 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPARK: Multi-Vision Sensor Perception and Reasoning Benchmark for Large-scale Vision-Language Models
Paper and Code
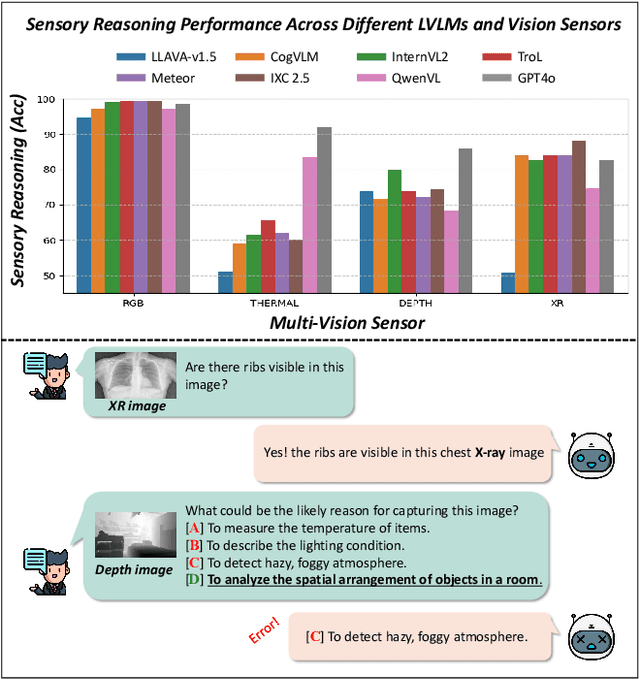
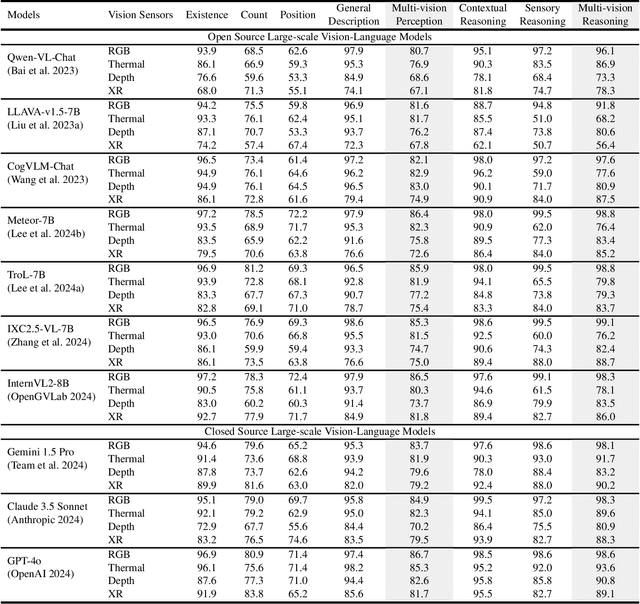
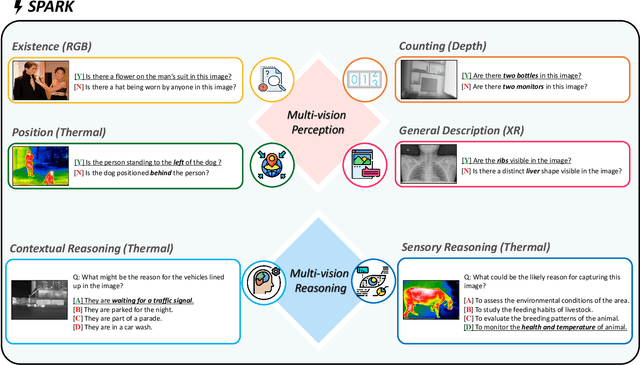
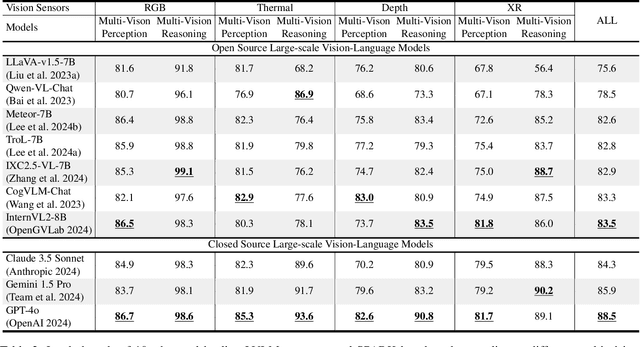
Large-scale Vision-Language Models (LVLMs) have significantly advanced with text-aligned vision inputs. They have made remarkable progress in computer vision tasks by aligning text modality with vision inputs. There are also endeavors to incorporate multi-vision sensors beyond RGB, including thermal, depth, and medical X-ray images. However, we observe that current LVLMs view images taken from multi-vision sensors as if they were in the same RGB domain without considering the physical characteristics of multi-vision sensors. They fail to convey the fundamental multi-vision sensor information from the dataset and the corresponding contextual knowledge properly. Consequently, alignment between the information from the actual physical environment and the text is not achieved correctly, making it difficult to answer complex sensor-related questions that consider the physical environment. In this paper, we aim to establish a multi-vision Sensor Perception And Reasoning benchmarK called SPARK that can reduce the fundamental multi-vision sensor information gap between images and multi-vision sensors. We generated 6,248 vision-language test samples to investigate multi-vision sensory perception and multi-vision sensory reasoning on physical sensor knowledge proficiency across different formats, covering different types of sensor-related questions. We utilized these samples to assess ten leading LVLMs. The results showed that most models displayed deficiencies in multi-vision sensory reasoning to varying extents. Codes and data are available at https://github.com/top-yun/SPARK