 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUplink Multiple Access with Heterogeneous Blocklength and Reliability Constraints: Discrete Signaling with Treating Interference as Noise
Nov 23, 2024



We consider the uplink multiple access of heterogeneous users, e.g., ultra-reliable low-latency communications (URLLC) and enhanced mobile broadband (eMBB) users. Each user has its own reliability requirement and blocklength constraint, and users transmitting longer blocks suffer from heterogeneous interference. On top of that, the decoding of URLLC messages cannot leverage successive interference cancellation (SIC) owing to the stringent latency requirements. This can significantly degrade the spectral efficiency of all URLLC users when the interference is strong. To overcome this issue, we propose a new multiple access scheme employing discrete signaling and treating interference as noise (TIN) decoding, i.e., without SIC. Specifically, to handle heterogeneous interference while maintaining the single-user encoding and decoding complexities, each user uses a single channel code and maps its coded bits onto sub-blocks of symbols, where the underlying constellations can be different. We demonstrate theoretically and numerically that the proposed scheme employing quadrature amplitude modulations and TIN decoding can perform very close to the benchmark scheme based on Gaussian signaling with perfect SIC decoding. Interestingly, we show that the proposed scheme does not need to use all the transmit power budget, but also can sometimes even outperform the benchmark scheme.
Diminishing Exploration: A Minimalist Approach to Piecewise Stationary Multi-Armed Bandits
Oct 08, 2024
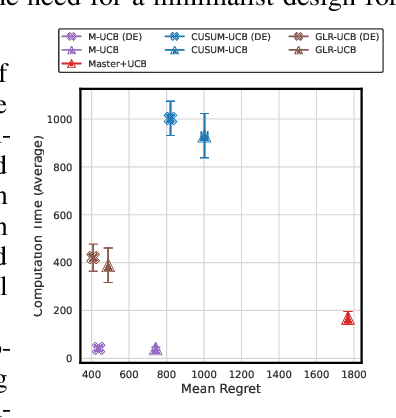
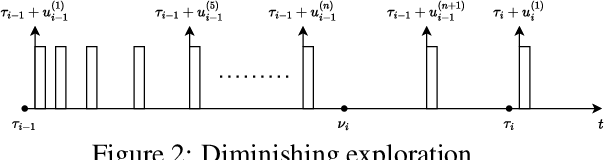

The piecewise-stationary bandit problem is an important variant of the multi-armed bandit problem that further considers abrupt changes in the reward distributions. The main theme of the problem is the trade-off between exploration for detecting environment changes and exploitation of traditional bandit algorithms. While this problem has been extensively investigated, existing works either assume knowledge about the number of change points $M$ or require extremely high computational complexity. In this work, we revisit the piecewise-stationary bandit problem from a minimalist perspective. We propose a novel and generic exploration mechanism, called diminishing exploration, which eliminates the need for knowledge about $M$ and can be used in conjunction with an existing change detection-based algorithm to achieve near-optimal regret scaling. Simulation results show that despite oblivious of $M$, equipping existing algorithms with the proposed diminishing exploration generally achieves better empirical regret than the traditional uniform exploration.
Age Aware Scheduling for Differentially-Private Federated Learning
May 09, 2024


This paper explores differentially-private federated learning (FL) across time-varying databases, delving into a nuanced three-way tradeoff involving age, accuracy, and differential privacy (DP). Emphasizing the potential advantages of scheduling, we propose an optimization problem aimed at meeting DP requirements while minimizing the loss difference between the aggregated model and the model obtained without DP constraints. To harness the benefits of scheduling, we introduce an age-dependent upper bound on the loss, leading to the development of an age-aware scheduling design. Simulation results underscore the superior performance of our proposed scheme compared to FL with classic DP, which does not consider scheduling as a design factor. This research contributes insights into the interplay of age, accuracy, and DP in federated learning, with practical implications for scheduling strategies.
