 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTANet: Triplet Attention Network for All-In-One Adverse Weather Image Restoration
Oct 10, 2024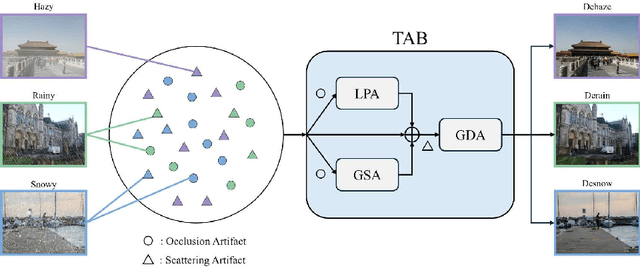
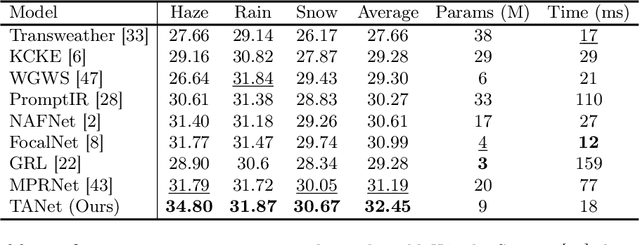
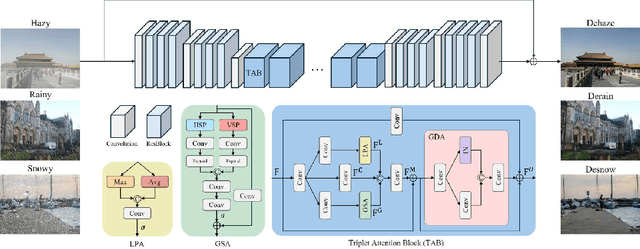
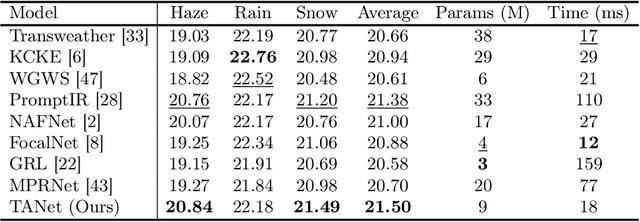
Adverse weather image restoration aims to remove unwanted degraded artifacts, such as haze, rain, and snow, caused by adverse weather conditions. Existing methods achieve remarkable results for addressing single-weather conditions. However, they face challenges when encountering unpredictable weather conditions, which often happen in real-world scenarios. Although different weather conditions exhibit different degradation patterns, they share common characteristics that are highly related and complementary, such as occlusions caused by degradation patterns, color distortion, and contrast attenuation due to the scattering of atmospheric particles. Therefore, we focus on leveraging common knowledge across multiple weather conditions to restore images in a unified manner. In this paper, we propose a Triplet Attention Network (TANet) to efficiently and effectively address all-in-one adverse weather image restoration. TANet consists of Triplet Attention Block (TAB) that incorporates three types of attention mechanisms: Local Pixel-wise Attention (LPA) and Global Strip-wise Attention (GSA) to address occlusions caused by non-uniform degradation patterns, and Global Distribution Attention (GDA) to address color distortion and contrast attenuation caused by atmospheric phenomena. By leveraging common knowledge shared across different weather conditions, TANet successfully addresses multiple weather conditions in a unified manner. Experimental results show that TANet efficiently and effectively achieves state-of-the-art performance in all-in-one adverse weather image restoration. The source code is available at https://github.com/xhuachris/TANet-ACCV-2024.
