 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Dataless Training of Neural Networks
Oct 29, 2025This paper surveys studies on the use of neural networks for optimization in the training-data-free setting. Specifically, we examine the dataless application of neural network architectures in optimization by re-parameterizing problems using fully connected (or MLP), convolutional, graph, and quadratic neural networks. Although MLPs have been used to solve linear programs a few decades ago, this approach has recently gained increasing attention due to its promising results across diverse applications, including those based on combinatorial optimization, inverse problems, and partial differential equations. The motivation for this setting stems from two key (possibly over-lapping) factors: (i) data-driven learning approaches are still underdeveloped and have yet to demonstrate strong results, as seen in combinatorial optimization, and (ii) the availability of training data is inherently limited, such as in medical image reconstruction and other scientific applications. In this paper, we define the dataless setting and categorize it into two variants based on how a problem instance -- defined by a single datum -- is encoded onto the neural network: (i) architecture-agnostic methods and (ii) architecture-specific methods. Additionally, we discuss similarities and clarify distinctions between the dataless neural network (dNN) settings and related concepts such as zero-shot learning, one-shot learning, lifting in optimization, and over-parameterization.
UGoDIT: Unsupervised Group Deep Image Prior Via Transferable Weights
May 16, 2025Recent advances in data-centric deep generative models have led to significant progress in solving inverse imaging problems. However, these models (e.g., diffusion models (DMs)) typically require large amounts of fully sampled (clean) training data, which is often impractical in medical and scientific settings such as dynamic imaging. On the other hand, training-data-free approaches like the Deep Image Prior (DIP) do not require clean ground-truth images but suffer from noise overfitting and can be computationally expensive as the network parameters need to be optimized for each measurement set independently. Moreover, DIP-based methods often overlook the potential of learning a prior using a small number of sub-sampled measurements (or degraded images) available during training. In this paper, we propose UGoDIT, an Unsupervised Group DIP via Transferable weights, designed for the low-data regime where only a very small number, M, of sub-sampled measurement vectors are available during training. Our method learns a set of transferable weights by optimizing a shared encoder and M disentangled decoders. At test time, we reconstruct the unseen degraded image using a DIP network, where part of the parameters are fixed to the learned weights, while the remaining are optimized to enforce measurement consistency. We evaluate UGoDIT on both medical (multi-coil MRI) and natural (super resolution and non-linear deblurring) image recovery tasks under various settings. Compared to recent standalone DIP methods, UGoDIT provides accelerated convergence and notable improvement in reconstruction quality. Furthermore, our method achieves performance competitive with SOTA DM-based and supervised approaches, despite not requiring large amounts of clean training data.
Structure-Preserving Network Compression Via Low-Rank Induced Training Through Linear Layers Composition
May 06, 2024



Deep Neural Networks (DNNs) have achieved remarkable success in addressing many previously unsolvable tasks. However, the storage and computational requirements associated with DNNs pose a challenge for deploying these trained models on resource-limited devices. Therefore, a plethora of compression and pruning techniques have been proposed in recent years. Low-rank decomposition techniques are among the approaches most utilized to address this problem. Compared to post-training compression, compression-promoted training is still under-explored. In this paper, we present a theoretically-justified novel approach, termed Low-Rank Induced Training (LoRITa), that promotes low-rankness through the composition of linear layers and compresses by using singular value truncation. This is achieved without the need to change the structure at inference time or require constrained and/or additional optimization, other than the standard weight decay regularization. Moreover, LoRITa eliminates the need to (i) initialize with pre-trained models and (ii) specify rank selection prior to training. Our experimental results (i) demonstrate the effectiveness of our approach using MNIST on Fully Connected Networks, CIFAR10 on Vision Transformers, and CIFAR10/100 on Convolutional Neural Networks, and (ii) illustrate that we achieve either competitive or SOTA results when compared to leading structured pruning methods in terms of FLOPs and parameters drop.