Coexistence of Heterogeneous Services in the Uplink with Discrete Signaling and Treating Interference as Noise
Aug 17, 2023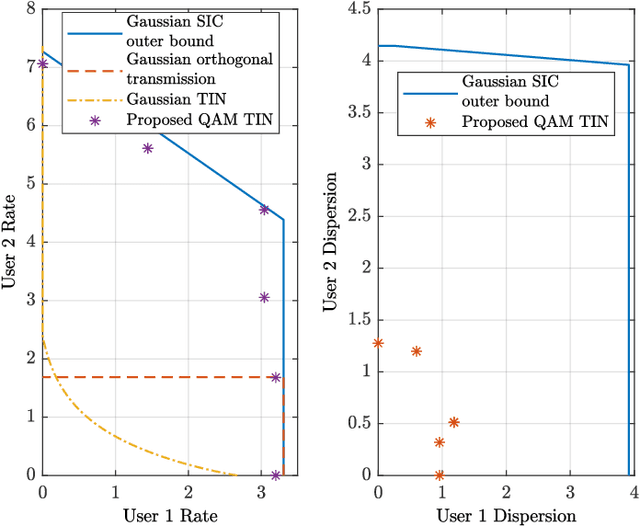
The problem of enabling the coexistence of heterogeneous services, e.g., different ultra-reliable low-latency communications (URLLC) services and/or enhanced mobile broadband (eMBB) services, in the uplink is studied. Each service has its own error probability and blocklength constraints and the longer transmission block suffers from heterogeneous interference. Due to the latency concern, the decoding of URLLC messages cannot leverage successive interference cancellation (SIC) and should always be performed before the decoding of eMBB messages. This can significantly degrade the achievable rates of URLLC users when the interference from other users is strong. To overcome this issue, we propose a new transmission scheme based on discrete signaling and treating interference as noise decoding, i.e., without SIC. Guided by the deterministic model, we provide a systematic way to construct discrete signaling for handling heterogeneous interference effectively. We demonstrate theoretically and numerically that the proposed scheme can perform close to the benchmark scheme based on capacity-achieving Gaussian signaling with the assumption of perfect SIC.
Committed Private Information Retrieval
Feb 03, 2023

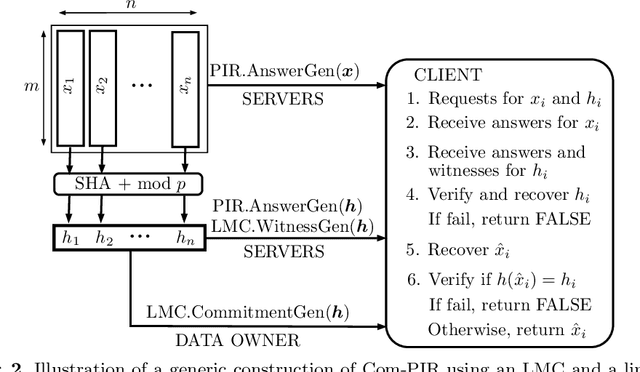

A private information retrieval (PIR) scheme allows a client to retrieve a data item $x_i$ among $n$ items $x_1,x_2,...,x_n$ from $k$ servers, without revealing what $i$ is even when $t < k$ servers collude and try to learn $i$. Such a PIR scheme is said to be $t$-private. A PIR scheme is $v$-verifiable if the client can verify the correctness of the retrieved $x_i$ even when $v \leq k$ servers collude and try to fool the client by sending manipulated data. Most of the previous works in the literature on PIR assumed that $v < k$, leaving the case of all-colluding servers open. We propose a generic construction that combines a linear map commitment (LMC) and an arbitrary linear PIR scheme to produce a $k$-verifiable PIR scheme, termed a committed PIR scheme. Such a scheme guarantees that even in the worst scenario, when all servers are under the control of an attacker, although the privacy is unavoidably lost, the client won't be fooled into accepting an incorrect $x_i$. We demonstrate the practicality of our proposal by implementing the committed PIR schemes based on the Lai-Malavolta LMC and three well-known PIR schemes using the GMP library and \texttt{blst}, the current fastest C library for elliptic curve pairings.