Domain-adaptive Video Deblurring via Test-time Blurring
Jul 12, 2024



Dynamic scene video deblurring aims to remove undesirable blurry artifacts captured during the exposure process. Although previous video deblurring methods have achieved impressive results, they suffer from significant performance drops due to the domain gap between training and testing videos, especially for those captured in real-world scenarios. To address this issue, we propose a domain adaptation scheme based on a blurring model to achieve test-time fine-tuning for deblurring models in unseen domains. Since blurred and sharp pairs are unavailable for fine-tuning during inference, our scheme can generate domain-adaptive training pairs to calibrate a deblurring model for the target domain. First, a Relative Sharpness Detection Module is proposed to identify relatively sharp regions from the blurry input images and regard them as pseudo-sharp images. Next, we utilize a blurring model to produce blurred images based on the pseudo-sharp images extracted during testing. To synthesize blurred images in compliance with the target data distribution, we propose a Domain-adaptive Blur Condition Generation Module to create domain-specific blur conditions for the blurring model. Finally, the generated pseudo-sharp and blurred pairs are used to fine-tune a deblurring model for better performance. Extensive experimental results demonstrate that our approach can significantly improve state-of-the-art video deblurring methods, providing performance gains of up to 7.54dB on various real-world video deblurring datasets. The source code is available at https://github.com/Jin-Ting-He/DADeblur.
PANet: A Physics-guided Parametric Augmentation Net for Image Dehazing by Hazing
Apr 14, 2024Image dehazing faces challenges when dealing with hazy images in real-world scenarios. A huge domain gap between synthetic and real-world haze images degrades dehazing performance in practical settings. However, collecting real-world image datasets for training dehazing models is challenging since both hazy and clean pairs must be captured under the same conditions. In this paper, we propose a Physics-guided Parametric Augmentation Network (PANet) that generates photo-realistic hazy and clean training pairs to effectively enhance real-world dehazing performance. PANet comprises a Haze-to-Parameter Mapper (HPM) to project hazy images into a parameter space and a Parameter-to-Haze Mapper (PHM) to map the resampled haze parameters back to hazy images. In the parameter space, we can pixel-wisely resample individual haze parameter maps to generate diverse hazy images with physically-explainable haze conditions unseen in the training set. Our experimental results demonstrate that PANet can augment diverse realistic hazy images to enrich existing hazy image benchmarks so as to effectively boost the performances of state-of-the-art image dehazing models.
ViStripformer: A Token-Efficient Transformer for Versatile Video Restoration
Dec 22, 2023Video restoration is a low-level vision task that seeks to restore clean, sharp videos from quality-degraded frames. One would use the temporal information from adjacent frames to make video restoration successful. Recently, the success of the Transformer has raised awareness in the computer-vision community. However, its self-attention mechanism requires much memory, which is unsuitable for high-resolution vision tasks like video restoration. In this paper, we propose ViStripformer (Video Stripformer), which utilizes spatio-temporal strip attention to catch long-range data correlations, consisting of intra-frame strip attention (Intra-SA) and inter-frame strip attention (Inter-SA) for extracting spatial and temporal information. It decomposes video frames into strip-shaped features in horizontal and vertical directions for Intra-SA and Inter-SA to address degradation patterns with various orientations and magnitudes. Besides, ViStripformer is an effective and efficient transformer architecture with much lower memory usage than the vanilla transformer. Extensive experiments show that the proposed model achieves superior results with fast inference time on video restoration tasks, including video deblurring, demoireing, and deraining.
ID-Blau: Image Deblurring by Implicit Diffusion-based reBLurring AUgmentation
Dec 18, 2023Image deblurring aims to remove undesired blurs from an image captured in a dynamic scene. Much research has been dedicated to improving deblurring performance through model architectural designs. However, there is little work on data augmentation for image deblurring. Since continuous motion causes blurred artifacts during image exposure, we aspire to develop a groundbreaking blur augmentation method to generate diverse blurred images by simulating motion trajectories in a continuous space. This paper proposes Implicit Diffusion-based reBLurring AUgmentation (ID-Blau), utilizing a sharp image paired with a controllable blur condition map to produce a corresponding blurred image. We parameterize the blur patterns of a blurred image with their orientations and magnitudes as a pixel-wise blur condition map to simulate motion trajectories and implicitly represent them in a continuous space. By sampling diverse blur conditions, ID-Blau can generate various blurred images unseen in the training set. Experimental results demonstrate that ID-Blau can produce realistic blurred images for training and thus significantly improve performance for state-of-the-art deblurring models.
