 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Expand Images for Efficient Visual Autoregressive Modeling
Nov 19, 2025Autoregressive models have recently shown great promise in visual generation by leveraging discrete token sequences akin to language modeling. However, existing approaches often suffer from inefficiency, either due to token-by-token decoding or the complexity of multi-scale representations. In this work, we introduce Expanding Autoregressive Representation (EAR), a novel generation paradigm that emulates the human visual system's center-outward perception pattern. EAR unfolds image tokens in a spiral order from the center and progressively expands outward, preserving spatial continuity and enabling efficient parallel decoding. To further enhance flexibility and speed, we propose a length-adaptive decoding strategy that dynamically adjusts the number of tokens predicted at each step. This biologically inspired design not only reduces computational cost but also improves generation quality by aligning the generation order with perceptual relevance. Extensive experiments on ImageNet demonstrate that EAR achieves state-of-the-art trade-offs between fidelity and efficiency on single-scale autoregressive models, setting a new direction for scalable and cognitively aligned autoregressive image generation.
ActVAR: Activating Mixtures of Weights and Tokens for Efficient Visual Autoregressive Generation
Nov 17, 2025Visual Autoregressive (VAR) models enable efficient image generation via next-scale prediction but face escalating computational costs as sequence length grows. Existing static pruning methods degrade performance by permanently removing weights or tokens, disrupting pretrained dependencies. To address this, we propose ActVAR, a dynamic activation framework that introduces dual sparsity across model weights and token sequences to enhance efficiency without sacrificing capacity. ActVAR decomposes feedforward networks (FFNs) into lightweight expert sub-networks and employs a learnable router to dynamically select token-specific expert subsets based on content. Simultaneously, a gated token selector identifies high-update-potential tokens for computation while reconstructing unselected tokens to preserve global context and sequence alignment. Training employs a two-stage knowledge distillation strategy, where the original VAR model supervises the learning of routing and gating policies to align with pretrained knowledge. Experiments on the ImageNet $256\times 256$ benchmark demonstrate that ActVAR achieves up to $21.2\%$ FLOPs reduction with minimal performance degradation.
$\mathbf{S^2LM}$: Towards Semantic Steganography via Large Language Models
Nov 07, 2025Although steganography has made significant advancements in recent years, it still struggles to embed semantically rich, sentence-level information into carriers. However, in the era of AIGC, the capacity of steganography is more critical than ever. In this work, we present Sentence-to-Image Steganography, an instance of Semantic Steganography, a novel task that enables the hiding of arbitrary sentence-level messages within a cover image. Furthermore, we establish a benchmark named Invisible Text (IVT), comprising a diverse set of sentence-level texts as secret messages for evaluation. Finally, we present $\mathbf{S^2LM}$: Semantic Steganographic Language Model, which utilizes large language models (LLMs) to embed high-level textual information, such as sentences or even paragraphs, into images. Unlike traditional bit-level counterparts, $\mathrm{S^2LM}$ enables the integration of semantically rich content through a newly designed pipeline in which the LLM is involved throughout the entire process. Both quantitative and qualitative experiments demonstrate that our method effectively unlocks new semantic steganographic capabilities for LLMs. The source code will be released soon.
