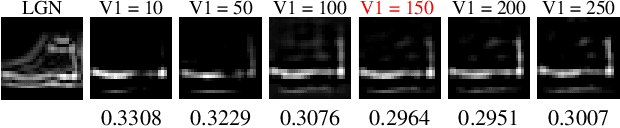
Deep neural networks have surpassed human performance in key visual challenges such as object recognition, but require a large amount of energy, computation, and memory. In contrast, spiking neural networks (SNNs) have the potential to improve both the efficiency and biological plausibility of object recognition systems. Here we present a SNN model that uses spike-latency coding and winner-take-all inhibition (WTA-I) to efficiently represent visual stimuli from the Fashion MNIST dataset. Stimuli were preprocessed with center-surround receptive fields and then fed to a layer of spiking neurons whose synaptic weights were updated using spike-timing-dependent-plasticity (STDP). We investigate how the quality of the represented objects changes under different WTA-I schemes and demonstrate that a network of 150 spiking neurons can efficiently represent objects with as little as 40 spikes. Studying how core object recognition may be implemented using biologically plausible learning rules in SNNs may not only further our understanding of the brain, but also lead to novel and efficient artificial vision systems.
Augmented reality navigation system for visual prosthesis
Sep 30, 2021
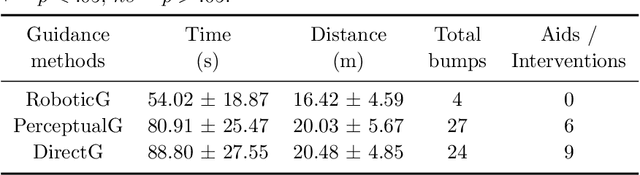

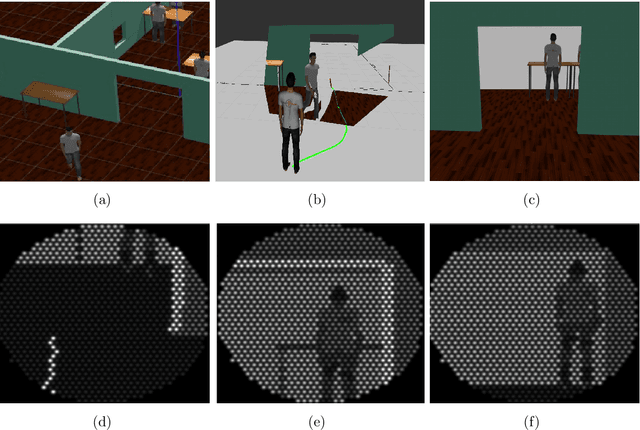
The visual functions of visual prostheses such as field of view, resolution and dynamic range, seriously restrict the person's ability to navigate in unknown environments. Implanted patients still require constant assistance for navigating from one location to another. Hence, there is a need for a system that is able to assist them safely during their journey. In this work, we propose an augmented reality navigation system for visual prosthesis that incorporates a software of reactive navigation and path planning which guides the subject through convenient, obstacle-free route. It consists on four steps: locating the subject on a map, planning the subject trajectory, showing it to the subject and re-planning without obstacles. We have also designed a simulated prosthetic vision environment which allows us to systematically study navigation performance. Twelve subjects participated in the experiment. Subjects were guided by the augmented reality navigation system and their instruction was to navigate through different environments until they reached two goals, cross the door and find an object (bin), as fast and accurately as possible. Results show how our augmented navigation system help navigation performance by reducing the time and distance to reach the goals, even significantly reducing the number of obstacles collisions, compared to other baseline methods.
Structural and object detection for phosphene images
Sep 26, 2018


Prosthetic vision based on phosphenes is a promising way to provide visual perception to some blind people. However, phosphenic images are very limited in terms of spatial resolution (e.g.: 32 x 32 phosphene array) and luminance levels (e.g.: 8 gray levels), which results in the subject receiving very limited information about the scene. This requires using high-level processing to extract more information from the scene and present it to the subject with the phosphenes limitations. In this work, we study the recognition of indoor environments under simulated prosthetic vision. Most research in simulated prosthetic vision is performed based on static images, while very few researchers have addressed the problem of scene recognition through video sequences. We propose a new approach to build a schematic representation of indoor environments for phosphene images. Our schematic representation relies on two parallel CNNs for the extraction of structural informative edges of the room and the relevant object silhouettes based on mask segmentation. We have performed a study with twelve normally sighted subjects to evaluate how our methods were able to the room recognition by presenting phosphenic images and videos. We show how our method is able to increase the recognition ability of the user from 75% using alternative methods to 90% using our approach.