 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLead Instrument Detection from Multitrack Music
Mar 05, 2025
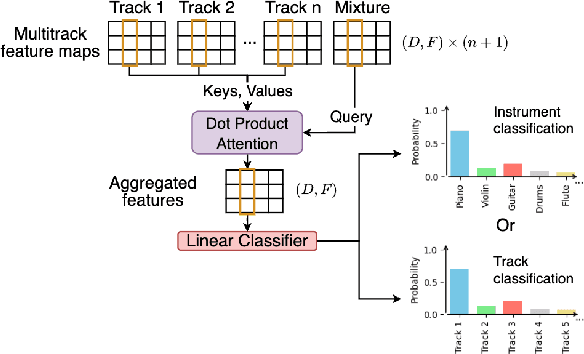


Prior approaches to lead instrument detection primarily analyze mixture audio, limited to coarse classifications and lacking generalization ability. This paper presents a novel approach to lead instrument detection in multitrack music audio by crafting expertly annotated datasets and designing a novel framework that integrates a self-supervised learning model with a track-wise, frame-level attention-based classifier. This attention mechanism dynamically extracts and aggregates track-specific features based on their auditory importance, enabling precise detection across varied instrument types and combinations. Enhanced by track classification and permutation augmentation, our model substantially outperforms existing SVM and CRNN models, showing robustness on unseen instruments and out-of-domain testing. We believe our exploration provides valuable insights for future research on audio content analysis in multitrack music settings.
Unlocking Potential in Pre-Trained Music Language Models for Versatile Multi-Track Music Arrangement
Aug 27, 2024



Large language models have shown significant capabilities across various domains, including symbolic music generation. However, leveraging these pre-trained models for controllable music arrangement tasks, each requiring different forms of musical information as control, remains a novel challenge. In this paper, we propose a unified sequence-to-sequence framework that enables the fine-tuning of a symbolic music language model for multiple multi-track arrangement tasks, including band arrangement, piano reduction, drum arrangement, and voice separation. Our experiments demonstrate that the proposed approach consistently achieves higher musical quality compared to task-specific baselines across all four tasks. Furthermore, through additional experiments on probing analysis, we show the pre-training phase equips the model with essential knowledge to understand musical conditions, which is hard to acquired solely through task-specific fine-tuning.
LOAF-M2L: Joint Learning of Wording and Formatting for Singable Melody-to-Lyric Generation
Jul 05, 2023

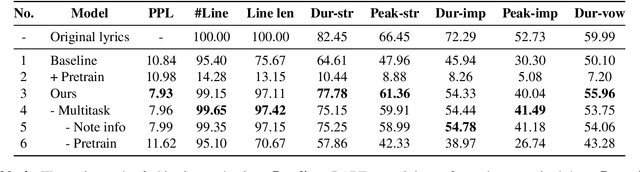
Despite previous efforts in melody-to-lyric generation research, there is still a significant compatibility gap between generated lyrics and melodies, negatively impacting the singability of the outputs. This paper bridges the singability gap with a novel approach to generating singable lyrics by jointly Learning wOrding And Formatting during Melody-to-Lyric training (LOAF-M2L). After general-domain pretraining, our proposed model acquires length awareness first from a large text-only lyric corpus. Then, we introduce a new objective informed by musicological research on the relationship between melody and lyrics during melody-to-lyric training, which enables the model to learn the fine-grained format requirements of the melody. Our model achieves 3.75% and 21.44% absolute accuracy gains in the outputs' number-of-line and syllable-per-line requirements compared to naive fine-tuning, without sacrificing text fluency. Furthermore, our model demonstrates a 63.92% and 74.18% relative improvement of music-lyric compatibility and overall quality in the subjective evaluation, compared to the state-of-the-art melody-to-lyric generation model, highlighting the significance of formatting learning.
Songs Across Borders: Singable and Controllable Neural Lyric Translation
May 26, 2023


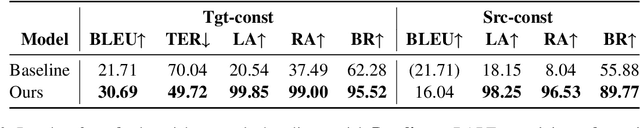
The development of general-domain neural machine translation (NMT) methods has advanced significantly in recent years, but the lack of naturalness and musical constraints in the outputs makes them unable to produce singable lyric translations. This paper bridges the singability quality gap by formalizing lyric translation into a constrained translation problem, converting theoretical guidance and practical techniques from translatology literature to prompt-driven NMT approaches, exploring better adaptation methods, and instantiating them to an English-Chinese lyric translation system. Our model achieves 99.85%, 99.00%, and 95.52% on length accuracy, rhyme accuracy, and word boundary recall. In our subjective evaluation, our model shows a 75% relative enhancement on overall quality, compared against naive fine-tuning (Code available at https://github.com/Sonata165/ControllableLyricTranslation).
Deep Audio-Visual Singing Voice Transcription based on Self-Supervised Learning Models
Apr 24, 2023



