 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustered regression with unknown clusters
Paper and Code
Mar 23, 2011
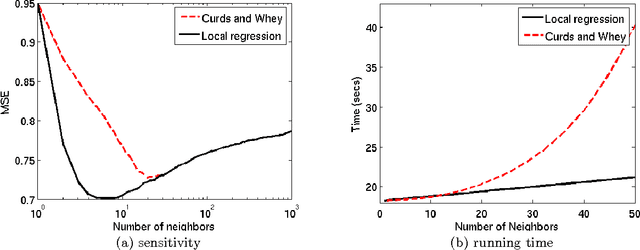
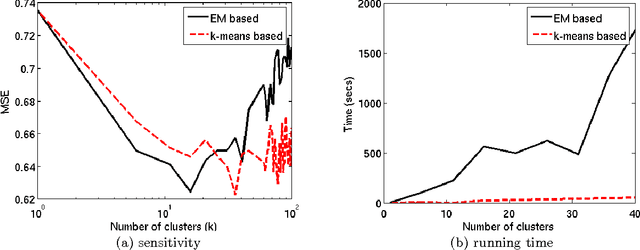

We consider a collection of prediction experiments, which are clustered in the sense that groups of experiments ex- hibit similar relationship between the predictor and response variables. The experiment clusters as well as the regres- sion relationships are unknown. The regression relation- ships define the experiment clusters, and in general, the predictor and response variables may not exhibit any clus- tering. We call this prediction problem clustered regres- sion with unknown clusters (CRUC) and in this paper we focus on linear regression. We study and compare several methods for CRUC, demonstrate their applicability to the Yahoo Learning-to-rank Challenge (YLRC) dataset, and in- vestigate an associated mathematical model. CRUC is at the crossroads of many prior works and we study several prediction algorithms with diverse origins: an adaptation of the expectation-maximization algorithm, an approach in- spired by K-means clustering, the singular value threshold- ing approach to matrix rank minimization under quadratic constraints, an adaptation of the Curds and Whey method in multiple regression, and a local regression (LoR) scheme reminiscent of neighborhood methods in collaborative filter- ing. Based on empirical evaluation on the YLRC dataset as well as simulated data, we identify the LoR method as a good practical choice: it yields best or near-best prediction performance at a reasonable computational load, and it is less sensitive to the choice of the algorithm parameter. We also provide some analysis of the LoR method for an asso- ciated mathematical model, which sheds light on optimal parameter choice and prediction performance.