 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-MATH: A University-Level Benchmark for Evaluating Mathematical Skills in LLMs
Paper and Code

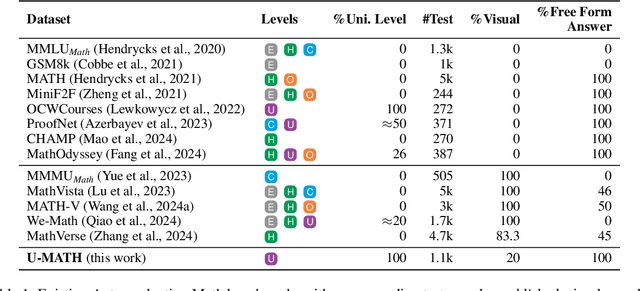
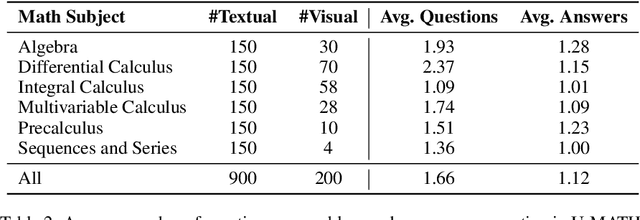
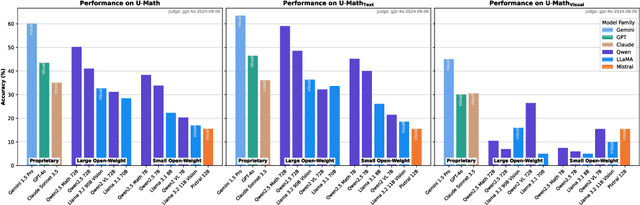
The current evaluation of mathematical skills in LLMs is limited, as existing benchmarks are either relatively small, primarily focus on elementary and high-school problems, or lack diversity in topics. Additionally, the inclusion of visual elements in tasks remains largely under-explored. To address these gaps, we introduce U-MATH, a novel benchmark of 1,100 unpublished open-ended university-level problems sourced from teaching materials. It is balanced across six core subjects, with 20% of multimodal problems. Given the open-ended nature of U-MATH problems, we employ an LLM to judge the correctness of generated solutions. To this end, we release $\mu$-MATH, a dataset to evaluate the LLMs' capabilities in judging solutions. The evaluation of general domain, math-specific, and multimodal LLMs highlights the challenges presented by U-MATH. Our findings reveal that LLMs achieve a maximum accuracy of only 63% on text-based tasks, with even lower 45% on visual problems. The solution assessment proves challenging for LLMs, with the best LLM judge having an F1-score of 80% on $\mu$-MATH.