 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecursive Think-Answer Process for LLMs and VLMs
Mar 03, 2026Think-Answer reasoners such as DeepSeek-R1 have made notable progress by leveraging interpretable internal reasoning. However, despite the frequent presence of self-reflective cues like "Oops!", they remain vulnerable to output errors during single-pass inference. To address this limitation, we propose an efficient Recursive Think-Answer Process (R-TAP) that enables models to engage in iterative reasoning cycles and generate more accurate answers, going beyond conventional single-pass approaches. Central to this approach is a confidence generator that evaluates the certainty of model responses and guides subsequent improvements. By incorporating two complementary rewards-Recursively Confidence Increase Reward and Final Answer Confidence Reward-we show that R-TAP-enhanced models consistently outperform conventional single-pass methods for both large language models (LLMs) and vision-language models (VLMs). Moreover, by analyzing the frequency of "Oops"-like expressions in model responses, we find that R-TAP-applied models exhibit significantly fewer self-reflective patterns, resulting in more stable and faster inference-time reasoning. We hope R-TAP pave the way evolving into efficient and elaborated methods to refine the reasoning processes of future AI.
Masking Teacher and Reinforcing Student for Distilling Vision-Language Models
Dec 23, 2025Large-scale vision-language models (VLMs) have recently achieved remarkable multimodal understanding, but their massive size makes them impractical for deployment on mobile or edge devices. This raises the need for compact yet capable VLMs that can efficiently learn from powerful large teachers. However, distilling knowledge from a large teacher to a small student remains challenging due to their large size gap: the student often fails to reproduce the teacher's complex, high-dimensional representations, leading to unstable learning and degraded performance. To address this, we propose Masters (Masking Teacher and Reinforcing Student), a mask-progressive reinforcement learning (RL) distillation framework. Masters first masks non-dominant weights of the teacher to reduce unnecessary complexity, then progressively restores the teacher by gradually increasing its capacity during training. This strategy allows the student to learn richer representations from the teacher in a smooth and stable manner. To further refine knowledge transfer, Masters integrates an offline RL stage with two complementary rewards: an accuracy reward that measures the correctness of the generated responses, and a distillation reward that quantifies the ease of transferring responses from teacher to student. Unlike online think-answer RL paradigms that are computationally expensive and generate lengthy responses, our offline RL leverages pre-generated responses from masked teachers. These provide rich yet efficient guidance, enabling students to achieve strong performance without requiring the think-answer process.
Unified Reinforcement and Imitation Learning for Vision-Language Models
Oct 22, 2025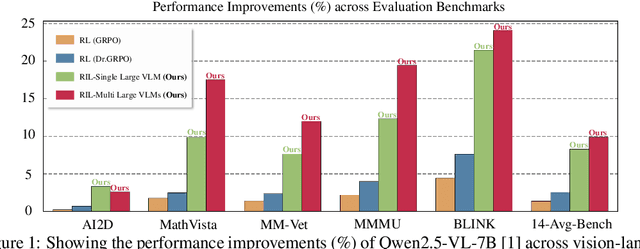



Vision-Language Models (VLMs) have achieved remarkable progress, yet their large scale often renders them impractical for resource-constrained environments. This paper introduces Unified Reinforcement and Imitation Learning (RIL), a novel and efficient training algorithm designed to create powerful, lightweight VLMs. RIL distinctively combines the strengths of reinforcement learning with adversarial imitation learning. This enables smaller student VLMs not only to mimic the sophisticated text generation of large teacher models but also to systematically improve their generative capabilities through reinforcement signals. Key to our imitation framework is an LLM-based discriminator that adeptly distinguishes between student and teacher outputs, complemented by guidance from multiple large teacher VLMs to ensure diverse learning. This unified learning strategy, leveraging both reinforcement and imitation, empowers student models to achieve significant performance gains, making them competitive with leading closed-source VLMs. Extensive experiments on diverse vision-language benchmarks demonstrate that RIL significantly narrows the performance gap with state-of-the-art open- and closed-source VLMs and, in several instances, surpasses them.
