 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLOAF-M2L: Joint Learning of Wording and Formatting for Singable Melody-to-Lyric Generation
Paper and Code
Jul 05, 2023
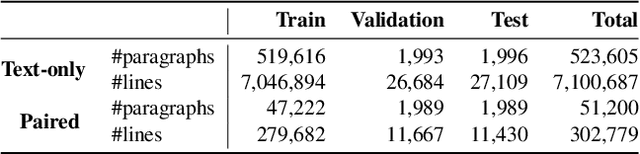

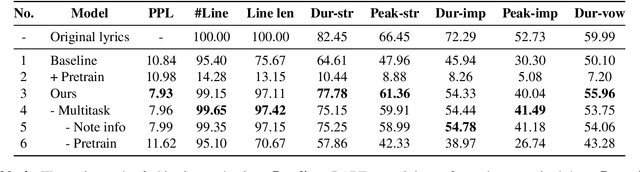
Despite previous efforts in melody-to-lyric generation research, there is still a significant compatibility gap between generated lyrics and melodies, negatively impacting the singability of the outputs. This paper bridges the singability gap with a novel approach to generating singable lyrics by jointly Learning wOrding And Formatting during Melody-to-Lyric training (LOAF-M2L). After general-domain pretraining, our proposed model acquires length awareness first from a large text-only lyric corpus. Then, we introduce a new objective informed by musicological research on the relationship between melody and lyrics during melody-to-lyric training, which enables the model to learn the fine-grained format requirements of the melody. Our model achieves 3.75% and 21.44% absolute accuracy gains in the outputs' number-of-line and syllable-per-line requirements compared to naive fine-tuning, without sacrificing text fluency. Furthermore, our model demonstrates a 63.92% and 74.18% relative improvement of music-lyric compatibility and overall quality in the subjective evaluation, compared to the state-of-the-art melody-to-lyric generation model, highlighting the significance of formatting learning.