 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Learning from Observation with Model Misspecification
Feb 15, 2022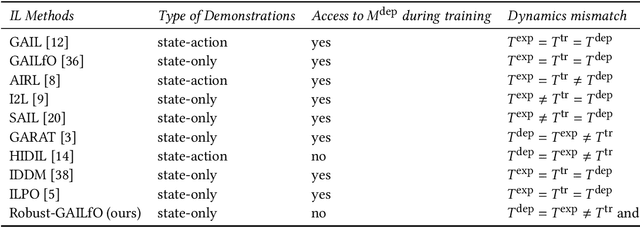
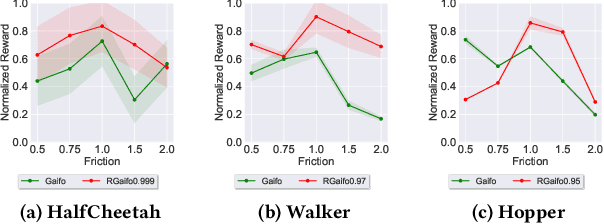
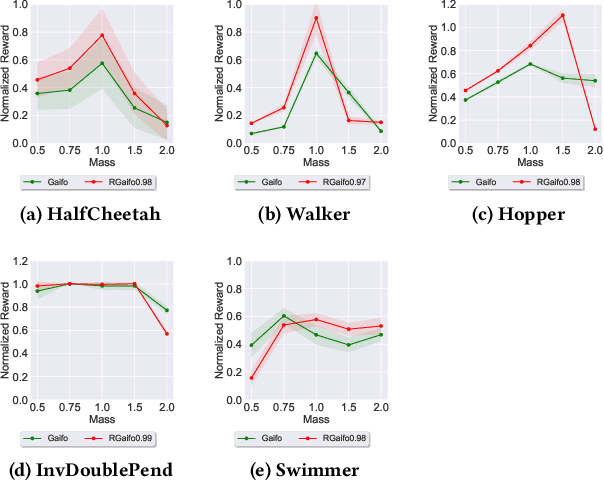
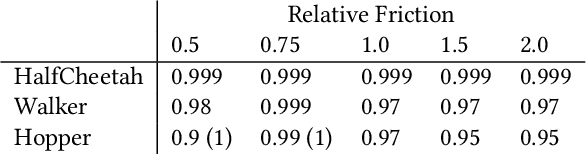
Imitation learning (IL) is a popular paradigm for training policies in robotic systems when specifying the reward function is difficult. However, despite the success of IL algorithms, they impose the somewhat unrealistic requirement that the expert demonstrations must come from the same domain in which a new imitator policy is to be learned. We consider a practical setting, where (i) state-only expert demonstrations from the real (deployment) environment are given to the learner, (ii) the imitation learner policy is trained in a simulation (training) environment whose transition dynamics is slightly different from the real environment, and (iii) the learner does not have any access to the real environment during the training phase beyond the batch of demonstrations given. Most of the current IL methods, such as generative adversarial imitation learning and its state-only variants, fail to imitate the optimal expert behavior under the above setting. By leveraging insights from the Robust reinforcement learning (RL) literature and building on recent adversarial imitation approaches, we propose a robust IL algorithm to learn policies that can effectively transfer to the real environment without fine-tuning. Furthermore, we empirically demonstrate on continuous-control benchmarks that our method outperforms the state-of-the-art state-only IL method in terms of the zero-shot transfer performance in the real environment and robust performance under different testing conditions.
Reinforcement Learning Trajectory Generation and Control for Aggressive Perching on Vertical Walls with Quadrotors
Mar 04, 2021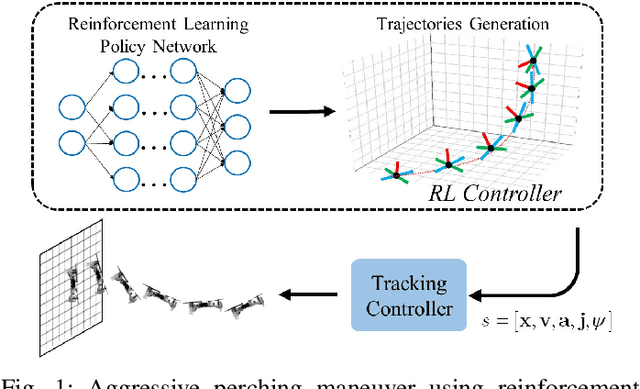
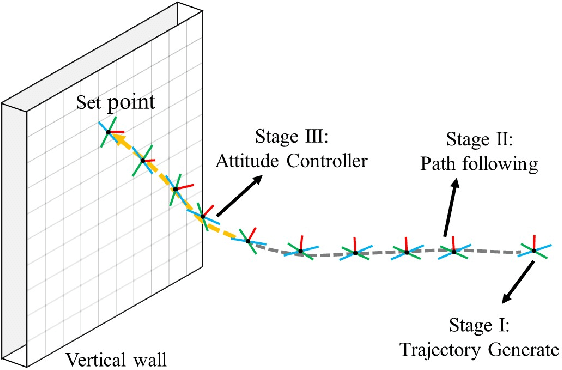
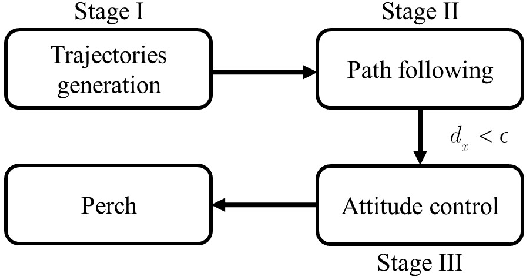
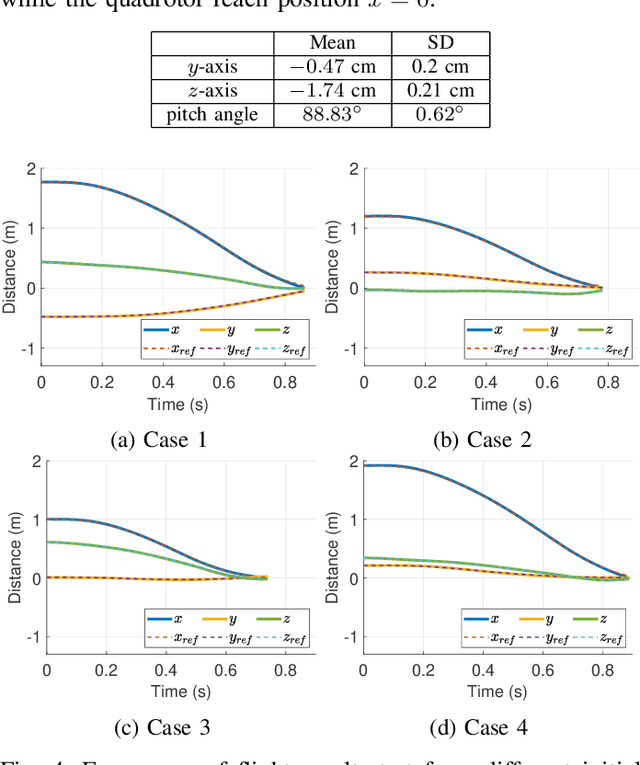
Micro aerial vehicles are widely being researched and employed due to their relative low operation costs and high flexibility in various applications. We study the under-actuated quadrotor perching problem, designing a trajectory planner and controller which generates feasible trajectories and drives quadrotors to desired state in state space. This paper proposes a trajectory generating and tracking method for quadrotor perching that takes the advantages of reinforcement learning controller and traditional controller. The trained low-level reinforcement learning controller would manipulate quadrotor toward the perching point in simulation environment. Once the simulated quadrotor has successfully perched, the relative trajectory information in simulation will be sent to tracking controller on real quadrotor and start the actual perching task. Generating feasible trajectories via the trained reinforcement learning controller requires less time, and the traditional trajectory tracking controller could easily be modified to control the quadrotor and mathematically analysis its stability and robustness. We show that this approach permits the control structure of trajectories and controllers enabling such aggressive maneuvers perching on vertical surfaces with high precision.
Robust Inverse Reinforcement Learning under Transition Dynamics Mismatch
Jul 02, 2020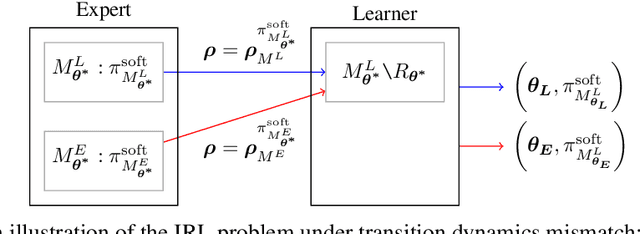

