 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Human-Like RL Agents Through Trajectory Optimization With Action Quantization
Nov 19, 2025Human-like agents have long been one of the goals in pursuing artificial intelligence. Although reinforcement learning (RL) has achieved superhuman performance in many domains, relatively little attention has been focused on designing human-like RL agents. As a result, many reward-driven RL agents often exhibit unnatural behaviors compared to humans, raising concerns for both interpretability and trustworthiness. To achieve human-like behavior in RL, this paper first formulates human-likeness as trajectory optimization, where the objective is to find an action sequence that closely aligns with human behavior while also maximizing rewards, and adapts the classic receding-horizon control to human-like learning as a tractable and efficient implementation. To achieve this, we introduce Macro Action Quantization (MAQ), a human-like RL framework that distills human demonstrations into macro actions via Vector-Quantized VAE. Experiments on D4RL Adroit benchmarks show that MAQ significantly improves human-likeness, increasing trajectory similarity scores, and achieving the highest human-likeness rankings among all RL agents in the human evaluation study. Our results also demonstrate that MAQ can be easily integrated into various off-the-shelf RL algorithms, opening a promising direction for learning human-like RL agents. Our code is available at https://rlg.iis.sinica.edu.tw/papers/MAQ.
PPO-Clip Attains Global Optimality: Towards Deeper Understandings of Clipping
Dec 19, 2023Proximal Policy Optimization algorithm employing a clipped surrogate objective (PPO-Clip) is a prominent exemplar of the policy optimization methods. However, despite its remarkable empirical success, PPO-Clip lacks theoretical substantiation to date. In this paper, we contribute to the field by establishing the first global convergence results of a PPO-Clip variant in both tabular and neural function approximation settings. Our findings highlight the $O(1/\sqrt{T})$ min-iterate convergence rate specifically in the context of neural function approximation. We tackle the inherent challenges in analyzing PPO-Clip through three central concepts: (i) We introduce a generalized version of the PPO-Clip objective, illuminated by its connection with the hinge loss. (ii) Employing entropic mirror descent, we establish asymptotic convergence for tabular PPO-Clip with direct policy parameterization. (iii) Inspired by the tabular analysis, we streamline convergence analysis by introducing a two-step policy improvement approach. This decouples policy search from complex neural policy parameterization using a regression-based update scheme. Furthermore, we gain deeper insights into the efficacy of PPO-Clip by interpreting these generalized objectives. Our theoretical findings also mark the first characterization of the influence of the clipping mechanism on PPO-Clip convergence. Importantly, the clipping range affects only the pre-constant of the convergence rate.
Residual Scheduling: A New Reinforcement Learning Approach to Solving Job Shop Scheduling Problem
Oct 03, 2023Job-shop scheduling problem (JSP) is a mathematical optimization problem widely used in industries like manufacturing, and flexible JSP (FJSP) is also a common variant. Since they are NP-hard, it is intractable to find the optimal solution for all cases within reasonable times. Thus, it becomes important to develop efficient heuristics to solve JSP/FJSP. A kind of method of solving scheduling problems is construction heuristics, which constructs scheduling solutions via heuristics. Recently, many methods for construction heuristics leverage deep reinforcement learning (DRL) with graph neural networks (GNN). In this paper, we propose a new approach, named residual scheduling, to solving JSP/FJSP. In this new approach, we remove irrelevant machines and jobs such as those finished, such that the states include the remaining (or relevant) machines and jobs only. Our experiments show that our approach reaches state-of-the-art (SOTA) among all known construction heuristics on most well-known open JSP and FJSP benchmarks. In addition, we also observe that even though our model is trained for scheduling problems of smaller sizes, our method still performs well for scheduling problems of large sizes. Interestingly in our experiments, our approach even reaches zero gap for 49 among 50 JSP instances whose job numbers are more than 150 on 20 machines.
Towards Human-Like RL: Taming Non-Naturalistic Behavior in Deep RL via Adaptive Behavioral Costs in 3D Games
Sep 27, 2023In this paper, we propose a new approach called Adaptive Behavioral Costs in Reinforcement Learning (ABC-RL) for training a human-like agent with competitive strength. While deep reinforcement learning agents have recently achieved superhuman performance in various video games, some of these unconstrained agents may exhibit actions, such as shaking and spinning, that are not typically observed in human behavior, resulting in peculiar gameplay experiences. To behave like humans and retain similar performance, ABC-RL augments behavioral limitations as cost signals in reinforcement learning with dynamically adjusted weights. Unlike traditional constrained policy optimization, we propose a new formulation that minimizes the behavioral costs subject to a constraint of the value function. By leveraging the augmented Lagrangian, our approach is an approximation of the Lagrangian adjustment, which handles the trade-off between the performance and the human-like behavior. Through experiments conducted on 3D games in DMLab-30 and Unity ML-Agents Toolkit, we demonstrate that ABC-RL achieves the same performance level while significantly reducing instances of shaking and spinning. These findings underscore the effectiveness of our proposed approach in promoting more natural and human-like behavior during gameplay.
Hinge Policy Optimization: Rethinking Policy Improvement and Reinterpreting PPO
Oct 26, 2021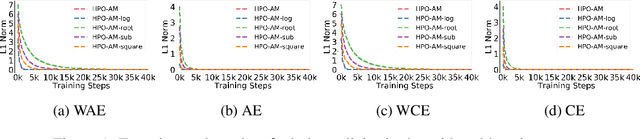

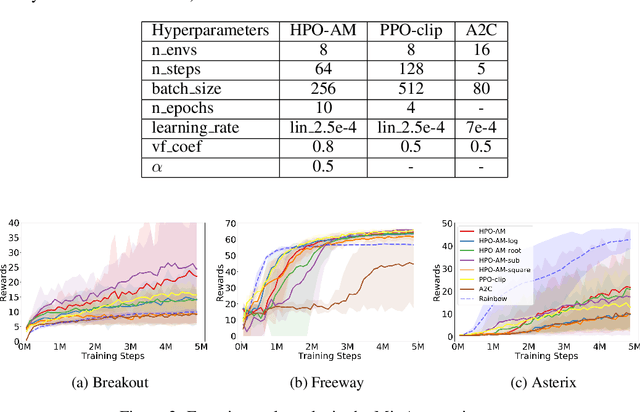
Policy optimization is a fundamental principle for designing reinforcement learning algorithms, and one example is the proximal policy optimization algorithm with a clipped surrogate objective (PPO-clip), which has been popularly used in deep reinforcement learning due to its simplicity and effectiveness. Despite its superior empirical performance, PPO-clip has not been justified via theoretical proof up to date. This paper proposes to rethink policy optimization and reinterpret the theory of PPO-clip based on hinge policy optimization (HPO), called to improve policy by hinge loss in this paper. Specifically, we first identify sufficient conditions of state-wise policy improvement and then rethink policy update as solving a large-margin classification problem with hinge loss. By leveraging various types of classifiers, the proposed design opens up a whole new family of policy-based algorithms, including the PPO-clip as a special case. Based on this construct, we prove that these algorithms asymptotically attain a globally optimal policy. To our knowledge, this is the first ever that can prove global convergence to an optimal policy for a variant of PPO-clip. We corroborate the performance of a variety of HPO algorithms through experiments and an ablation study.