 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHinge Policy Optimization: Rethinking Policy Improvement and Reinterpreting PPO
Oct 26, 2021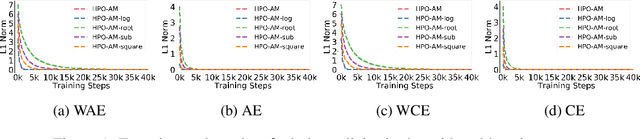

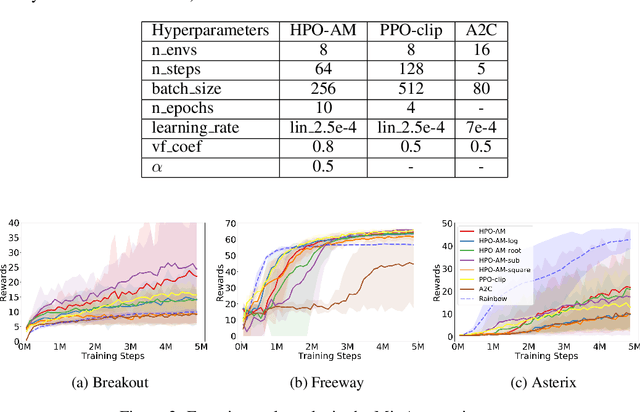
Policy optimization is a fundamental principle for designing reinforcement learning algorithms, and one example is the proximal policy optimization algorithm with a clipped surrogate objective (PPO-clip), which has been popularly used in deep reinforcement learning due to its simplicity and effectiveness. Despite its superior empirical performance, PPO-clip has not been justified via theoretical proof up to date. This paper proposes to rethink policy optimization and reinterpret the theory of PPO-clip based on hinge policy optimization (HPO), called to improve policy by hinge loss in this paper. Specifically, we first identify sufficient conditions of state-wise policy improvement and then rethink policy update as solving a large-margin classification problem with hinge loss. By leveraging various types of classifiers, the proposed design opens up a whole new family of policy-based algorithms, including the PPO-clip as a special case. Based on this construct, we prove that these algorithms asymptotically attain a globally optimal policy. To our knowledge, this is the first ever that can prove global convergence to an optimal policy for a variant of PPO-clip. We corroborate the performance of a variety of HPO algorithms through experiments and an ablation study.
Reinforcement Learning Trajectory Generation and Control for Aggressive Perching on Vertical Walls with Quadrotors
Mar 04, 2021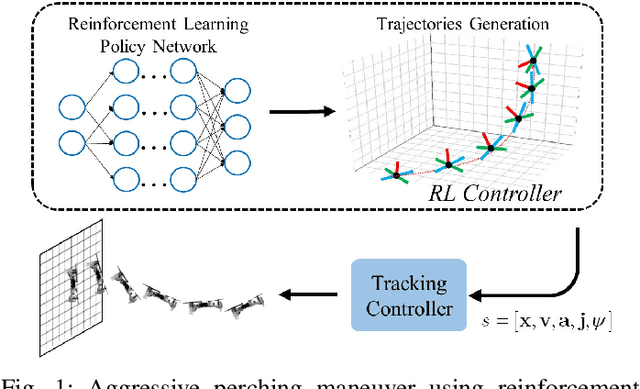
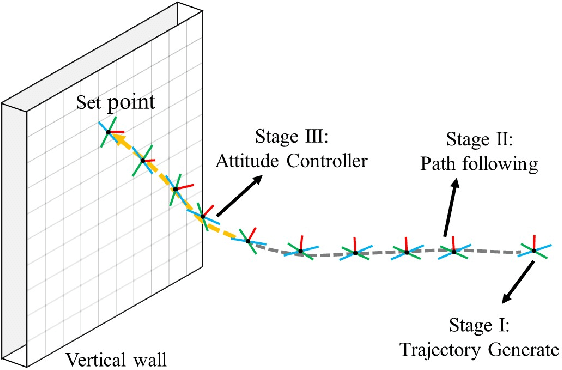
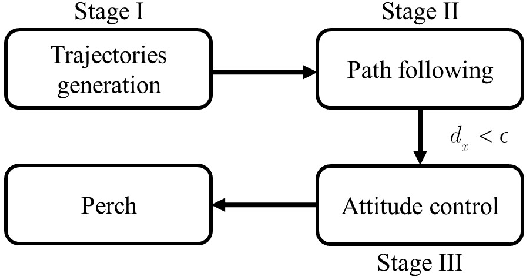
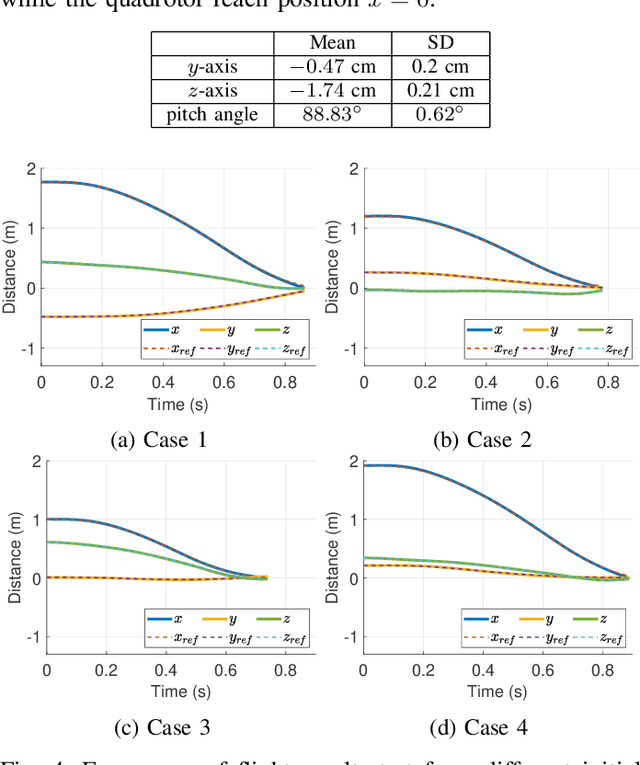
Micro aerial vehicles are widely being researched and employed due to their relative low operation costs and high flexibility in various applications. We study the under-actuated quadrotor perching problem, designing a trajectory planner and controller which generates feasible trajectories and drives quadrotors to desired state in state space. This paper proposes a trajectory generating and tracking method for quadrotor perching that takes the advantages of reinforcement learning controller and traditional controller. The trained low-level reinforcement learning controller would manipulate quadrotor toward the perching point in simulation environment. Once the simulated quadrotor has successfully perched, the relative trajectory information in simulation will be sent to tracking controller on real quadrotor and start the actual perching task. Generating feasible trajectories via the trained reinforcement learning controller requires less time, and the traditional trajectory tracking controller could easily be modified to control the quadrotor and mathematically analysis its stability and robustness. We show that this approach permits the control structure of trajectories and controllers enabling such aggressive maneuvers perching on vertical surfaces with high precision.