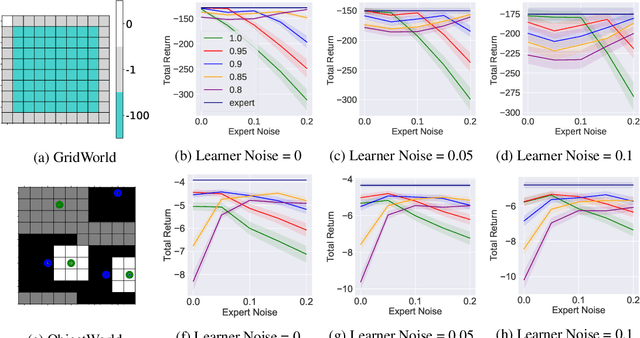

We study the inverse reinforcement learning (IRL) problem under the \emph{transition dynamics mismatch} between the expert and the learner. In particular, we consider the Maximum Causal Entropy (MCE) IRL learner model and provide an upper bound on the learner's performance degradation based on the $\ell_1$-distance between the two transition dynamics of the expert and the learner. Then, by leveraging insights from the Robust RL literature, we propose a robust MCE IRL algorithm, which is a principled approach to help with this mismatch issue. Finally, we empirically demonstrate the stable performance of our algorithm compared to the standard MCE IRL algorithm under transition mismatches in finite MDP problems.
Robust Reinforcement Learning via Adversarial training with Langevin Dynamics
Feb 14, 2020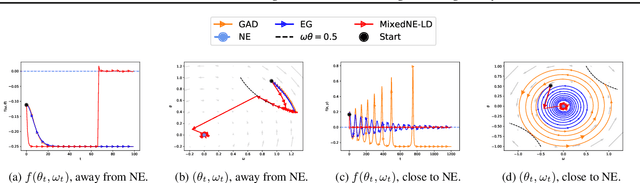

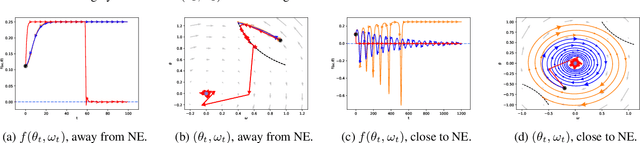

We introduce a sampling perspective to tackle the challenging task of training robust Reinforcement Learning (RL) agents. Leveraging the powerful Stochastic Gradient Langevin Dynamics, we present a novel, scalable two-player RL algorithm, which is a sampling variant of the two-player policy gradient method. Our algorithm consistently outperforms existing baselines, in terms of generalization across different training and testing conditions, on several MuJoCo environments. Our experiments also show that, even for objective functions that entirely ignore potential environmental shifts, our sampling approach remains highly robust in comparison to standard RL algorithms.