GenRecal: Generation after Recalibration from Large to Small Vision-Language Models
Jun 18, 2025Recent advancements in vision-language models (VLMs) have leveraged large language models (LLMs) to achieve performance on par with closed-source systems like GPT-4V. However, deploying these models in real-world scenarios, particularly on resource-constrained devices, remains challenging due to their substantial computational demands. This has spurred interest in distilling knowledge from large VLMs into smaller, more efficient counterparts. A key challenge arises here from the diversity of VLM architectures, which are built on different LLMs and employ varying token types-differing in vocabulary size, token splits, and token index ordering. To address this challenge of limitation to a specific VLM type, we present Generation after Recalibration (GenRecal), a novel, general-purpose distillation framework for VLMs. GenRecal incorporates a Recalibrator that aligns and adapts feature representations between heterogeneous VLMs, enabling effective knowledge transfer across different types of VLMs. Through extensive experiments on multiple challenging benchmarks, we demonstrate that GenRecal significantly improves baseline performances, eventually outperforming large-scale open- and closed-source VLMs.
Are Vision-Language Models Truly Understanding Multi-vision Sensor?
Dec 30, 2024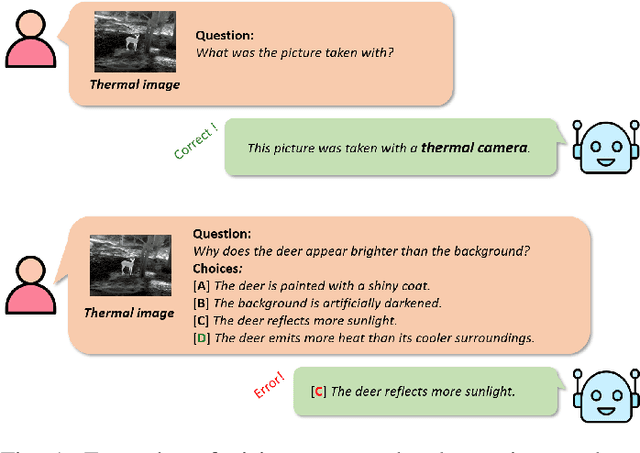
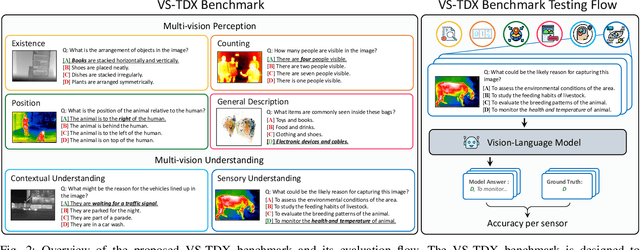
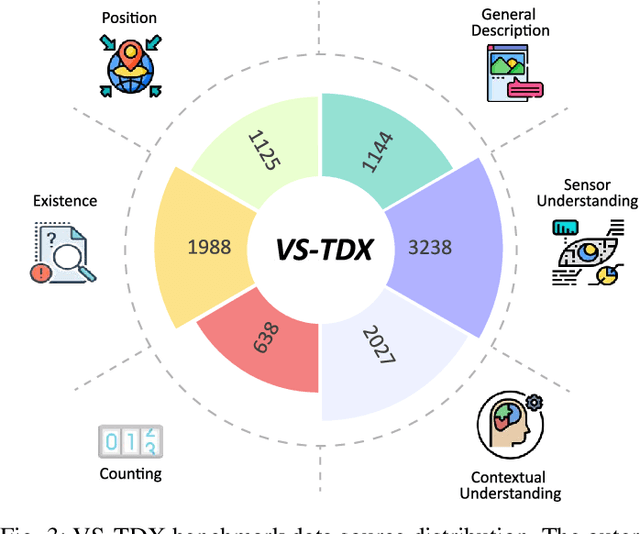

Large-scale Vision-Language Models (VLMs) have advanced by aligning vision inputs with text, significantly improving performance in computer vision tasks. Moreover, for VLMs to be effectively utilized in real-world applications, an understanding of diverse multi-vision sensor data, such as thermal, depth, and X-ray information, is essential. However, we find that current VLMs process multi-vision sensor images without deep understanding of sensor information, disregarding each sensor's unique physical properties. This limitation restricts their capacity to interpret and respond to complex questions requiring multi-vision sensor reasoning. To address this, we propose a novel Multi-vision Sensor Perception and Reasoning (MS-PR) benchmark, assessing VLMs on their capacity for sensor-specific reasoning. Moreover, we introduce Diverse Negative Attributes (DNA) optimization to enable VLMs to perform deep reasoning on multi-vision sensor tasks, helping to bridge the core information gap between images and sensor data. Extensive experimental results validate that the proposed DNA method can significantly improve the multi-vision sensor reasoning for VLMs.