Meta Transferring for Deblurring
Oct 14, 2022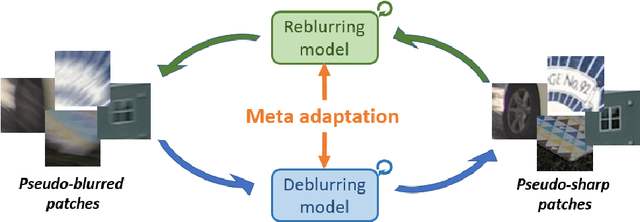
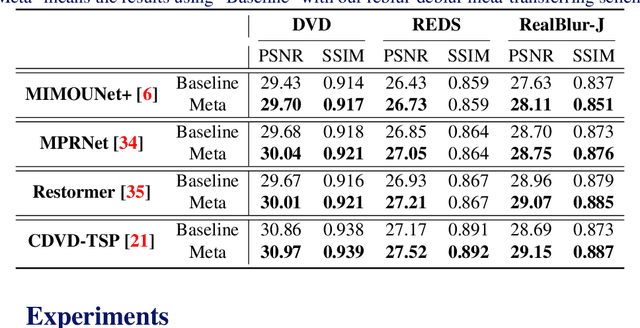
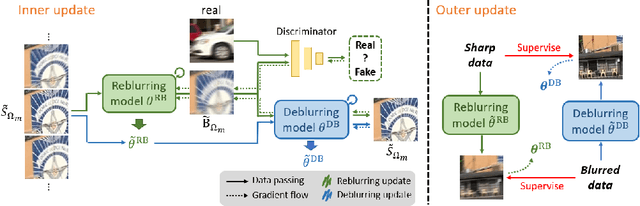

Most previous deblurring methods were built with a generic model trained on blurred images and their sharp counterparts. However, these approaches might have sub-optimal deblurring results due to the domain gap between the training and test sets. This paper proposes a reblur-deblur meta-transferring scheme to realize test-time adaptation without using ground truth for dynamic scene deblurring. Since the ground truth is usually unavailable at inference time in a real-world scenario, we leverage the blurred input video to find and use relatively sharp patches as the pseudo ground truth. Furthermore, we propose a reblurring model to extract the homogenous blur from the blurred input and transfer it to the pseudo-sharps to obtain the corresponding pseudo-blurred patches for meta-learning and test-time adaptation with only a few gradient updates. Extensive experimental results show that our reblur-deblur meta-learning scheme can improve state-of-the-art deblurring models on the DVD, REDS, and RealBlur benchmark datasets.
Stripformer: Strip Transformer for Fast Image Deblurring
Apr 10, 2022

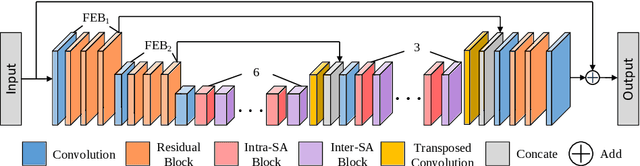
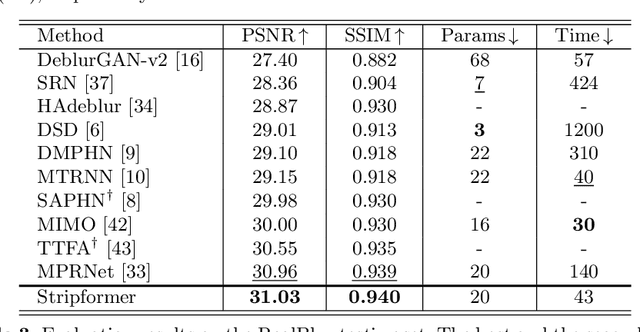
Images taken in dynamic scenes may contain unwanted motion blur, which significantly degrades visual quality. Such blur causes short- and long-range region-specific smoothing artifacts that are often directional and non-uniform, which is difficult to be removed. Inspired by the current success of transformers on computer vision and image processing tasks, we develop, Stripformer, a transformer-based architecture that constructs intra- and inter-strip tokens to reweight image features in the horizontal and vertical directions to catch blurred patterns with different orientations. It stacks interlaced intra-strip and inter-strip attention layers to reveal blur magnitudes. In addition to detecting region-specific blurred patterns of various orientations and magnitudes, Stripformer is also a token-efficient and parameter-efficient transformer model, demanding much less memory usage and computation cost than the vanilla transformer but works better without relying on tremendous training data. Experimental results show that Stripformer performs favorably against state-of-the-art models in dynamic scene deblurring.
