 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Return-to-Go for Efficient Decision Transformer
Jan 22, 2026The Decision Transformer (DT) has established a powerful sequence modeling approach to offline reinforcement learning. It conditions its action predictions on Return-to-Go (RTG), using it both to distinguish trajectory quality during training and to guide action generation at inference. In this work, we identify a critical redundancy in this design: feeding the entire sequence of RTGs into the Transformer is theoretically unnecessary, as only the most recent RTG affects action prediction. We show that this redundancy can impair DT's performance through experiments. To resolve this, we propose the Decoupled DT (DDT). DDT simplifies the architecture by processing only observation and action sequences through the Transformer, using the latest RTG to guide the action prediction. This streamlined approach not only improves performance but also reduces computational cost. Our experiments show that DDT significantly outperforms DT and establishes competitive performance against state-of-the-art DT variants across multiple offline RL tasks.
Differentiable Self-Adaptive Learning Rate
Oct 19, 2022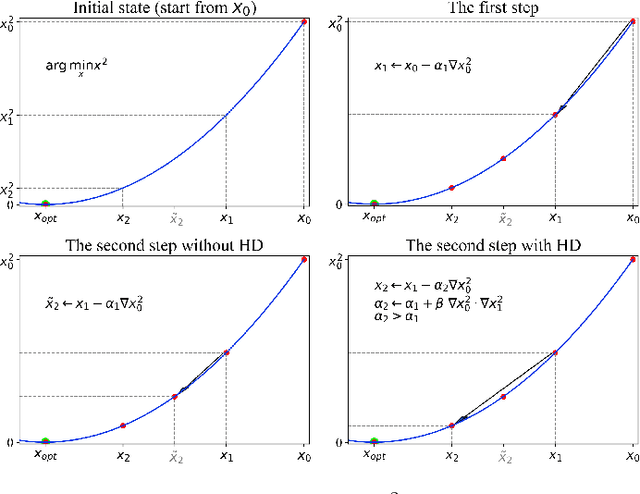

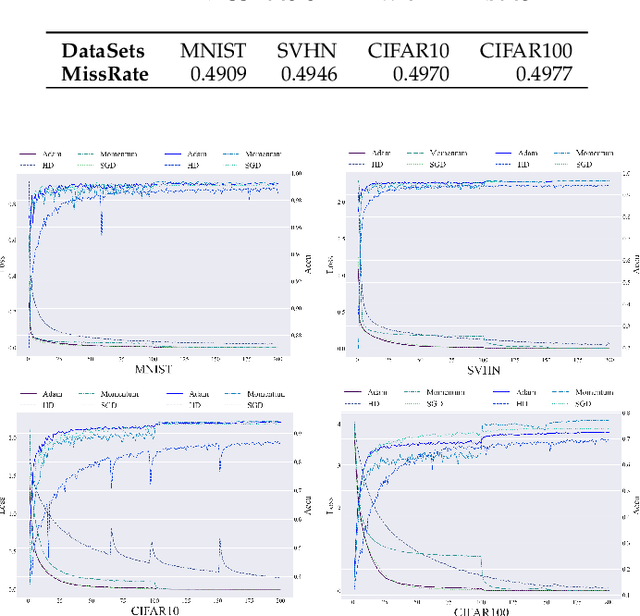

Learning rate adaptation is a popular topic in machine learning. Gradient Descent trains neural nerwork with a fixed learning rate. Learning rate adaptation is proposed to accelerate the training process through adjusting the step size in the training session. Famous works include Momentum, Adam and Hypergradient. Hypergradient is the most special one. Hypergradient achieved adaptation by calculating the derivative of learning rate with respect to cost function and utilizing gradient descent for learning rate. However, Hypergradient is still not perfect. In practice, Hypergradient fail to decrease training loss after learning rate adaptation with a large probability. Apart from that, evidence has been found that Hypergradient are not suitable for dealing with large datesets in the form of minibatch training. Most unfortunately, Hypergradient always fails to get a good accuracy on the validation dataset although it could reduce training loss to a very tiny value. To solve Hypergradient's problems, we propose a novel adaptation algorithm, where learning rate is parameter specific and internal structured. We conduct extensive experiments on multiple network models and datasets compared with various benchmark optimizers. It is shown that our algorithm can achieve faster and higher qualified convergence than those state-of-art optimizers.
