 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLOAF-M2L: Joint Learning of Wording and Formatting for Singable Melody-to-Lyric Generation
Jul 05, 2023
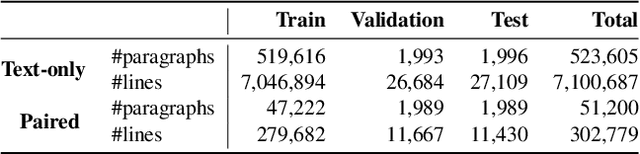

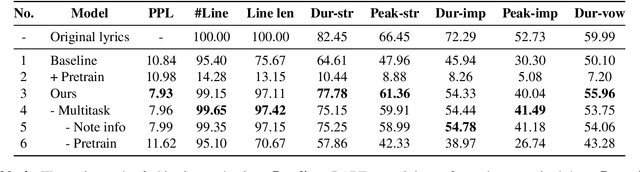
Despite previous efforts in melody-to-lyric generation research, there is still a significant compatibility gap between generated lyrics and melodies, negatively impacting the singability of the outputs. This paper bridges the singability gap with a novel approach to generating singable lyrics by jointly Learning wOrding And Formatting during Melody-to-Lyric training (LOAF-M2L). After general-domain pretraining, our proposed model acquires length awareness first from a large text-only lyric corpus. Then, we introduce a new objective informed by musicological research on the relationship between melody and lyrics during melody-to-lyric training, which enables the model to learn the fine-grained format requirements of the melody. Our model achieves 3.75% and 21.44% absolute accuracy gains in the outputs' number-of-line and syllable-per-line requirements compared to naive fine-tuning, without sacrificing text fluency. Furthermore, our model demonstrates a 63.92% and 74.18% relative improvement of music-lyric compatibility and overall quality in the subjective evaluation, compared to the state-of-the-art melody-to-lyric generation model, highlighting the significance of formatting learning.
Songs Across Borders: Singable and Controllable Neural Lyric Translation
May 26, 2023


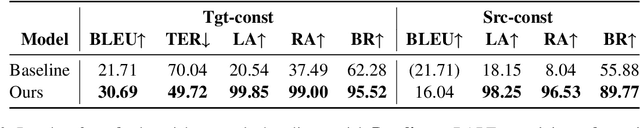
The development of general-domain neural machine translation (NMT) methods has advanced significantly in recent years, but the lack of naturalness and musical constraints in the outputs makes them unable to produce singable lyric translations. This paper bridges the singability quality gap by formalizing lyric translation into a constrained translation problem, converting theoretical guidance and practical techniques from translatology literature to prompt-driven NMT approaches, exploring better adaptation methods, and instantiating them to an English-Chinese lyric translation system. Our model achieves 99.85%, 99.00%, and 95.52% on length accuracy, rhyme accuracy, and word boundary recall. In our subjective evaluation, our model shows a 75% relative enhancement on overall quality, compared against naive fine-tuning (Code available at https://github.com/Sonata165/ControllableLyricTranslation).
Personalized Popular Music Generation Using Imitation and Structure
May 10, 2021

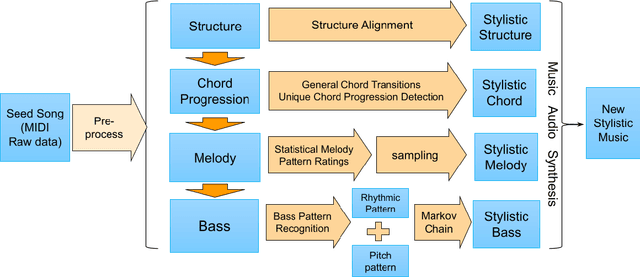

Many practices have been presented in music generation recently. While stylistic music generation using deep learning techniques has became the main stream, these models still struggle to generate music with high musicality, different levels of music structure, and controllability. In addition, more application scenarios such as music therapy require imitating more specific musical styles from a few given music examples, rather than capturing the overall genre style of a large data corpus. To address requirements that challenge current deep learning methods, we propose a statistical machine learning model that is able to capture and imitate the structure, melody, chord, and bass style from a given example seed song. An evaluation using 10 pop songs shows that our new representations and methods are able to create high-quality stylistic music that is similar to a given input song. We also discuss potential uses of our approach in music evaluation and music therapy.