 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGLAB: A Modular and Research-Oriented Unified Framework for Retrieval-Augmented Generation
Aug 21, 2024
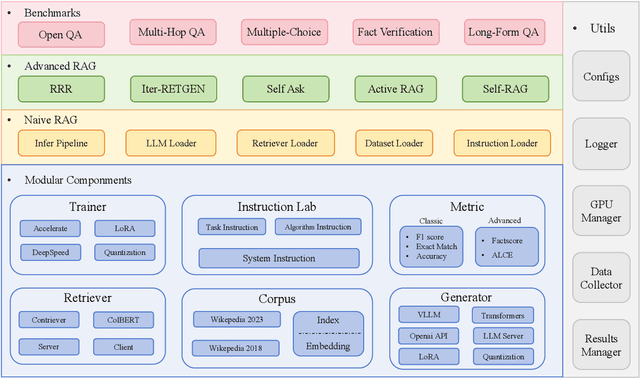

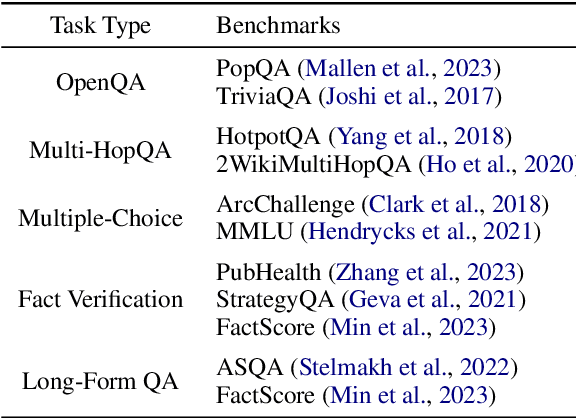
Large Language Models (LLMs) demonstrate human-level capabilities in dialogue, reasoning, and knowledge retention. However, even the most advanced LLMs face challenges such as hallucinations and real-time updating of their knowledge. Current research addresses this bottleneck by equipping LLMs with external knowledge, a technique known as Retrieval Augmented Generation (RAG). However, two key issues constrained the development of RAG. First, there is a growing lack of comprehensive and fair comparisons between novel RAG algorithms. Second, open-source tools such as LlamaIndex and LangChain employ high-level abstractions, which results in a lack of transparency and limits the ability to develop novel algorithms and evaluation metrics. To close this gap, we introduce RAGLAB, a modular and research-oriented open-source library. RAGLAB reproduces 6 existing algorithms and provides a comprehensive ecosystem for investigating RAG algorithms. Leveraging RAGLAB, we conduct a fair comparison of 6 RAG algorithms across 10 benchmarks. With RAGLAB, researchers can efficiently compare the performance of various algorithms and develop novel algorithms.
CLEAN-EVAL: Clean Evaluation on Contaminated Large Language Models
Nov 15, 2023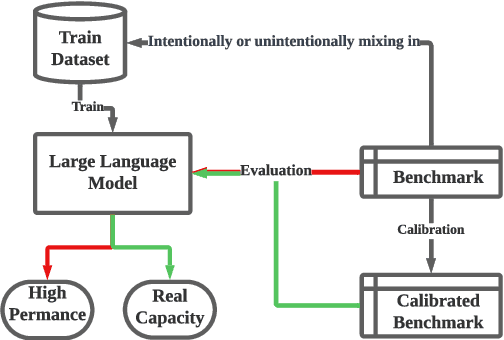
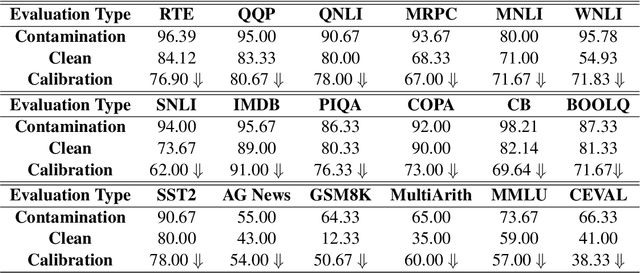
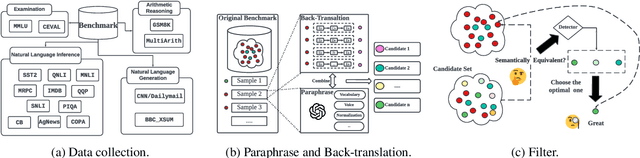

We are currently in an era of fierce competition among various large language models (LLMs) continuously pushing the boundaries of benchmark performance. However, genuinely assessing the capabilities of these LLMs has become a challenging and critical issue due to potential data contamination, and it wastes dozens of time and effort for researchers and engineers to download and try those contaminated models. To save our precious time, we propose a novel and useful method, Clean-Eval, which mitigates the issue of data contamination and evaluates the LLMs in a cleaner manner. Clean-Eval employs an LLM to paraphrase and back-translate the contaminated data into a candidate set, generating expressions with the same meaning but in different surface forms. A semantic detector is then used to filter the generated low-quality samples to narrow down this candidate set. The best candidate is finally selected from this set based on the BLEURT score. According to human assessment, this best candidate is semantically similar to the original contamination data but expressed differently. All candidates can form a new benchmark to evaluate the model. Our experiments illustrate that Clean-Eval substantially restores the actual evaluation results on contaminated LLMs under both few-shot learning and fine-tuning scenarios.