 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Dataset Quality and Heterogeneity in Model Confidence
Paper and Code
Feb 23, 2020
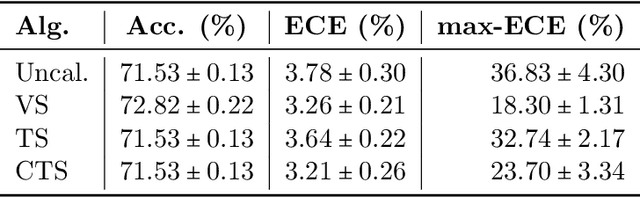


Safety-critical applications require machine learning models that output accurate and calibrated probabilities. While uncalibrated deep networks are known to make over-confident predictions, it is unclear how model confidence is impacted by the variations in the data, such as label noise or class size. In this paper, we investigate the role of the dataset quality by studying the impact of dataset size and the label noise on the model confidence. We theoretically explain and experimentally demonstrate that, surprisingly, label noise in the training data leads to under-confident networks, while reduced dataset size leads to over-confident models. We then study the impact of dataset heterogeneity, where data quality varies across classes, on model confidence. We demonstrate that this leads to heterogenous confidence/accuracy behavior in the test data and is poorly handled by the standard calibration algorithms. To overcome this, we propose an intuitive heterogenous calibration technique and show that the proposed approach leads to improved calibration metrics (both average and worst-case errors) on the CIFAR datasets.