DistJoin: A Decoupled Join Cardinality Estimator based on Adaptive Neural Predicate Modulation
Mar 12, 2025Research on learned cardinality estimation has achieved significant progress in recent years. However, existing methods still face distinct challenges that hinder their practical deployment in production environments. We conceptualize these challenges as the "Trilemma of Cardinality Estimation", where learned cardinality estimation methods struggle to balance generality, accuracy, and updatability. To address these challenges, we introduce DistJoin, a join cardinality estimator based on efficient distribution prediction using multi-autoregressive models. Our contributions are threefold: (1) We propose a method for estimating both equi and non-equi join cardinality by leveraging the conditional probability distributions of individual tables in a decoupled manner. (2) To meet the requirements of efficient training and inference for DistJoin, we develop Adaptive Neural Predicate Modulation (ANPM), a high-throughput conditional probability distribution estimation model. (3) We formally analyze the variance of existing similar methods and demonstrate that such approaches suffer from variance accumulation issues. To mitigate this problem, DistJoin employs a selectivity-based approach rather than a count-based approach to infer join cardinality, effectively reducing variance. In summary, DistJoin not only represents the first data-driven method to effectively support both equi and non-equi joins but also demonstrates superior accuracy while enabling fast and flexible updates. We evaluate DistJoin on JOB-light and JOB-light-ranges, extending the evaluation to non-equi join conditions. The results demonstrate that our approach achieves the highest accuracy, robustness to data updates, generality, and comparable update and inference speed relative to existing methods.
MERLIN: Multi-stagE query performance prediction for dynamic paRallel oLap pIpeliNe
Dec 01, 2024High-performance OLAP database technology has emerged with the growing demand for massive data analysis. To achieve much higher performance, many DBMSs adopt sophisticated designs including SIMD operators, parallel execution, and dynamic pipeline modification. However, such advanced OLAP query execution mechanisms still lack targeted Query Performance Prediction (QPP) methods because most existing methods target conventional tree-shaped query plans and static serial executors. To address this problem, in this paper, we proposed MERLIN a multi-stage query performance prediction method for high-performance OLAP DBMSs. MERLIN first establishes resource cost models for each physical operator. Then, it constructs a DAG that consists of a data-flow tree backbone and resource competition relationships among concurrent operators. After using a GAT with an extra attention mechanism to calibrate the cost, the cost vector tree is extracted and summarized by a TCN, ultimately enabling effective query performance prediction. Experimental results demonstrate that MERLIN yields higher performance prediction precision than existing methods.
Diverse and Tailored Image Generation for Zero-shot Multi-label Classification
Apr 04, 2024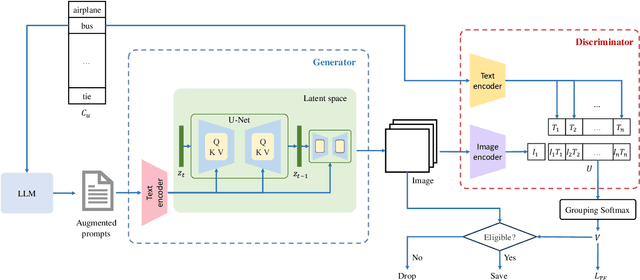
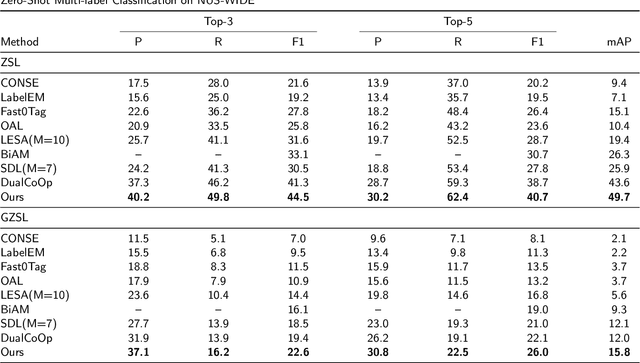

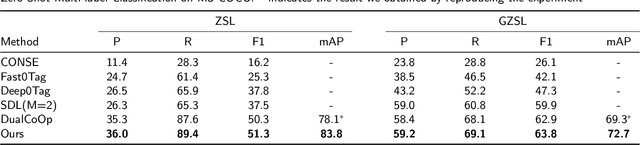
Recently, zero-shot multi-label classification has garnered considerable attention for its capacity to operate predictions on unseen labels without human annotations. Nevertheless, prevailing approaches often use seen classes as imperfect proxies for unseen ones, resulting in suboptimal performance. Drawing inspiration from the success of text-to-image generation models in producing realistic images, we propose an innovative solution: generating synthetic data to construct a training set explicitly tailored for proxyless training on unseen labels. Our approach introduces a novel image generation framework that produces multi-label synthetic images of unseen classes for classifier training. To enhance diversity in the generated images, we leverage a pre-trained large language model to generate diverse prompts. Employing a pre-trained multi-modal CLIP model as a discriminator, we assess whether the generated images accurately represent the target classes. This enables automatic filtering of inaccurately generated images, preserving classifier accuracy. To refine text prompts for more precise and effective multi-label object generation, we introduce a CLIP score-based discriminative loss to fine-tune the text encoder in the diffusion model. Additionally, to enhance visual features on the target task while maintaining the generalization of original features and mitigating catastrophic forgetting resulting from fine-tuning the entire visual encoder, we propose a feature fusion module inspired by transformer attention mechanisms. This module aids in capturing global dependencies between multiple objects more effectively. Extensive experimental results validate the effectiveness of our approach, demonstrating significant improvements over state-of-the-art methods.