Singing voice transcription converts recorded singing audio to musical notation. Sound contamination (such as accompaniment) and lack of annotated data make singing voice transcription an extremely difficult task. We take two approaches to tackle the above challenges: 1) introducing multimodal learning for singing voice transcription together with a new multimodal singing dataset, N20EMv2, enhancing noise robustness by utilizing video information (lip movements to predict the onset/offset of notes), and 2) adapting self-supervised learning models from the speech domain to the singing voice transcription task, significantly reducing annotated data requirements while preserving pretrained features. We build a self-supervised learning based audio-only singing voice transcription system, which not only outperforms current state-of-the-art technologies as a strong baseline, but also generalizes well to out-of-domain singing data. We then develop a self-supervised learning based video-only singing voice transcription system that detects note onsets and offsets with an accuracy of about 80\%. Finally, based on the powerful acoustic and visual representations extracted by the above two systems as well as the feature fusion design, we create an audio-visual singing voice transcription system that improves the noise robustness significantly under different acoustic environments compared to the audio-only systems.
Towards Transfer Learning of wav2vec 2.0 for Automatic Lyric Transcription
Jul 20, 2022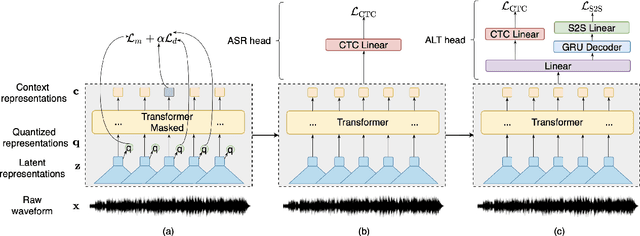
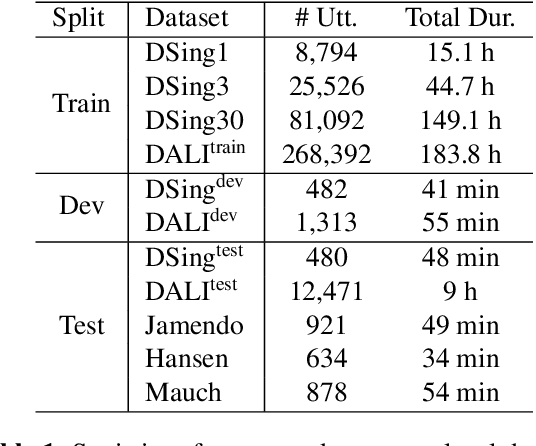