VLsI: Verbalized Layers-to-Interactions from Large to Small Vision Language Models
Dec 02, 2024



The recent surge in high-quality visual instruction tuning samples from closed-source vision-language models (VLMs) such as GPT-4V has accelerated the release of open-source VLMs across various model sizes. However, scaling VLMs to improve performance using larger models brings significant computational challenges, especially for deployment on resource-constrained devices like mobile platforms and robots. To address this, we propose VLsI: Verbalized Layers-to-Interactions, a new VLM family in 2B and 7B model sizes, which prioritizes efficiency without compromising accuracy. VLsI leverages a unique, layer-wise distillation process, introducing intermediate "verbalizers" that map features from each layer to natural language space, allowing smaller VLMs to flexibly align with the reasoning processes of larger VLMs. This approach mitigates the training instability often encountered in output imitation and goes beyond typical final-layer tuning by aligning the small VLMs' layer-wise progression with that of the large ones. We validate VLsI across ten challenging vision-language benchmarks, achieving notable performance gains (11.0% for 2B and 17.4% for 7B) over GPT-4V without the need for model scaling, merging, or architectural changes.
SPARK: Multi-Vision Sensor Perception and Reasoning Benchmark for Large-scale Vision-Language Models
Aug 23, 2024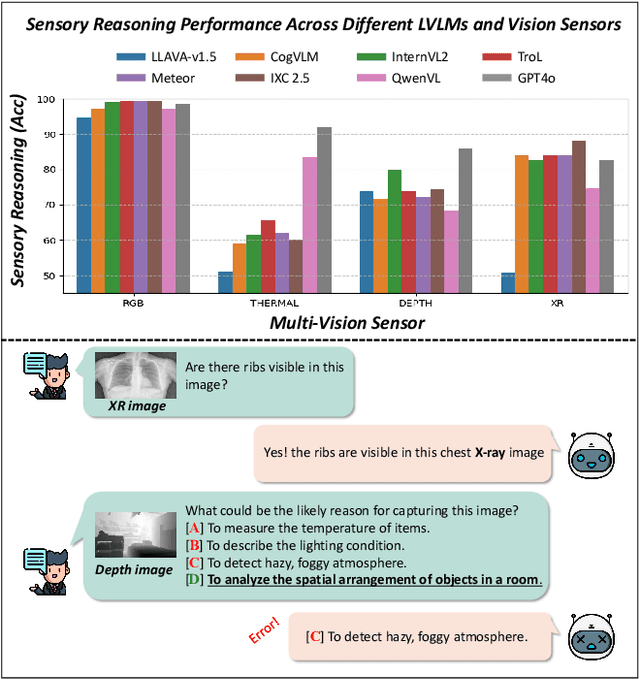
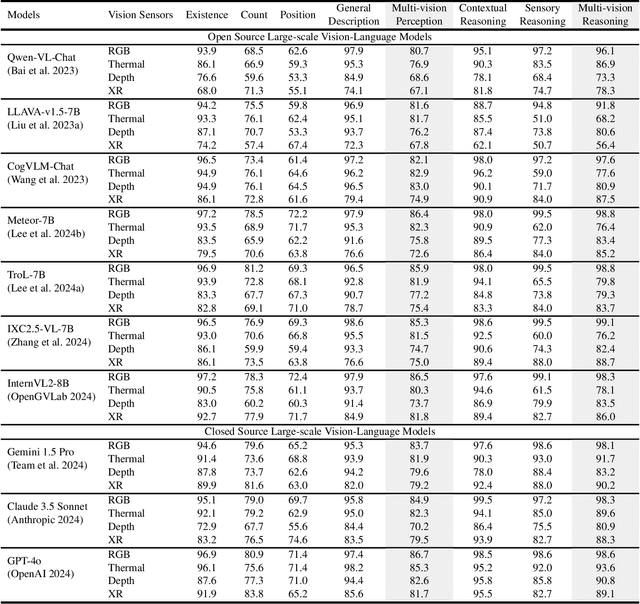
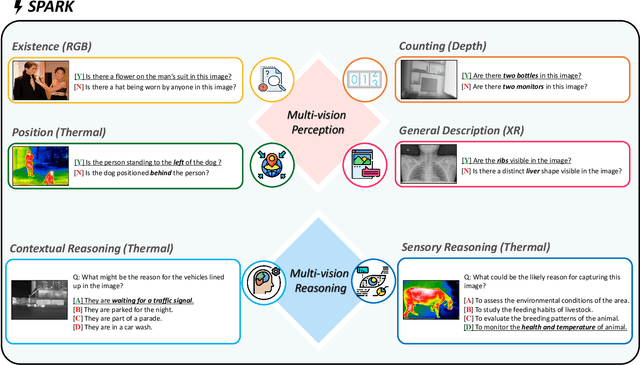