Duet: efficient and scalable hybriD neUral rElation undersTanding
Jul 28, 2023Learned cardinality estimation methods have achieved high precision compared to traditional methods. Among learned methods, query-driven approaches face the data and workload drift problem for a long time. Although both query-driven and hybrid methods are proposed to avoid this problem, even the state-of-the-art of them suffer from high training and estimation costs, limited scalability, instability, and long-tailed distribution problem on high cardinality and high-dimensional tables, which seriously affects the practical application of learned cardinality estimators. In this paper, we prove that most of these problems are directly caused by the widely used progressive sampling. We solve this problem by introducing predicates information into the autoregressive model and propose Duet, a stable, efficient, and scalable hybrid method to estimate cardinality directly without sampling or any non-differentiable process, which can not only reduces the inference complexity from O(n) to O(1) compared to Naru and UAE but also achieve higher accuracy on high cardinality and high-dimensional tables. Experimental results show that Duet can achieve all the design goals above and be much more practical and even has a lower inference cost on CPU than that of most learned methods on GPU.
Positive Label Is All You Need for Multi-Label Classification
Jun 28, 2023Multi-label classification (MLC) suffers from the inevitable label noise in training data due to the difficulty in annotating various semantic labels in each image. To mitigate the influence of noisy labels, existing methods mainly devote to identifying and correcting the label mistakes via a trained MLC model. However, these methods still involve annoying noisy labels in training, which can result in imprecise recognition of noisy labels and weaken the performance. In this paper, considering that the negative labels are substantially more than positive labels, and most noisy labels are from the negative labels, we directly discard all the negative labels in the dataset, and propose a new method dubbed positive and unlabeled multi-label classification (PU-MLC). By extending positive-unlabeled learning into MLC task, our method trains model with only positive labels and unlabeled data, and introduces adaptive re-balance factor and adaptive temperature coefficient in the loss function to alleviate the catastrophic imbalance in label distribution and over-smoothing of probabilities in training. Our PU-MLC is simple and effective, and it is applicable to both MLC and MLC with partial labels (MLC-PL) tasks. Extensive experiments on MS-COCO and PASCAL VOC datasets demonstrate that our PU-MLC achieves significantly improvements on both MLC and MLC-PL settings with even fewer annotations. Code will be released.