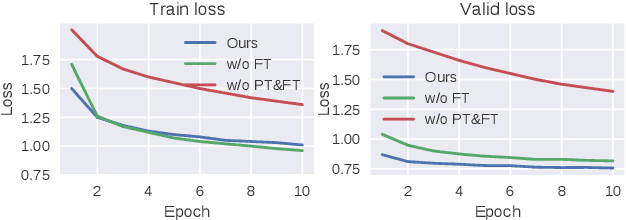
Automatic speech recognition (ASR) has progressed significantly in recent years due to large-scale datasets and the paradigm of self-supervised learning (SSL) methods. However, as its counterpart problem in the singing domain, automatic lyric transcription (ALT) suffers from limited data and degraded intelligibility of sung lyrics, which has caused it to develop at a slower pace. To fill in the performance gap between ALT and ASR, we attempt to exploit the similarities between speech and singing. In this work, we propose a transfer-learning-based ALT solution that takes advantage of these similarities by adapting wav2vec 2.0, an SSL ASR model, to the singing domain. We maximize the effectiveness of transfer learning by exploring the influence of different transfer starting points. We further enhance the performance by extending the original CTC model to a hybrid CTC/attention model. Our method surpasses previous approaches by a large margin on various ALT benchmark datasets. Further experiment shows that, with even a tiny proportion of training data, our method still achieves competitive performance.
MM-ALT: A Multimodal Automatic Lyric Transcription System
Jul 13, 2022
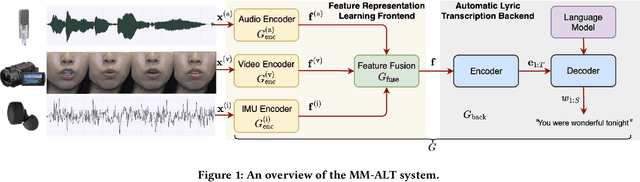
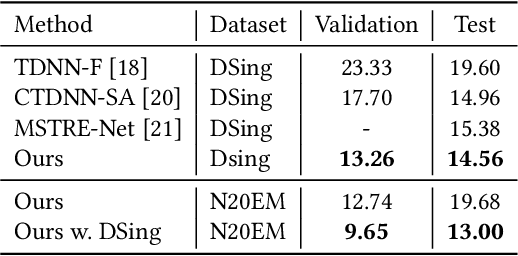
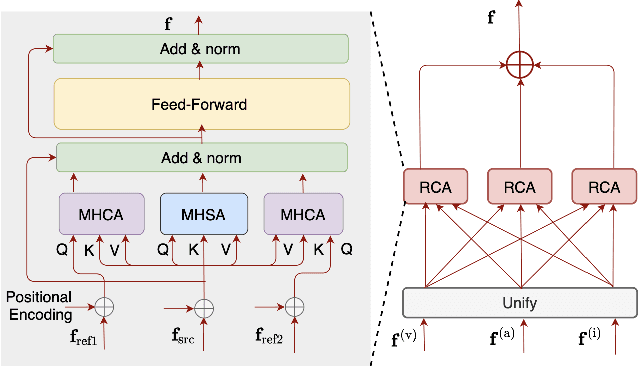
Automatic lyric transcription (ALT) is a nascent field of study attracting increasing interest from both the speech and music information retrieval communities, given its significant application potential. However, ALT with audio data alone is a notoriously difficult task due to instrumental accompaniment and musical constraints resulting in degradation of both the phonetic cues and the intelligibility of sung lyrics. To tackle this challenge, we propose the MultiModal Automatic Lyric Transcription system (MM-ALT), together with a new dataset, N20EM, which consists of audio recordings, videos of lip movements, and inertial measurement unit (IMU) data of an earbud worn by the performing singer. We first adapt the wav2vec 2.0 framework from automatic speech recognition (ASR) to the ALT task. We then propose a video-based ALT method and an IMU-based voice activity detection (VAD) method. In addition, we put forward the Residual Cross Attention (RCA) mechanism to fuse data from the three modalities (i.e., audio, video, and IMU). Experiments show the effectiveness of our proposed MM-ALT system, especially in terms of noise robustness.
Exploring Transformer's potential on automatic piano transcription
Apr 08, 2022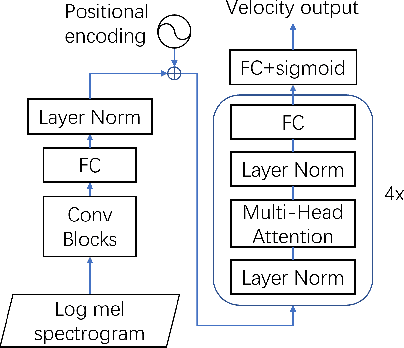