Downlink Transmission under Heterogeneous Blocklength Constraints: Discrete Signaling with Single-User Decoding
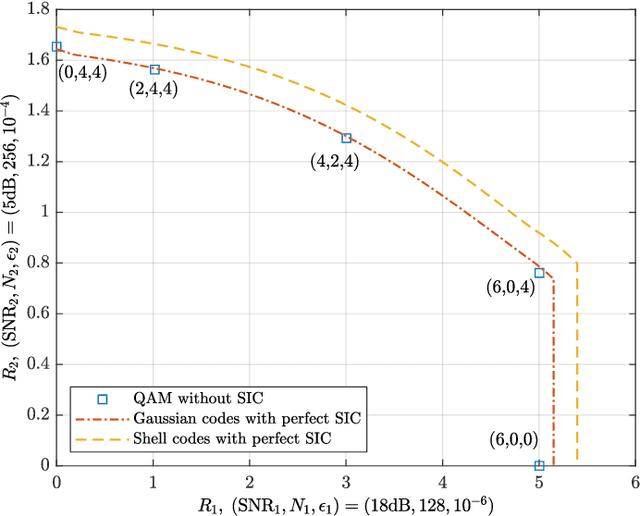
Jan 23, 2023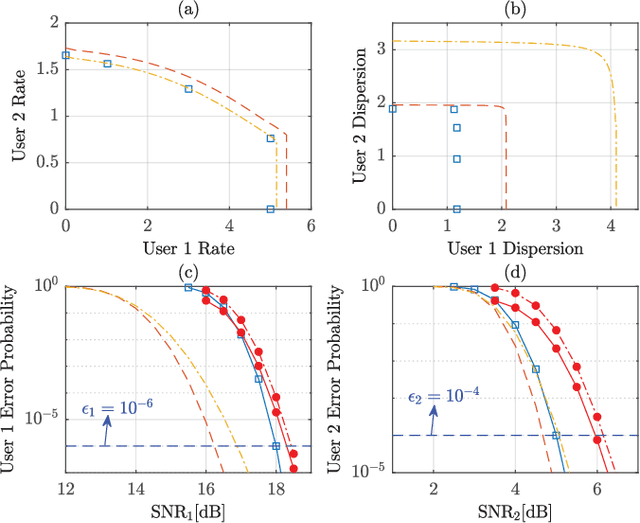
In this paper, we consider the downlink broadcast channel under heterogenous blocklength constraints, where each user experiences different interference statistics across its received symbols. Different from the homogeneous blocklength case, the strong users with short blocklength transmitted symbol blocks usually cannot wait to receive the entire transmission frame and perform successive interference cancellation (SIC) owing to their stringent latency requirements. Even if SIC is feasible, it may not be perfect under finite blocklength constraints. To cope with the heterogeneity in latency and reliability requirements, we propose a practical downlink transmission scheme with discrete signaling and single-user decoding, i.e., without SIC. In addition, we derive the finite blocklength achievable rate and use it for guiding the design of channel coding and modulations. Both achievable rate and error probability simulation show that the proposed scheme can operate close to the benchmark scheme which assumes capacity-achieving signaling and perfect SIC.