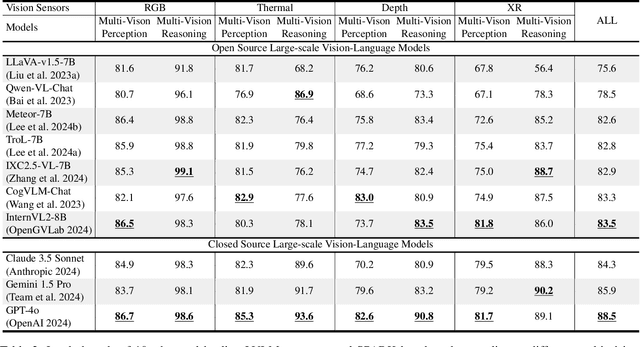
Large-scale Vision-Language Models (LVLMs) have significantly advanced with text-aligned vision inputs. They have made remarkable progress in computer vision tasks by aligning text modality with vision inputs. There are also endeavors to incorporate multi-vision sensors beyond RGB, including thermal, depth, and medical X-ray images. However, we observe that current LVLMs view images taken from multi-vision sensors as if they were in the same RGB domain without considering the physical characteristics of multi-vision sensors. They fail to convey the fundamental multi-vision sensor information from the dataset and the corresponding contextual knowledge properly. Consequently, alignment between the information from the actual physical environment and the text is not achieved correctly, making it difficult to answer complex sensor-related questions that consider the physical environment. In this paper, we aim to establish a multi-vision Sensor Perception And Reasoning benchmarK called SPARK that can reduce the fundamental multi-vision sensor information gap between images and multi-vision sensors. We generated 6,248 vision-language test samples to investigate multi-vision sensory perception and multi-vision sensory reasoning on physical sensor knowledge proficiency across different formats, covering different types of sensor-related questions. We utilized these samples to assess ten leading LVLMs. The results showed that most models displayed deficiencies in multi-vision sensory reasoning to varying extents. Codes and data are available at https://github.com/top-yun/SPARK