TENSILE: A Tensor granularity dynamic GPU memory scheduler method towards multiple dynamic workloads system
May 28, 2021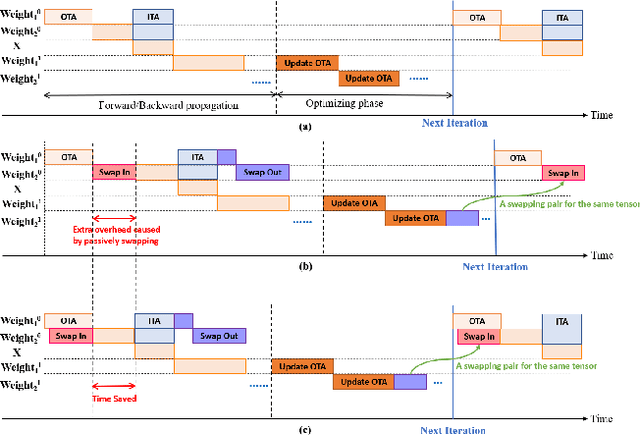
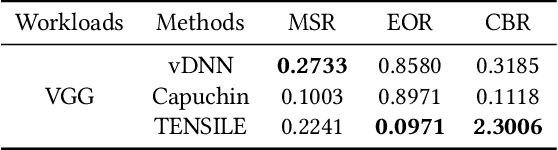
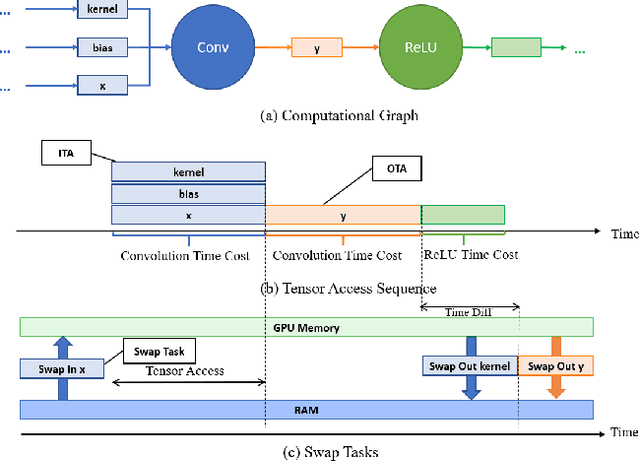

Recently, deep learning has been an area of intense researching. However, as a kind of computing intensive task, deep learning highly relies on the the scale of the GPU memory, which is usually expensive and scarce. Although there are some extensive works have been proposed for dynamic GPU memory management, they are hard to be applied to systems with multitasking dynamic workloads, such as in-database machine learning system. In this paper, we demonstrated TENSILE, a method of managing GPU memory in tensor granularity to reduce the GPU memory peak, with taking the multitasking dynamic workloads into consideration. As far as we know, TENSILE is the first method which is designed to manage multiple workloads' GPU memory using. We implement TENSILE on our own deep learning framework, and evaluated its performance. The experiment results shows that our method can achieve less time overhead than prior works with more GPU memory saved.
A parallel-network continuous quantitative trading model with GARCH and PPO
May 21, 2021


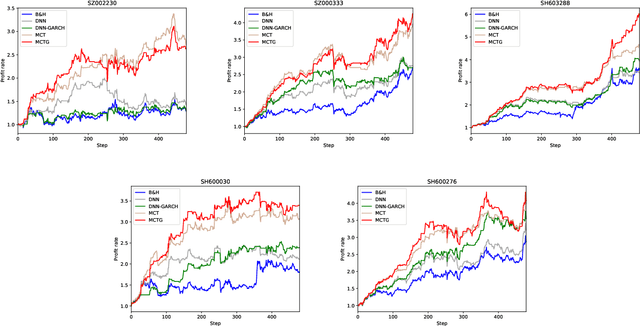
It is a difficult task for both professional investors and individual traders continuously making profit in stock market. With the development of computer science and deep reinforcement learning, Buy\&Hold (B\&H) has been oversteped by many artificial intelligence trading algorithms. However, the information and process are not enough, which limit the performance of reinforcement learning algorithms. Thus, we propose a parallel-network continuous quantitative trading model with GARCH and PPO to enrich the basical deep reinforcement learning model, where the deep learning parallel network layers deal with 3 different frequencies data (including GARCH information) and proximal policy optimization (PPO) algorithm interacts actions and rewards with stock trading environment. Experiments in 5 stocks from Chinese stock market show our method achieves more extra profit comparing with basical reinforcement learning methods and bench models.