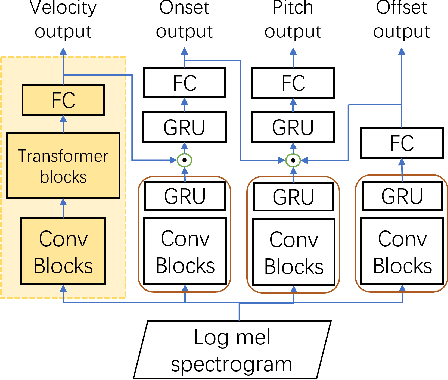
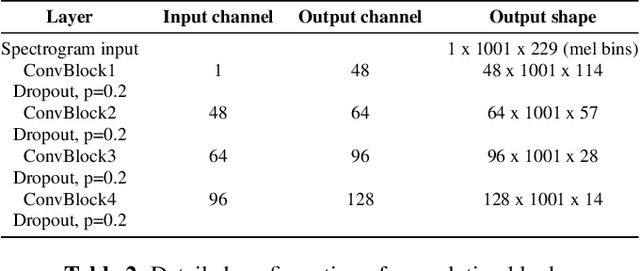
Most recent research about automatic music transcription (AMT) uses convolutional neural networks and recurrent neural networks to model the mapping from music signals to symbolic notation. Based on a high-resolution piano transcription system, we explore the possibility of incorporating another powerful sequence transformation tool -- the Transformer -- to deal with the AMT problem. We argue that the properties of the Transformer make it more suitable for certain AMT subtasks. We confirm the Transformer's superiority on the velocity detection task by experiments on the MAESTRO dataset and a cross-dataset evaluation on the MAPS dataset. We observe a performance improvement on both frame-level and note-level metrics after introducing the Transformer network.
Automatic Hyper-Parameter Optimization Based on Mapping Discovery from Data to Hyper-Parameters
Mar 03, 2020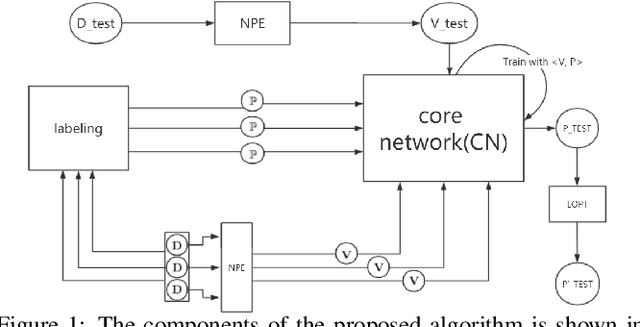
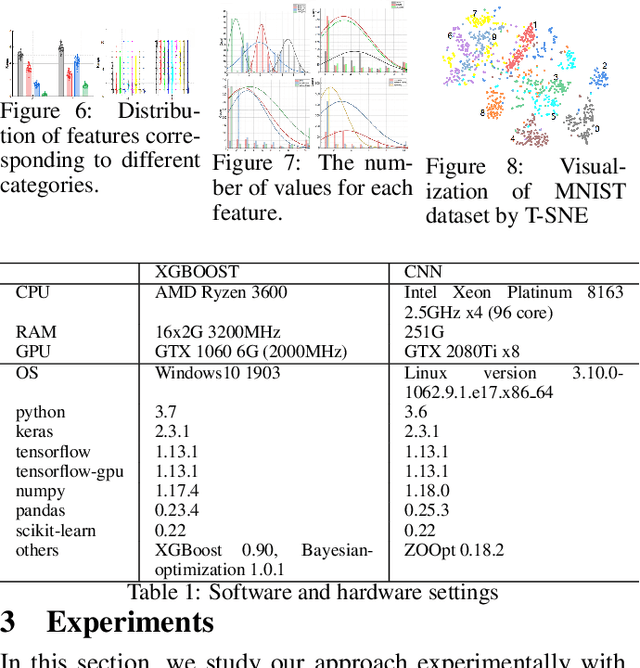
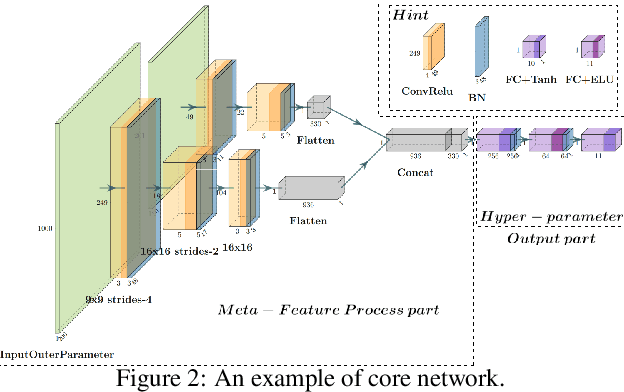
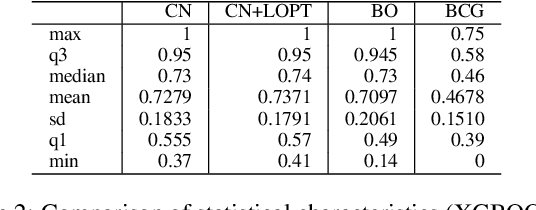
Machine learning algorithms have made remarkable achievements in the field of artificial intelligence. However, most machine learning algorithms are sensitive to the hyper-parameters. Manually optimizing the hyper-parameters is a common method of hyper-parameter tuning. However, it is costly and empirically dependent. Automatic hyper-parameter optimization (autoHPO) is favored due to its effectiveness. However, current autoHPO methods are usually only effective for a certain type of problems, and the time cost is high. In this paper, we propose an efficient automatic parameter optimization approach, which is based on the mapping from data to the corresponding hyper-parameters. To describe such mapping, we propose a sophisticated network structure. To obtain such mapping, we develop effective network constrution algorithms. We also design strategy to optimize the result futher during the application of the mapping. Extensive experimental results demonstrate that the proposed approaches outperform the state-of-the-art apporaches significantly.