FL-AGCNS: Federated Learning Framework for Automatic Graph Convolutional Network Search
Apr 09, 2021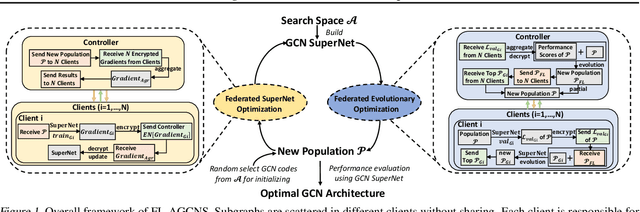
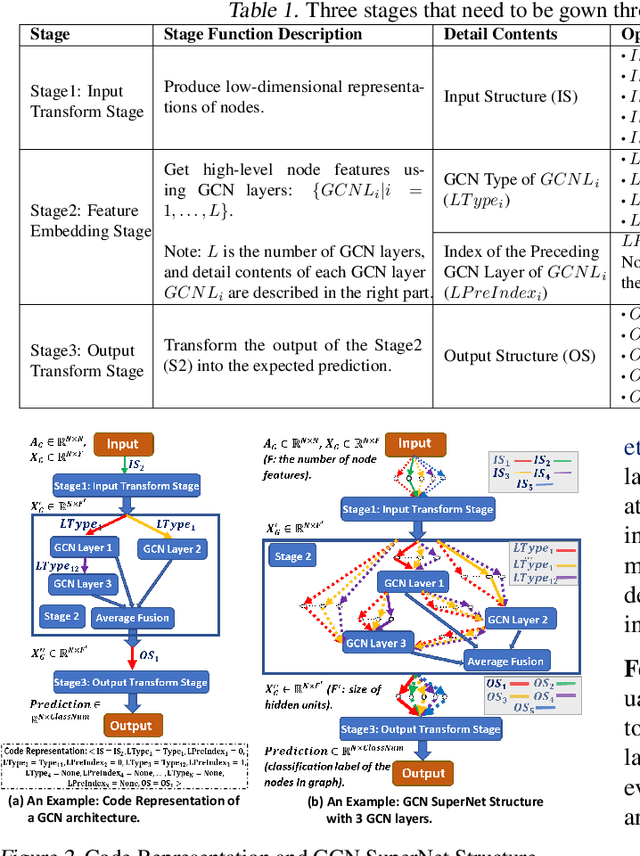

Recently, some Neural Architecture Search (NAS) techniques are proposed for the automatic design of Graph Convolutional Network (GCN) architectures. They bring great convenience to the use of GCN, but could hardly apply to the Federated Learning (FL) scenarios with distributed and private datasets, which limit their applications. Moreover, they need to train many candidate GCN models from scratch, which is inefficient for FL. To address these challenges, we propose FL-AGCNS, an efficient GCN NAS algorithm suitable for FL scenarios. FL-AGCNS designs a federated evolutionary optimization strategy to enable distributed agents to cooperatively design powerful GCN models while keeping personal information on local devices. Besides, it applies the GCN SuperNet and a weight sharing strategy to speed up the evaluation of GCN models. Experimental results show that FL-AGCNS can find better GCN models in short time under the FL framework, surpassing the state-of-the-arts NAS methods and GCN models.
Auto-STGCN: Autonomous Spatial-Temporal Graph Convolutional Network Search Based on Reinforcement Learning and Existing Research Results
Oct 15, 2020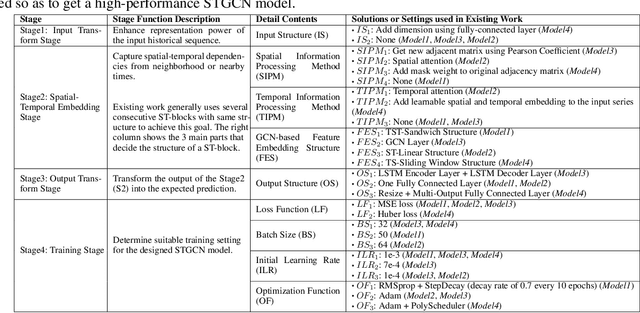
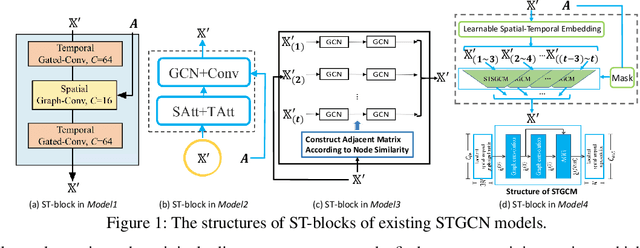
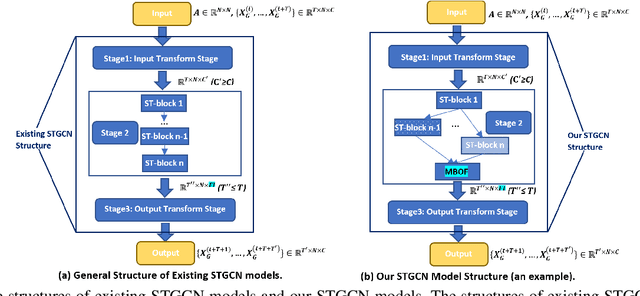
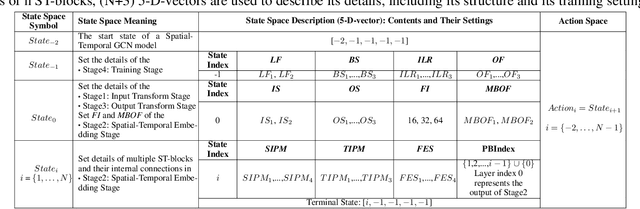
In recent years, many spatial-temporal graph convolutional network (STGCN) models are proposed to deal with the spatial-temporal network data forecasting problem. These STGCN models have their own advantages, i.e., each of them puts forward many effective operations and achieves good prediction results in the real applications. If users can effectively utilize and combine these excellent operations integrating the advantages of existing models, then they may obtain more effective STGCN models thus create greater value using existing work. However, they fail to do so due to the lack of domain knowledge, and there is lack of automated system to help users to achieve this goal. In this paper, we fill this gap and propose Auto-STGCN algorithm, which makes use of existing models to automatically explore high-performance STGCN model for specific scenarios. Specifically, we design Unified-STGCN framework, which summarizes the operations of existing architectures, and use parameters to control