 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Prediction of Stochastic Sequences with High Probability Regret Bounds
Feb 18, 2026We revisit the classical problem of universal prediction of stochastic sequences with a finite time horizon $T$ known to the learner. The question we investigate is whether it is possible to derive vanishing regret bounds that hold with high probability, complementing existing bounds from the literature that hold in expectation. We propose such high-probability bounds which have a very similar form as the prior expectation bounds. For the case of universal prediction of a stochastic process over a countable alphabet, our bound states a convergence rate of $\mathcal{O}(T^{-1/2} δ^{-1/2})$ with probability as least $1-δ$ compared to prior known in-expectation bounds of the order $\mathcal{O}(T^{-1/2})$. We also propose an impossibility result which proves that it is not possible to improve the exponent of $δ$ in a bound of the same form without making additional assumptions.
Block-Sample MAC-Bayes Generalization Bounds
Feb 13, 2026We present a family of novel block-sample MAC-Bayes bounds (mean approximately correct). While PAC-Bayes bounds (probably approximately correct) typically give bounds for the generalization error that hold with high probability, MAC-Bayes bounds have a similar form but bound the expected generalization error instead. The family of bounds we propose can be understood as a generalization of an expectation version of known PAC-Bayes bounds. Compared to standard PAC-Bayes bounds, the new bounds contain divergence terms that only depend on subsets (or \emph{blocks}) of the training data. The proposed MAC-Bayes bounds hold the promise of significantly improving upon the tightness of traditional PAC-Bayes and MAC-Bayes bounds. This is illustrated with a simple numerical example in which the original PAC-Bayes bound is vacuous regardless of the choice of prior, while the proposed family of bounds are finite for appropriate choices of the block size. We also explore the question whether high-probability versions of our MAC-Bayes bounds (i.e., PAC-Bayes bounds of a similar form) are possible. We answer this question in the negative with an example that shows that in general, it is not possible to establish a PAC-Bayes bound which (a) vanishes with a rate faster than $\mathcal{O}(1/\log n)$ whenever the proposed MAC-Bayes bound vanishes with rate $\mathcal{O}(n^{-1/2})$ and (b) exhibits a logarithmic dependence on the permitted error probability.
A PAC-Bayesian Analysis of Channel-Induced Degradation in Edge Inference
Jan 16, 2026In the emerging paradigm of edge inference, neural networks (NNs) are partitioned across distributed edge devices that collaboratively perform inference via wireless transmission. However, standard NNs are generally trained in a noiseless environment, creating a mismatch with the noisy channels during edge deployment. In this paper, we address this issue by characterizing the channel-induced performance deterioration as a generalization error against unseen channels. We introduce an augmented NN model that incorporates channel statistics directly into the weight space, allowing us to derive PAC-Bayesian generalization bounds that explicitly quantifies the impact of wireless distortion. We further provide closed-form expressions for practical channels to demonstrate the tractability of these bounds. Inspired by the theoretical results, we propose a channel-aware training algorithm that minimizes a surrogate objective based on the derived bound. Simulations show that the proposed algorithm can effectively improve inference accuracy by leveraging channel statistics, without end-to-end re-training.
Semi-Supervised Learning under General Causal Models
Oct 26, 2025Semi-supervised learning (SSL) aims to train a machine learning model using both labelled and unlabelled data. While the unlabelled data have been used in various ways to improve the prediction accuracy, the reason why unlabelled data could help is not fully understood. One interesting and promising direction is to understand SSL from a causal perspective. In light of the independent causal mechanisms principle, the unlabelled data can be helpful when the label causes the features but not vice versa. However, the causal relations between the features and labels can be complex in real world applications. In this paper, we propose a SSL framework that works with general causal models in which the variables have flexible causal relations. More specifically, we explore the causal graph structures and design corresponding causal generative models which can be learned with the help of unlabelled data. The learned causal generative model can generate synthetic labelled data for training a more accurate predictive model. We verify the effectiveness of our proposed method by empirical studies on both simulated and real data.
Low-Rank-Based Approximate Computation with Memristors
Oct 06, 2025Memristor crossbars enable vector-matrix multiplication (VMM), and are promising for low-power applications. However, it can be difficult to write the memristor conductance values exactly. To improve the accuracy of VMM, we propose a scheme based on low-rank matrix approximation. Specifically, singular value decomposition (SVD) is first applied to obtain a low-rank approximation of the target matrix, which is then factored into a pair of smaller matrices. Subsequently, a two-step serial VMM is executed, where the stochastic write errors are mitigated through step-wise averaging. To evaluate the performance of the proposed scheme, we derive a general expression for the resulting computation error and provide an asymptotic analysis under a prescribed singular-value profile, which reveals how the error scales with matrix size and rank. Both analytical and numerical results confirm the superiority of the proposed scheme compared with the benchmark scheme.