Towards Combining On-Off-Policy Methods for Real-World Applications
Apr 24, 2019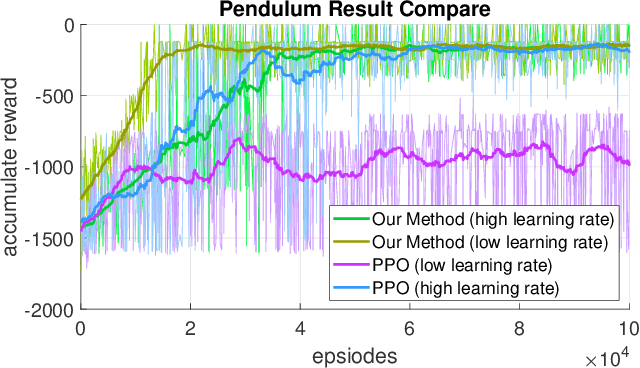
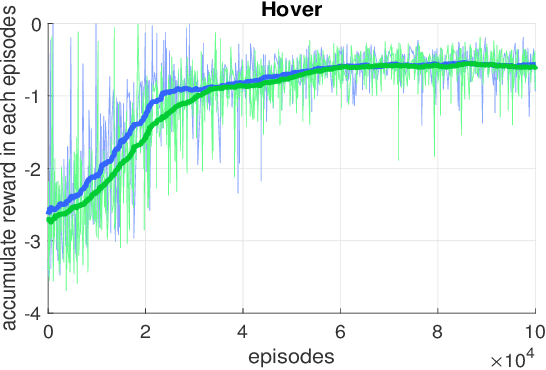
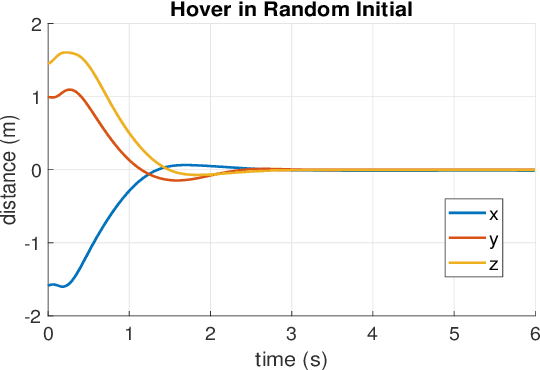
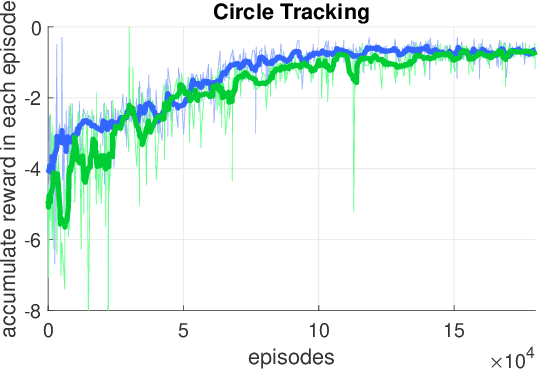
In this paper, we point out a fundamental property of the objective in reinforcement learning, with which we can reformulate the policy gradient objective into a perceptron-like loss function, removing the need to distinguish between on and off policy training. Namely, we posit that it is sufficient to only update a policy $\pi$ for cases that satisfy the condition $A(\frac{\pi}{\mu}-1)\leq0$, where $A$ is the advantage, and $\mu$ is another policy. Furthermore, we show via theoretic derivation that a perceptron-like loss function matches the clipped surrogate objective for PPO. With our new formulation, the policies $\pi$ and $\mu$ can be arbitrarily apart in theory, effectively enabling off-policy training. To examine our derivations, we can combine the on-policy PPO clipped surrogate (which we show to be equivalent with one instance of the new reformation) with the off-policy IMPALA method. We first verify the combined method on the OpenAI Gym pendulum toy problem. Next, we use our method to train a quadrotor position controller in a simulator. Our trained policy is efficient and lightweight enough to perform in a low cost micro-controller at a minimum update rate of 500 Hz. For the quadrotor, we show two experiments to verify our method and demonstrate performance: 1) hovering at a fixed position, and 2) tracking along a specific trajectory. In preliminary trials, we are also able to apply the method to a real-world quadrotor.