the usage and characteristic attributes of each operation, so as to realize the parameterized representation of the STGCN architecture and the reorganization and fusion of advantages. Then, we present Auto-STGCN, an optimization method based on reinforcement learning, to quickly search the parameter search space provided by Unified-STGCN, and generate optimal STGCN models automatically. Extensive experiments on real-world benchmark datasets show that our Auto-STGCN can find STGCN models superior to existing STGCN models with heuristic parameters, which demonstrates the effectiveness of our proposed method.
EM-RBR: a reinforced framework for knowledge graph completion from reasoning perspective
Oct 11, 2020



Knowledge graph completion aims to predict the new links in given entities among the knowledge graph (KG). Most mainstream embedding methods focus on fact triplets contained in the given KG, however, ignoring the rich background information provided by logic rules driven from knowledge base implicitly. To solve this problem, in this paper, we propose a general framework, named EM-RBR(embedding and rule-based reasoning), capable of combining the advantages of reasoning based on rules and the state-of-the-art models of embedding. EM-RBR aims to utilize relational background knowledge contained in rules to conduct multi-relation reasoning link prediction rather than superficial vector triangle linkage in embedding models. By this way, we can explore relation between two entities in deeper context to achieve higher accuracy. In experiments, we demonstrate that EM-RBR achieves better performance compared with previous models on FB15k, WN18 and our new dataset FB15k-R, especially the new dataset where our model perform futher better than those state-of-the-arts. We make the implementation of EM-RBR available at https://github.com/1173710224/link-prediction-with-rule-based-reasoning.
ConsciousControlFlow(CCF): A Demonstration for conscious Artificial Intelligence
Apr 09, 2020

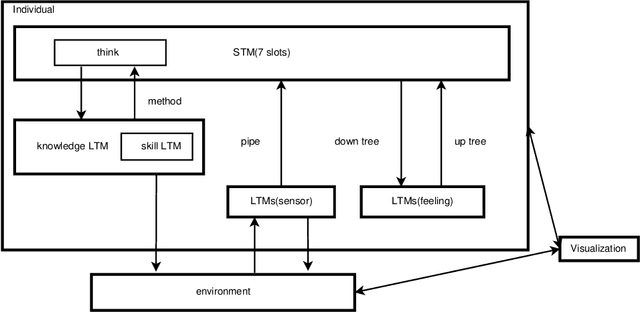

In this demo, we present ConsciousControlFlow(CCF), a prototype system to demonstrate conscious Artificial Intelligence (AI). The system is based on the computational model for consciousness and the hierarchy of needs. CCF supports typical scenarios to show the behaviors and the mental activities of conscious AI. We demonstrate that CCF provides a useful tool for effective machine consciousness demonstration and human behavior study assistance.
