 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSWorld: Closed-Loop Photo-Realistic Simulation Suite for Robotic Manipulation
Oct 23, 2025This paper presents GSWorld, a robust, photo-realistic simulator for robotics manipulation that combines 3D Gaussian Splatting with physics engines. Our framework advocates "closing the loop" of developing manipulation policies with reproducible evaluation of policies learned from real-robot data and sim2real policy training without using real robots. To enable photo-realistic rendering of diverse scenes, we propose a new asset format, which we term GSDF (Gaussian Scene Description File), that infuses Gaussian-on-Mesh representation with robot URDF and other objects. With a streamlined reconstruction pipeline, we curate a database of GSDF that contains 3 robot embodiments for single-arm and bimanual manipulation, as well as more than 40 objects. Combining GSDF with physics engines, we demonstrate several immediate interesting applications: (1) learning zero-shot sim2real pixel-to-action manipulation policy with photo-realistic rendering, (2) automated high-quality DAgger data collection for adapting policies to deployment environments, (3) reproducible benchmarking of real-robot manipulation policies in simulation, (4) simulation data collection by virtual teleoperation, and (5) zero-shot sim2real visual reinforcement learning. Website: https://3dgsworld.github.io/.
Bunny-VisionPro: Real-Time Bimanual Dexterous Teleoperation for Imitation Learning
Jul 03, 2024Teleoperation is a crucial tool for collecting human demonstrations, but controlling robots with bimanual dexterous hands remains a challenge. Existing teleoperation systems struggle to handle the complexity of coordinating two hands for intricate manipulations. We introduce Bunny-VisionPro, a real-time bimanual dexterous teleoperation system that leverages a VR headset. Unlike previous vision-based teleoperation systems, we design novel low-cost devices to provide haptic feedback to the operator, enhancing immersion. Our system prioritizes safety by incorporating collision and singularity avoidance while maintaining real-time performance through innovative designs. Bunny-VisionPro outperforms prior systems on a standard task suite, achieving higher success rates and reduced task completion times. Moreover, the high-quality teleoperation demonstrations improve downstream imitation learning performance, leading to better generalizability. Notably, Bunny-VisionPro enables imitation learning with challenging multi-stage, long-horizon dexterous manipulation tasks, which have rarely been addressed in previous work. Our system's ability to handle bimanual manipulations while prioritizing safety and real-time performance makes it a powerful tool for advancing dexterous manipulation and imitation learning.
TransNet: Transparent Object Manipulation Through Category-Level Pose Estimation
Jul 23, 2023



Transparent objects present multiple distinct challenges to visual perception systems. First, their lack of distinguishing visual features makes transparent objects harder to detect and localize than opaque objects. Even humans find certain transparent surfaces with little specular reflection or refraction, like glass doors, difficult to perceive. A second challenge is that depth sensors typically used for opaque object perception cannot obtain accurate depth measurements on transparent surfaces due to their unique reflective properties. Stemming from these challenges, we observe that transparent object instances within the same category, such as cups, look more similar to each other than to ordinary opaque objects of that same category. Given this observation, the present paper explores the possibility of category-level transparent object pose estimation rather than instance-level pose estimation. We propose \textit{\textbf{TransNet}}, a two-stage pipeline that estimates category-level transparent object pose using localized depth completion and surface normal estimation. TransNet is evaluated in terms of pose estimation accuracy on a large-scale transparent object dataset and compared to a state-of-the-art category-level pose estimation approach. Results from this comparison demonstrate that TransNet achieves improved pose estimation accuracy on transparent objects. Moreover, we use TransNet to build an autonomous transparent object manipulation system for robotic pick-and-place and pouring tasks.
TransNet: Category-Level Transparent Object Pose Estimation
Aug 22, 2022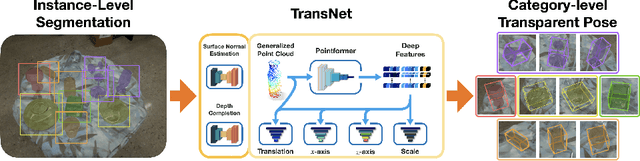



Transparent objects present multiple distinct challenges to visual perception systems. First, their lack of distinguishing visual features makes transparent objects harder to detect and localize than opaque objects. Even humans find certain transparent surfaces with little specular reflection or refraction, e.g. glass doors, difficult to perceive. A second challenge is that common depth sensors typically used for opaque object perception cannot obtain accurate depth measurements on transparent objects due to their unique reflective properties. Stemming from these challenges, we observe that transparent object instances within the same category (e.g. cups) look more similar to each other than to ordinary opaque objects of that same category. Given this observation, the present paper sets out to explore the possibility of category-level transparent object pose estimation rather than instance-level pose estimation. We propose TransNet, a two-stage pipeline that learns to estimate category-level transparent object pose using localized depth completion and surface normal estimation. TransNet is evaluated in terms of pose estimation accuracy on a recent, large-scale transparent object dataset and compared to a state-of-the-art category-level pose estimation approach. Results from this comparison demonstrate that TransNet achieves improved pose estimation accuracy on transparent objects and key findings from the included ablation studies suggest future directions for performance improvements.