Downlink Transmission with Heterogeneous URLLC Services: Discrete Signaling With Single-User Decoding
Dec 04, 2022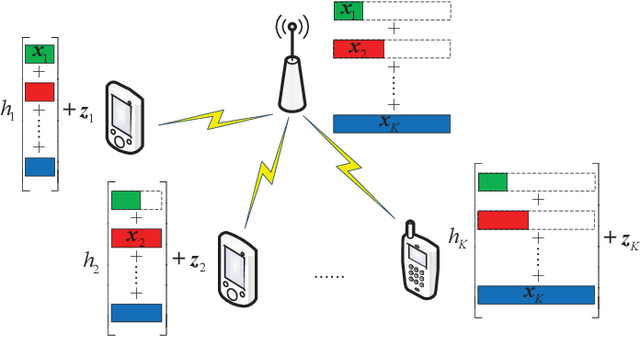

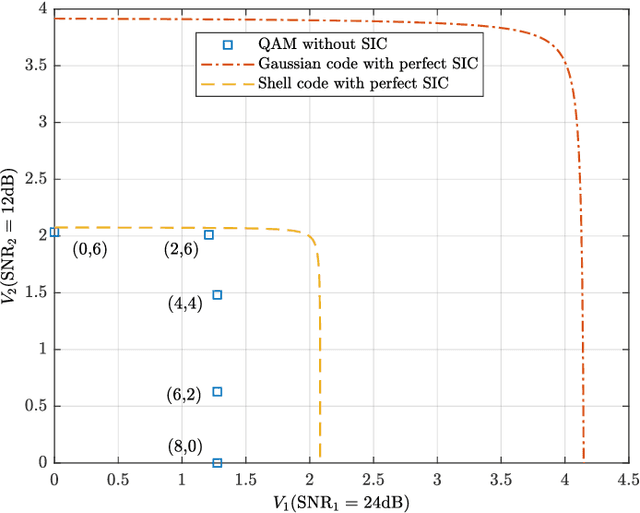
The problem of designing downlink transmission schemes for supporting heterogeneous ultra-reliable low-latency communications (URLLC) and/or with other types of services is investigated. We consider the broadcast channel, where the base station sends superimposed signals to multiple users. Under heterogeneous blocklength constraints, strong users who are URLLC users cannot wait to receive the entire transmission frame and perform successive interference cancellation (SIC) due to stringent latency requirements, in contrast to the conventional infinite blocklength cases. Even if SIC is feasible, SIC may be imperfect under finite blocklength constraints. To cope with the heterogeneity in latency and reliability requirements, we propose a practical downlink transmission scheme with discrete signaling and single-user decoding (SUD), i.e., without SIC. We carefully design the discrete input distributions to enable efficient SUD by exploiting the structural interference. Furthermore, we derive the second-order achievable rate under heterogenous blocklength and error probability constraints and use it to guide the design of channel coding and modulations. It is shown that in terms of achievable rate under short blocklength, the proposed scheme with regular quadrature amplitude modulations and SUD can operate extremely close to the benchmark schemes that assume perfect SIC with Gaussian signaling.
How to Attain Communication-Efficient DNN Training? Convert, Compress, Correct
Apr 18, 2022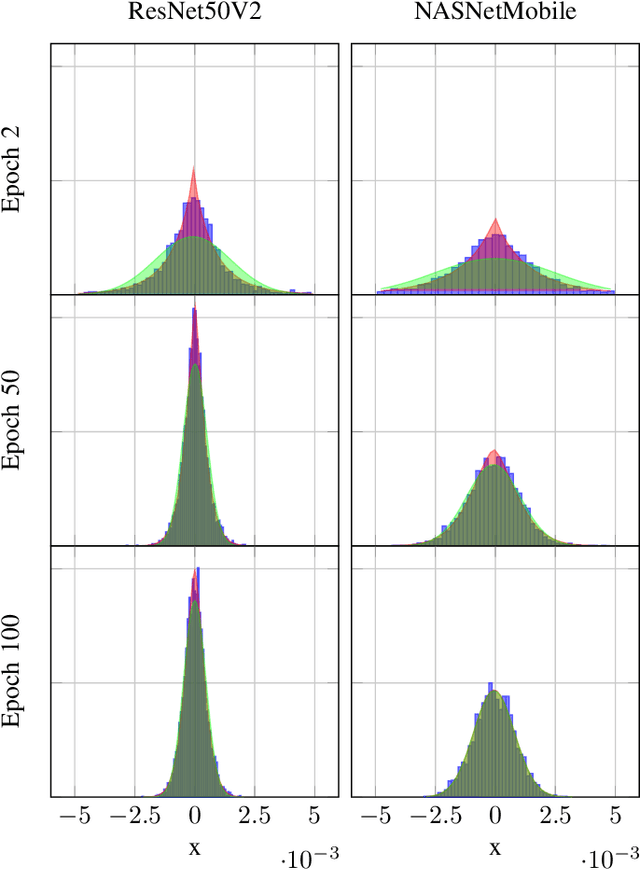