Automatic Hyper-Parameter Optimization Based on Mapping Discovery from Data to Hyper-Parameters
Mar 03, 2020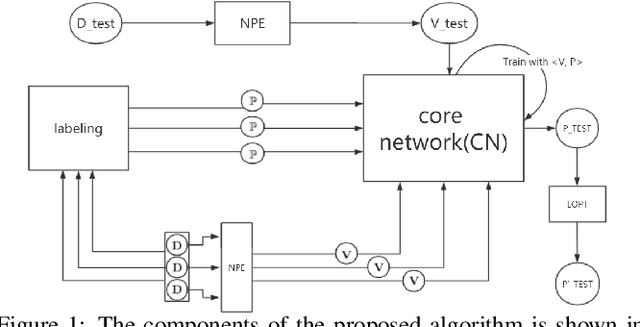
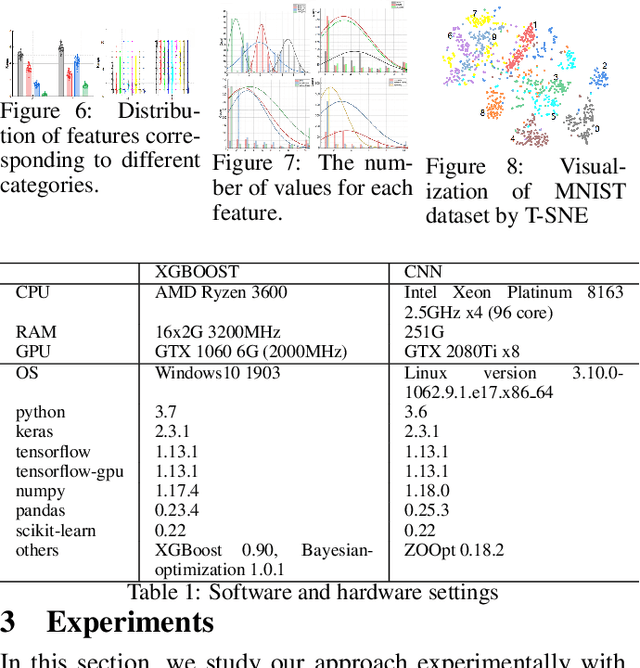
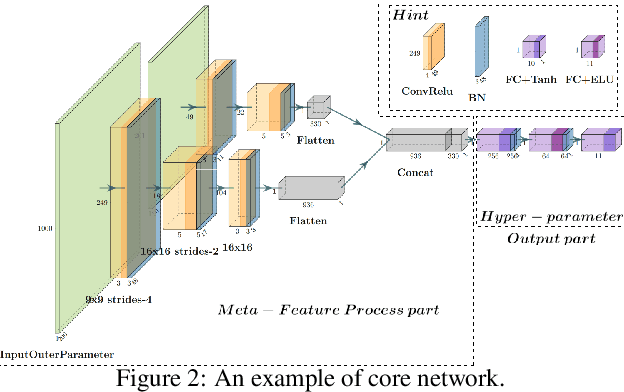
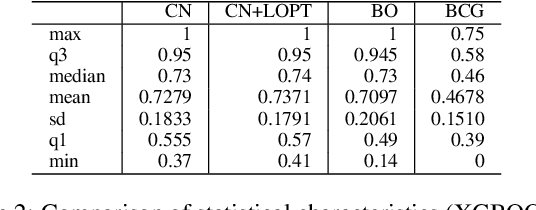
Machine learning algorithms have made remarkable achievements in the field of artificial intelligence. However, most machine learning algorithms are sensitive to the hyper-parameters. Manually optimizing the hyper-parameters is a common method of hyper-parameter tuning. However, it is costly and empirically dependent. Automatic hyper-parameter optimization (autoHPO) is favored due to its effectiveness. However, current autoHPO methods are usually only effective for a certain type of problems, and the time cost is high. In this paper, we propose an efficient automatic parameter optimization approach, which is based on the mapping from data to the corresponding hyper-parameters. To describe such mapping, we propose a sophisticated network structure. To obtain such mapping, we develop effective network constrution algorithms. We also design strategy to optimize the result futher during the application of the mapping. Extensive experimental results demonstrate that the proposed approaches outperform the state-of-the-art apporaches significantly.