 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse and Tailored Image Generation for Zero-shot Multi-label Classification
Apr 04, 2024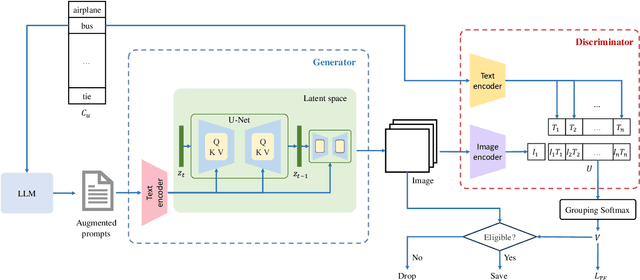
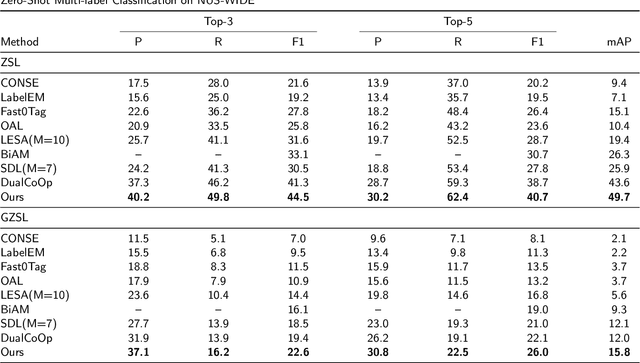

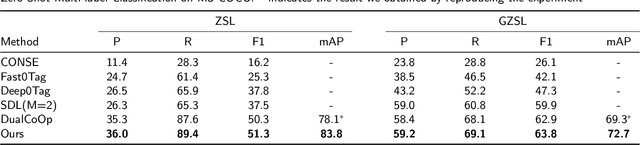
Recently, zero-shot multi-label classification has garnered considerable attention for its capacity to operate predictions on unseen labels without human annotations. Nevertheless, prevailing approaches often use seen classes as imperfect proxies for unseen ones, resulting in suboptimal performance. Drawing inspiration from the success of text-to-image generation models in producing realistic images, we propose an innovative solution: generating synthetic data to construct a training set explicitly tailored for proxyless training on unseen labels. Our approach introduces a novel image generation framework that produces multi-label synthetic images of unseen classes for classifier training. To enhance diversity in the generated images, we leverage a pre-trained large language model to generate diverse prompts. Employing a pre-trained multi-modal CLIP model as a discriminator, we assess whether the generated images accurately represent the target classes. This enables automatic filtering of inaccurately generated images, preserving classifier accuracy. To refine text prompts for more precise and effective multi-label object generation, we introduce a CLIP score-based discriminative loss to fine-tune the text encoder in the diffusion model. Additionally, to enhance visual features on the target task while maintaining the generalization of original features and mitigating catastrophic forgetting resulting from fine-tuning the entire visual encoder, we propose a feature fusion module inspired by transformer attention mechanisms. This module aids in capturing global dependencies between multiple objects more effectively. Extensive experimental results validate the effectiveness of our approach, demonstrating significant improvements over state-of-the-art methods.
Positive Label Is All You Need for Multi-Label Classification
Jun 28, 2023Multi-label classification (MLC) suffers from the inevitable label noise in training data due to the difficulty in annotating various semantic labels in each image. To mitigate the influence of noisy labels, existing methods mainly devote to identifying and correcting the label mistakes via a trained MLC model. However, these methods still involve annoying noisy labels in training, which can result in imprecise recognition of noisy labels and weaken the performance. In this paper, considering that the negative labels are substantially more than positive labels, and most noisy labels are from the negative labels, we directly discard all the negative labels in the dataset, and propose a new method dubbed positive and unlabeled multi-label classification (PU-MLC). By extending positive-unlabeled learning into MLC task, our method trains model with only positive labels and unlabeled data, and introduces adaptive re-balance factor and adaptive temperature coefficient in the loss function to alleviate the catastrophic imbalance in label distribution and over-smoothing of probabilities in training. Our PU-MLC is simple and effective, and it is applicable to both MLC and MLC with partial labels (MLC-PL) tasks. Extensive experiments on MS-COCO and PASCAL VOC datasets demonstrate that our PU-MLC achieves significantly improvements on both MLC and MLC-PL settings with even fewer annotations. Code will be released.