Graph Neural Networks for Resource Allocation in Multi-Channel Wireless Networks
Jun 04, 2025As the number of mobile devices continues to grow, interference has become a major bottleneck in improving data rates in wireless networks. Efficient joint channel and power allocation (JCPA) is crucial for managing interference. In this paper, we first propose an enhanced WMMSE (eWMMSE) algorithm to solve the JCPA problem in multi-channel wireless networks. To reduce the computational complexity of iterative optimization, we further introduce JCPGNN-M, a graph neural network-based solution that enables simultaneous multi-channel allocation for each user. We reformulate the problem as a Lagrangian function, which allows us to enforce the total power constraints systematically. Our solution involves combining this Lagrangian framework with GNNs and iteratively updating the Lagrange multipliers and resource allocation scheme. Unlike existing GNN-based methods that limit each user to a single channel, JCPGNN-M supports efficient spectrum reuse and scales well in dense network scenarios. Simulation results show that JCPGNN-M achieves better data rate compared to eWMMSE. Meanwhile, the inference time of JCPGNN-M is much lower than eWMMS, and it can generalize well to larger networks.
Emergence of Computational Structure in a Neural Network Physics Simulator
Apr 16, 2025



Neural networks often have identifiable computational structures - components of the network which perform an interpretable algorithm or task - but the mechanisms by which these emerge and the best methods for detecting these structures are not well understood. In this paper we investigate the emergence of computational structure in a transformer-like model trained to simulate the physics of a particle system, where the transformer's attention mechanism is used to transfer information between particles. We show that (a) structures emerge in the attention heads of the transformer which learn to detect particle collisions, (b) the emergence of these structures is associated to degenerate geometry in the loss landscape, and (c) the dynamics of this emergence follows a power law. This suggests that these components are governed by a degenerate "effective potential". These results have implications for the convergence time of computational structure within neural networks and suggest that the emergence of computational structure can be detected by studying the dynamics of network components.
Non-Asymptotic Bounds for Closed-Loop Identification of Unstable Nonlinear Stochastic Systems
Dec 05, 2024

We consider the problem of least squares parameter estimation from single-trajectory data for discrete-time, unstable, closed-loop nonlinear stochastic systems, with linearly parameterised uncertainty. Assuming a region of the state space produces informative data, and the system is sub-exponentially unstable, we establish non-asymptotic guarantees on the estimation error at times where the state trajectory evolves in this region. If the whole state space is informative, high probability guarantees on the error hold for all times. Examples are provided where our results are useful for analysis, but existing results are not.
GNN-Based Joint Channel and Power Allocation in Heterogeneous Wireless Networks
Jul 28, 2024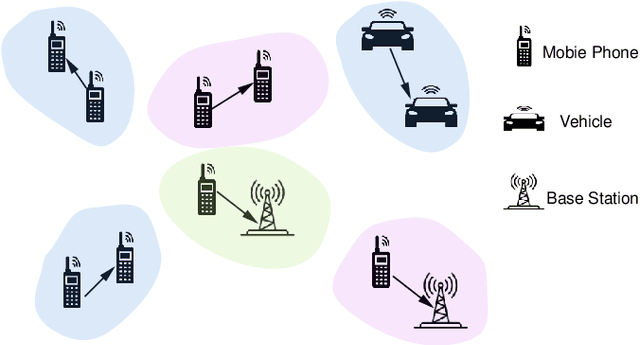
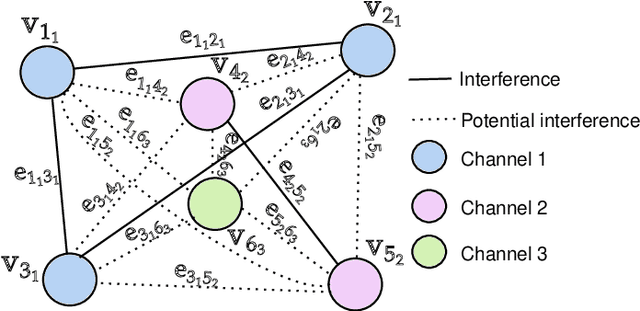
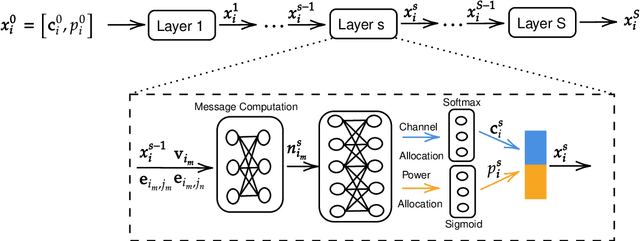
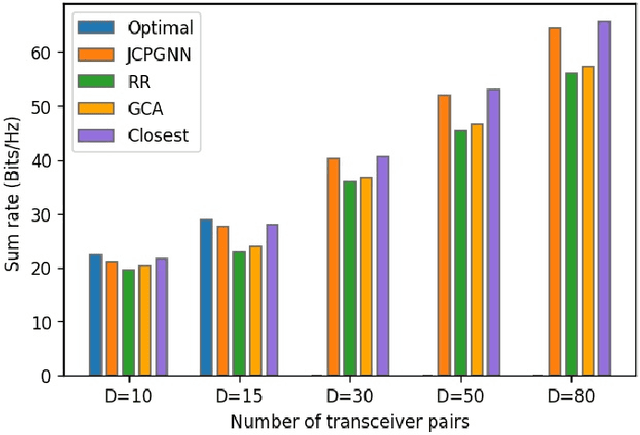
The optimal allocation of channels and power resources plays a crucial role in ensuring minimal interference, maximal data rates, and efficient energy utilisation. As a successful approach for tackling resource management problems in wireless networks, Graph Neural Networks (GNNs) have attracted a lot of attention. This article proposes a GNN-based algorithm to address the joint resource allocation problem in heterogeneous wireless networks. Concretely, we model the heterogeneous wireless network as a heterogeneous graph and then propose a graph neural network structure intending to allocate the available channels and transmit power to maximise the network throughput. Our proposed joint channel and power allocation graph neural network (JCPGNN) comprises a shared message computation layer and two task-specific layers, with a dedicated focus on channel and power allocation tasks, respectively. Comprehensive experiments demonstrate that the proposed algorithm achieves satisfactory performance but with higher computational efficiency compared to traditional optimisation algorithms.
