 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Attain Communication-Efficient DNN Training? Convert, Compress, Correct
Paper and Code
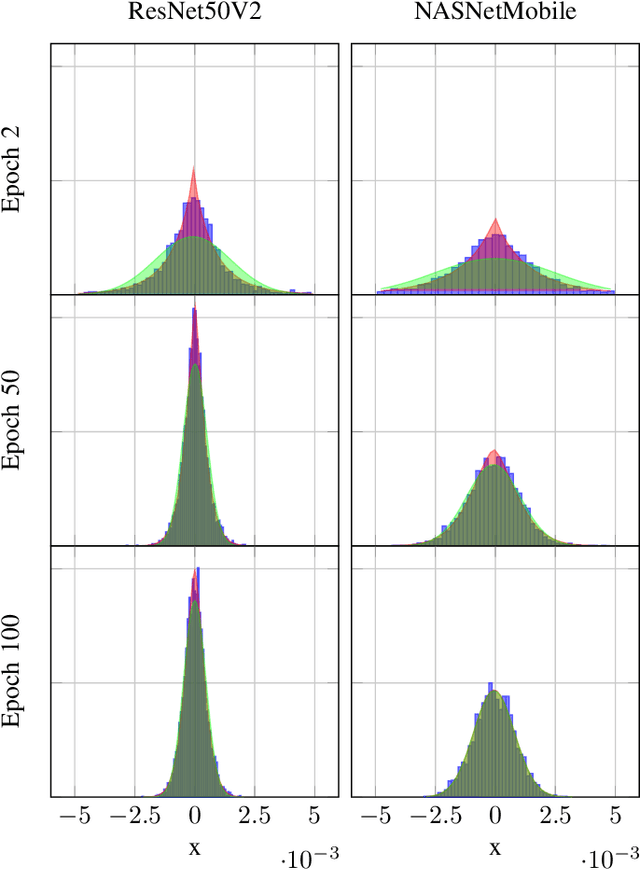
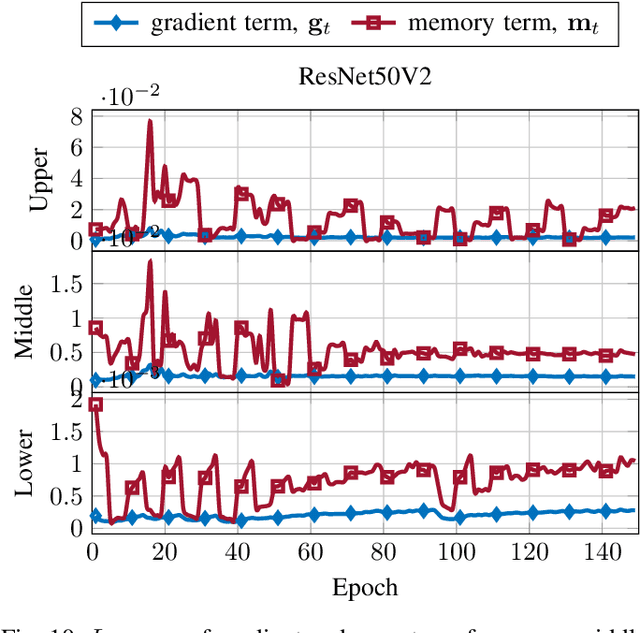
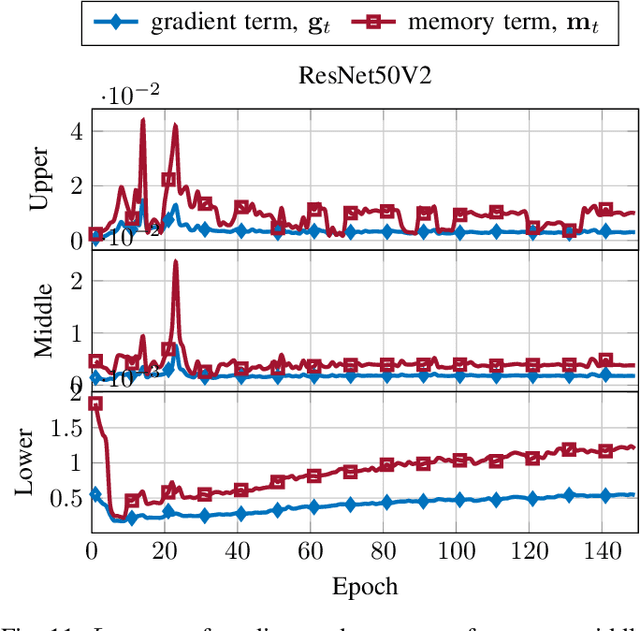

In this paper, we introduce $\mathsf{CO}_3$, an algorithm for communication-efficiency federated Deep Neural Network (DNN) training.$\mathsf{CO}_3$ takes its name from three processing applied steps which reduce the communication load when transmitting the local gradients from the remote users to the Parameter Server.Namely:(i) gradient quantization through floating-point conversion, (ii) lossless compression of the quantized gradient, and (iii) quantization error correction.We carefully design each of the steps above so as to minimize the loss in the distributed DNN training when the communication overhead is fixed.In particular, in the design of steps (i) and (ii), we adopt the assumption that DNN gradients are distributed according to a generalized normal distribution.This assumption is validated numerically in the paper. For step (iii), we utilize an error feedback with memory decay mechanism to correct the quantization error introduced in step (i). We argue that this coefficient, similarly to the learning rate, can be optimally tuned to improve convergence. The performance of $\mathsf{CO}_3$ is validated through numerical simulations and is shown having better accuracy and improved stability at a reduced communication payload.