In this paper, we introduce $\mathsf{CO}_3$, an algorithm for communication-efficiency federated Deep Neural Network (DNN) training.$\mathsf{CO}_3$ takes its name from three processing applied steps which reduce the communication load when transmitting the local gradients from the remote users to the Parameter Server.Namely:(i) gradient quantization through floating-point conversion, (ii) lossless compression of the quantized gradient, and (iii) quantization error correction.We carefully design each of the steps above so as to minimize the loss in the distributed DNN training when the communication overhead is fixed.In particular, in the design of steps (i) and (ii), we adopt the assumption that DNN gradients are distributed according to a generalized normal distribution.This assumption is validated numerically in the paper. For step (iii), we utilize an error feedback with memory decay mechanism to correct the quantization error introduced in step (i). We argue that this coefficient, similarly to the learning rate, can be optimally tuned to improve convergence. The performance of $\mathsf{CO}_3$ is validated through numerical simulations and is shown having better accuracy and improved stability at a reduced communication payload.
Convert, compress, correct: Three steps toward communication-efficient DNN training
Mar 17, 2022
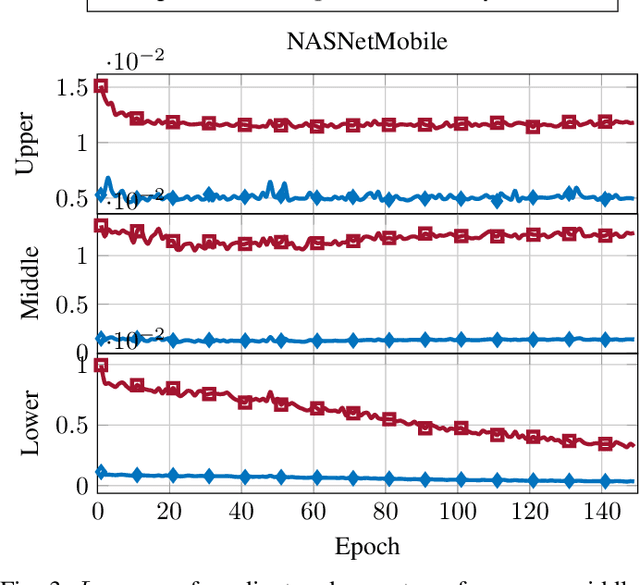
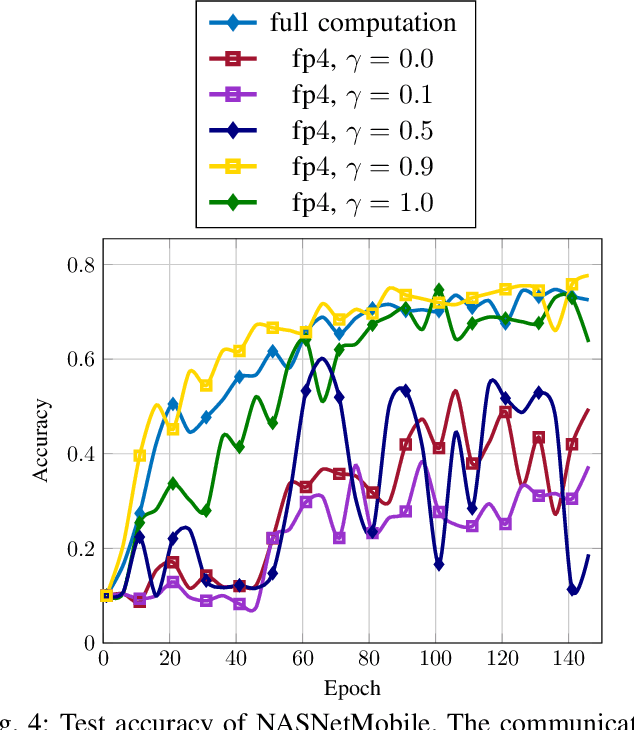
In this paper, we introduce a novel algorithm, $\mathsf{CO}_3$, for communication-efficiency distributed Deep Neural Network (DNN) training. $\mathsf{CO}_3$ is a joint training/communication protocol, which encompasses three processing steps for the network gradients: (i) quantization through floating-point conversion, (ii) lossless compression, and (iii) error correction. These three components are crucial in the implementation of distributed DNN training over rate-constrained links. The interplay of these three steps in processing the DNN gradients is carefully balanced to yield a robust and high-performance scheme. The performance of the proposed scheme is investigated through numerical evaluations over CIFAR-10.