Accelerating Graph Neural Networks via Edge Pruning for Power Allocation in Wireless Networks
May 22, 2023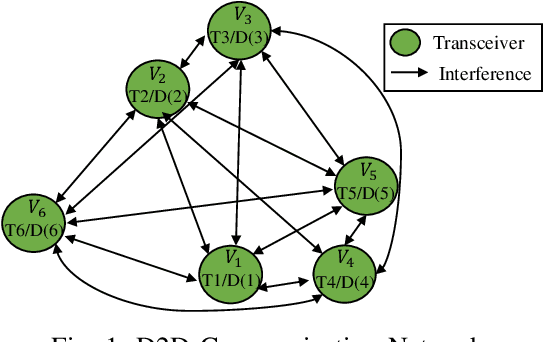
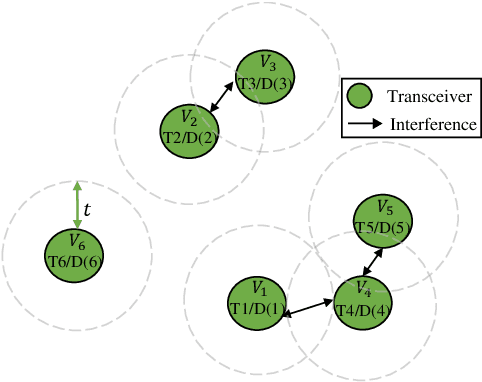
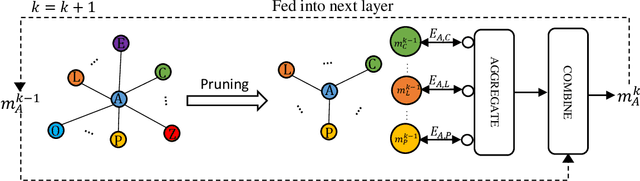
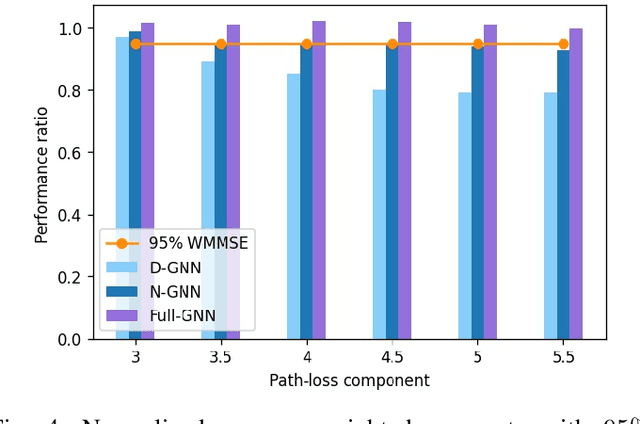
Neural Networks (GNNs) have recently emerged as a promising approach to tackling power allocation problems in wireless networks. Since unpaired transmitters and receivers are often spatially distant, the distanced-based threshold is proposed to reduce the computation time by excluding or including the channel state information in GNNs. In this paper, we are the first to introduce a neighbour-based threshold approach to GNNs to reduce the time complexity. Furthermore, we conduct a comprehensive analysis of both distance-based and neighbour-based thresholds and provide recommendations for selecting the appropriate value in different communication channel scenarios. We design the corresponding distance-based and neighbour-based Graph Neural Networks with the aim of allocating transmit powers to maximise the network throughput. Our results show that our proposed GNNs offer significant advantages in terms of reducing time complexity while preserving strong performance. Besides, we show that by choosing a suitable threshold, the time complexity is reduced from O(|V|^2) to O(|V|), where |V| is the total number of transceiver pairs.