TroL: Traversal of Layers for Large Language and Vision Models
Jun 18, 2024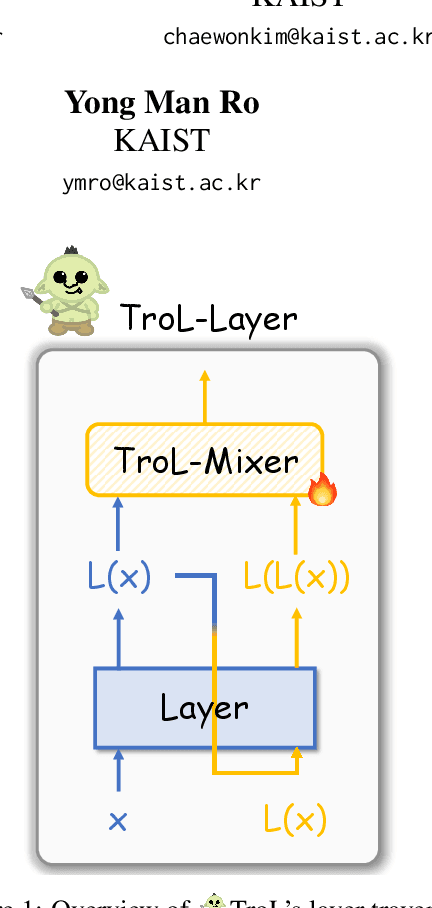
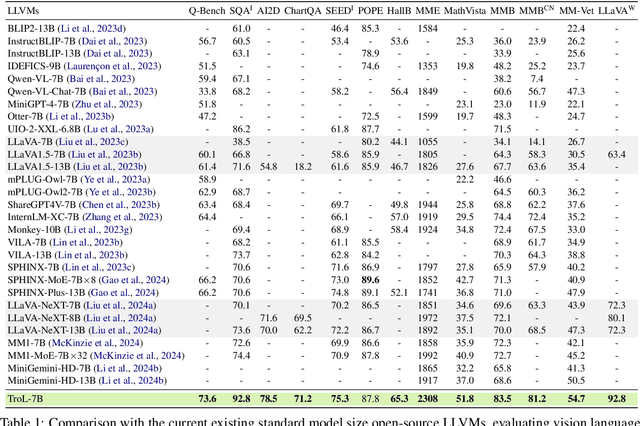
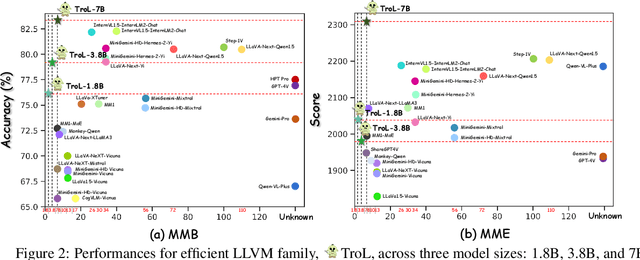
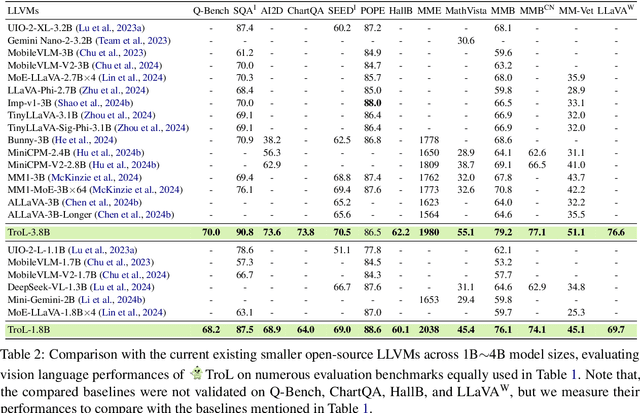
Large language and vision models (LLVMs) have been driven by the generalization power of large language models (LLMs) and the advent of visual instruction tuning. Along with scaling them up directly, these models enable LLVMs to showcase powerful vision language (VL) performances by covering diverse tasks via natural language instructions. However, existing open-source LLVMs that perform comparably to closed-source LLVMs such as GPT-4V are often considered too large (e.g., 26B, 34B, and 110B parameters), having a larger number of layers. These large models demand costly, high-end resources for both training and inference. To address this issue, we present a new efficient LLVM family with 1.8B, 3.8B, and 7B LLM model sizes, Traversal of Layers (TroL), which enables the reuse of layers in a token-wise manner. This layer traversing technique simulates the effect of looking back and retracing the answering stream while increasing the number of forward propagation layers without physically adding more layers. We demonstrate that TroL employs a simple layer traversing approach yet efficiently outperforms the open-source LLVMs with larger model sizes and rivals the performances of the closed-source LLVMs with substantial sizes.