Decoupled Data Consistency with Diffusion Purification for Image Restoration
Mar 12, 2024Diffusion models have recently gained traction as a powerful class of deep generative priors, excelling in a wide range of image restoration tasks due to their exceptional ability to model data distributions. To solve image restoration problems, many existing techniques achieve data consistency by incorporating additional likelihood gradient steps into the reverse sampling process of diffusion models. However, the additional gradient steps pose a challenge for real-world practical applications as they incur a large computational overhead, thereby increasing inference time. They also present additional difficulties when using accelerated diffusion model samplers, as the number of data consistency steps is limited by the number of reverse sampling steps. In this work, we propose a novel diffusion-based image restoration solver that addresses these issues by decoupling the reverse process from the data consistency steps. Our method involves alternating between a reconstruction phase to maintain data consistency and a refinement phase that enforces the prior via diffusion purification. Our approach demonstrates versatility, making it highly adaptable for efficient problem-solving in latent space. Additionally, it reduces the necessity for numerous sampling steps through the integration of consistency models. The efficacy of our approach is validated through comprehensive experiments across various image restoration tasks, including image denoising, deblurring, inpainting, and super-resolution.
A Differentiable Approach to Combinatorial Optimization using Dataless Neural Networks
Mar 15, 2022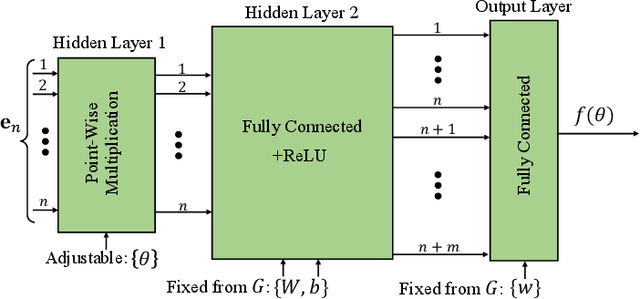
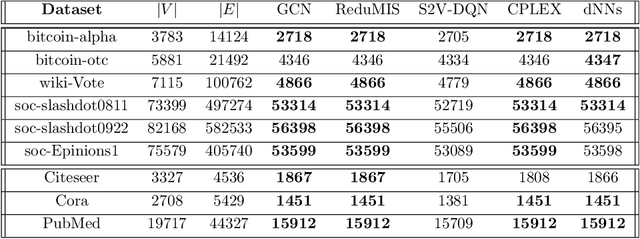
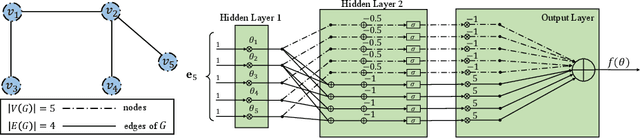
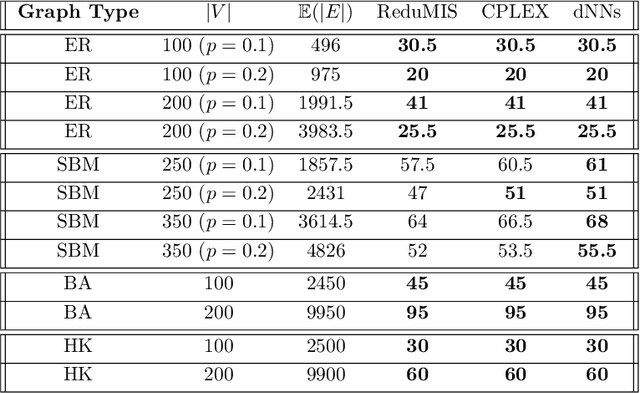
The success of machine learning solutions for reasoning about discrete structures has brought attention to its adoption within combinatorial optimization algorithms. Such approaches generally rely on supervised learning by leveraging datasets of the combinatorial structures of interest drawn from some distribution of problem instances. Reinforcement learning has also been employed to find such structures. In this paper, we propose a radically different approach in that no data is required for training the neural networks that produce the solution. In particular, we reduce the combinatorial optimization problem to a neural network and employ a dataless training scheme to refine the parameters of the network such that those parameters yield the structure of interest. We consider the combinatorial optimization problems of finding maximum independent sets and maximum cliques in a graph. In principle, since these problems belong to the NP-hard complexity class, our proposed approach can be used to solve any other NP-hard problem. Additionally, we propose a universal graph reduction procedure to handle large scale graphs. The reduction exploits community detection for graph partitioning and is applicable to any graph type and/or density. Experimental evaluation on both synthetic graphs and real-world benchmarks demonstrates that our method performs on par with or outperforms state-of-the-art heuristic, reinforcement learning, and machine learning based methods without requiring any data.