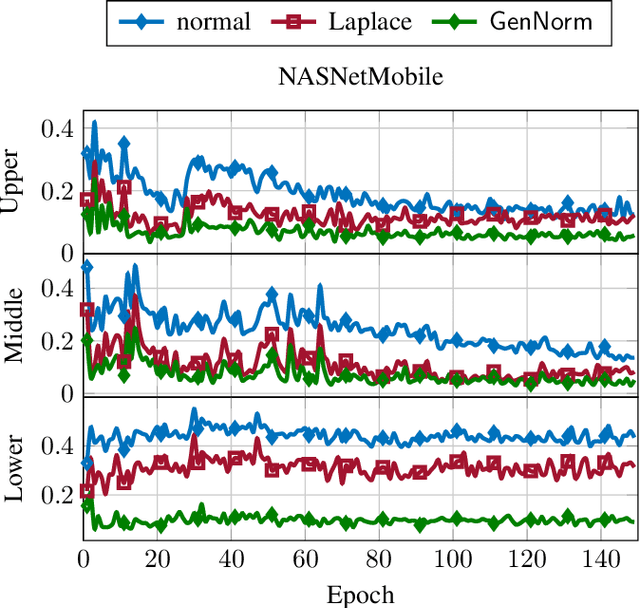
DNN gradient lossless compression: Can GenNorm be the answer?
Nov 15, 2021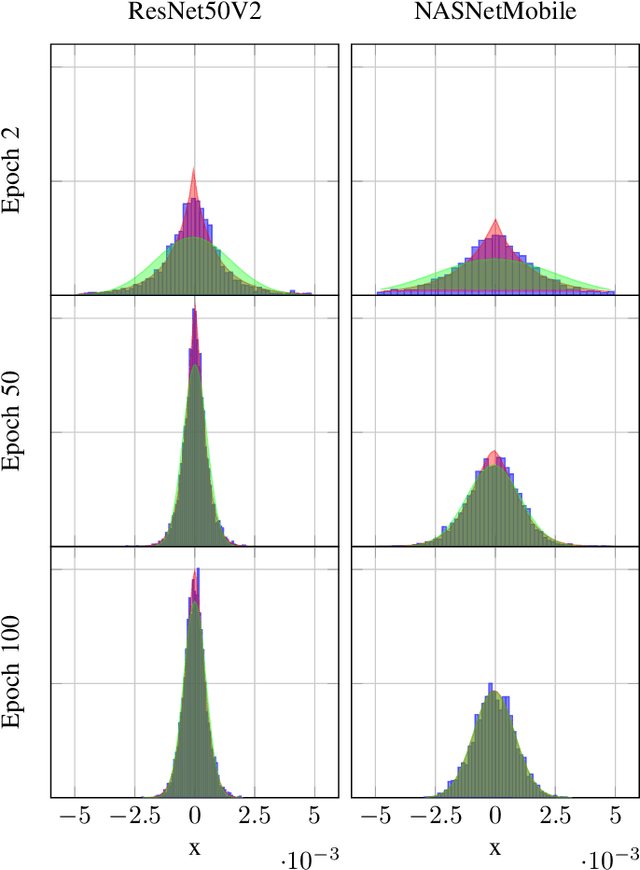
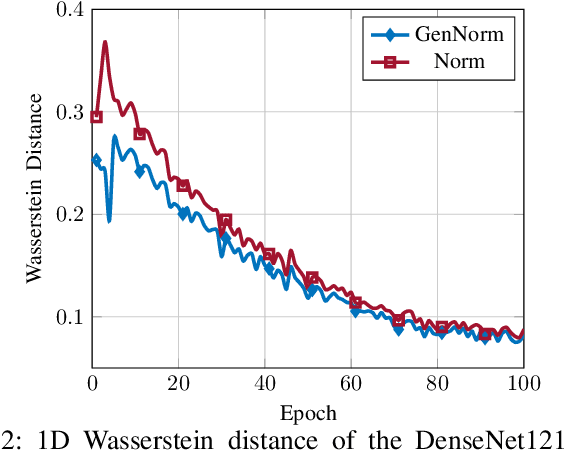
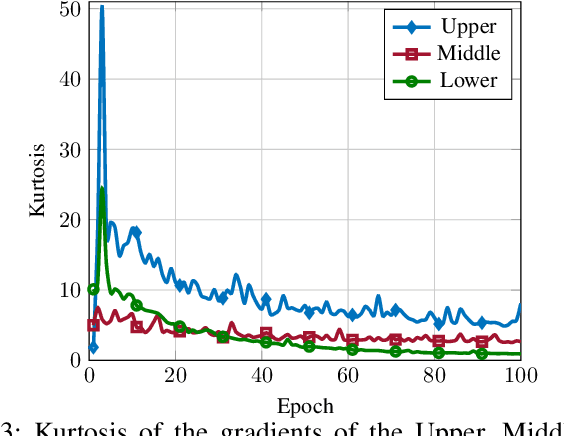
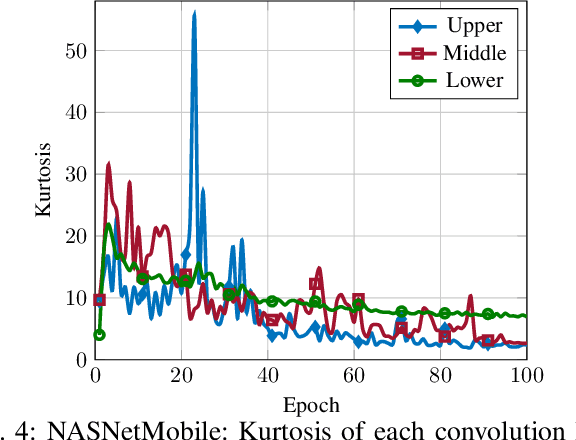
In this paper, the problem of optimal gradient lossless compression in Deep Neural Network (DNN) training is considered. Gradient compression is relevant in many distributed DNN training scenarios, including the recently popular federated learning (FL) scenario in which each remote users are connected to the parameter server (PS) through a noiseless but rate limited channel. In distributed DNN training, if the underlying gradient distribution is available, classical lossless compression approaches can be used to reduce the number of bits required for communicating the gradient entries. Mean field analysis has suggested that gradient updates can be considered as independent random variables, while Laplace approximation can be used to argue that gradient has a distribution approximating the normal (Norm) distribution in some regimes. In this paper we argue that, for some networks of practical interest, the gradient entries can be well modelled as having a generalized normal (GenNorm) distribution. We provide numerical evaluations to validate that the hypothesis GenNorm modelling provides a more accurate prediction of the DNN gradient tail distribution. Additionally, this modeling choice provides concrete improvement in terms of lossless compression of the gradients when applying classical fix-to-variable lossless coding algorithms, such as Huffman coding, to the quantized gradient updates. This latter results indeed provides an effective compression strategy with low memory and computational complexity that has great practical relevance in distributed DNN training scenarios.