 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePALM: Few-Shot Prompt Learning for Audio Language Models
Paper and Code
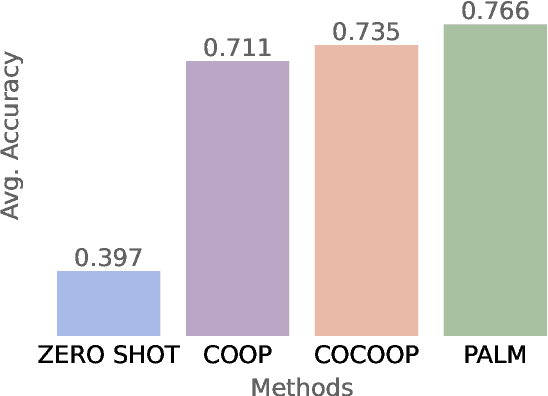
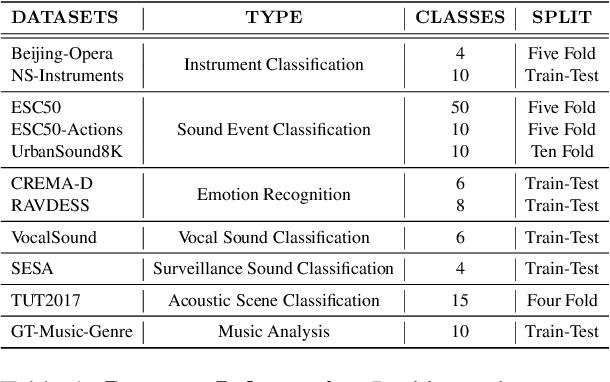
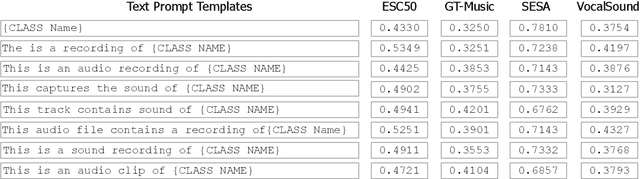
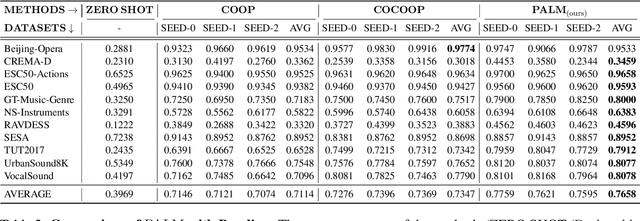
Audio-Language Models (ALMs) have recently achieved remarkable success in zero-shot audio recognition tasks, which match features of audio waveforms with class-specific text prompt features, inspired by advancements in Vision-Language Models (VLMs). Given the sensitivity of zero-shot performance to the choice of hand-crafted text prompts, many prompt learning techniques have been developed for VLMs. We explore the efficacy of these approaches in ALMs and propose a novel method, Prompt Learning in Audio Language Models (PALM), which optimizes the feature space of the text encoder branch. Unlike existing methods that work in the input space, our approach results in greater training efficiency. We demonstrate the effectiveness of our approach on 11 audio recognition datasets, encompassing a variety of speech-processing tasks, and compare the results with three baselines in a few-shot learning setup. Our method is either on par with or outperforms other approaches while being computationally less demanding. Code is available at https://asif-hanif.github.io/palm/