Meteor: Mamba-based Traversal of Rationale for Large Language and Vision Models
May 27, 2024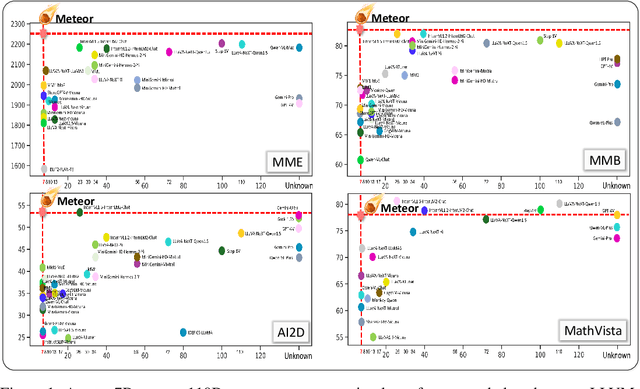
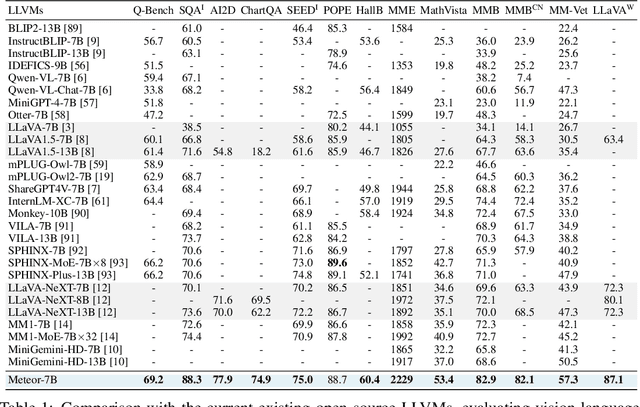
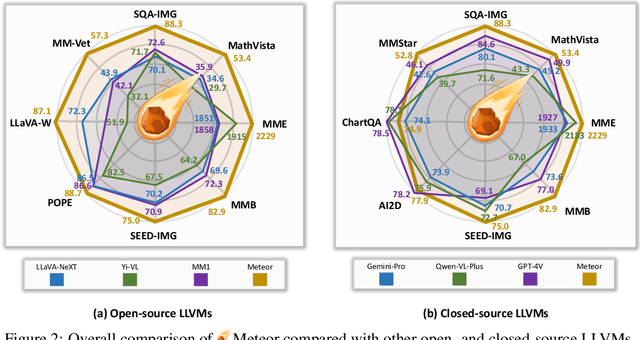

The rapid development of large language and vision models (LLVMs) has been driven by advances in visual instruction tuning. Recently, open-source LLVMs have curated high-quality visual instruction tuning datasets and utilized additional vision encoders or multiple computer vision models in order to narrow the performance gap with powerful closed-source LLVMs. These advancements are attributed to multifaceted information required for diverse capabilities, including fundamental image understanding, real-world knowledge about common-sense and non-object concepts (e.g., charts, diagrams, symbols, signs, and math problems), and step-by-step procedures for solving complex questions. Drawing from the multifaceted information, we present a new efficient LLVM, Mamba-based traversal of rationales (Meteor), which leverages multifaceted rationale to enhance understanding and answering capabilities. To embed lengthy rationales containing abundant information, we employ the Mamba architecture, capable of processing sequential data with linear time complexity. We introduce a new concept of traversal of rationale that facilitates efficient embedding of rationale. Subsequently, the backbone multimodal language model (MLM) is trained to generate answers with the aid of rationale. Through these steps, Meteor achieves significant improvements in vision language performances across multiple evaluation benchmarks requiring diverse capabilities, without scaling up the model size or employing additional vision encoders and computer vision models.
MoAI: Mixture of All Intelligence for Large Language and Vision Models
Mar 12, 2024



The rise of large language models (LLMs) and instruction tuning has led to the current trend of instruction-tuned large language and vision models (LLVMs). This trend involves either meticulously curating numerous instruction tuning datasets tailored to specific objectives or enlarging LLVMs to manage vast amounts of vision language (VL) data. However, current LLVMs have disregarded the detailed and comprehensive real-world scene understanding available from specialized computer vision (CV) models in visual perception tasks such as segmentation, detection, scene graph generation (SGG), and optical character recognition (OCR). Instead, the existing LLVMs rely mainly on the large capacity and emergent capabilities of their LLM backbones. Therefore, we present a new LLVM, Mixture of All Intelligence (MoAI), which leverages auxiliary visual information obtained from the outputs of external segmentation, detection, SGG, and OCR models. MoAI operates through two newly introduced modules: MoAI-Compressor and MoAI-Mixer. After verbalizing the outputs of the external CV models, the MoAI-Compressor aligns and condenses them to efficiently use relevant auxiliary visual information for VL tasks. MoAI-Mixer then blends three types of intelligence (1) visual features, (2) auxiliary features from the external CV models, and (3) language features by utilizing the concept of Mixture of Experts. Through this integration, MoAI significantly outperforms both open-source and closed-source LLVMs in numerous zero-shot VL tasks, particularly those related to real-world scene understanding such as object existence, positions, relations, and OCR without enlarging the model size or curating extra visual instruction tuning datasets.