BANet: Blur-aware Attention Networks for Dynamic Scene Deblurring
Jan 19, 2021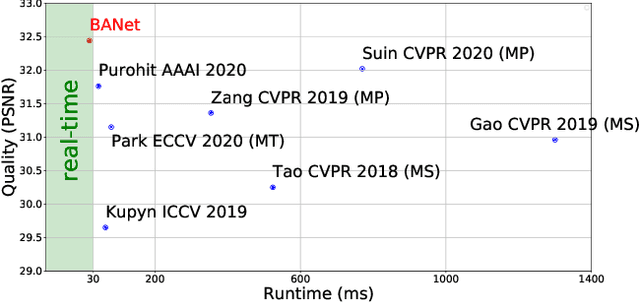
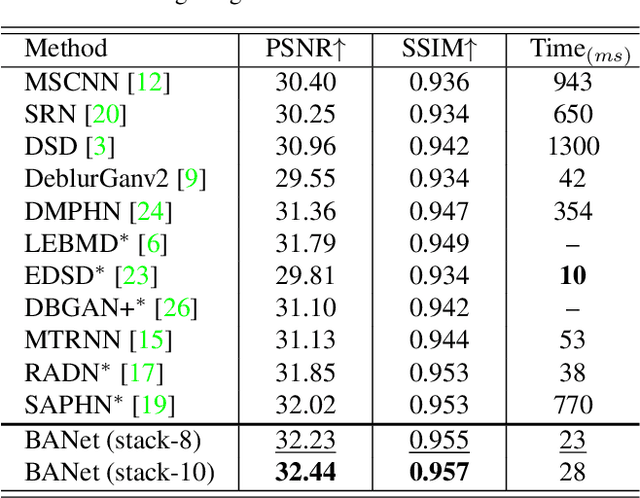
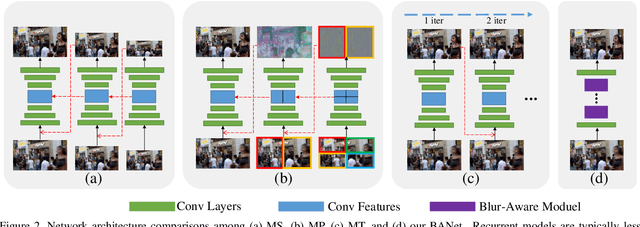
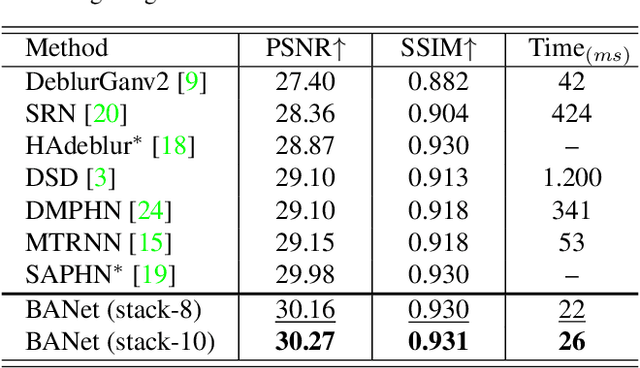
Image motion blur usually results from moving objects or camera shakes. Such blur is generally directional and non-uniform. Previous research efforts attempt to solve non-uniform blur by using self-recurrent multi-scale or multi-patch architectures accompanying with self-attention. However, using self-recurrent frameworks typically leads to a longer inference time, while inter-pixel or inter-channel self-attention may cause excessive memory usage. This paper proposes blur-aware attention networks (BANet) that accomplish accurate and efficient deblurring via a single forward pass. Our BANet utilizes region-based self-attention with multi-kernel strip pooling to disentangle blur patterns of different degrees and with cascaded parallel dilated convolution to aggregate multi-scale content features. Extensive experimental results on the GoPro and HIDE benchmarks demonstrate that the proposed BANet performs favorably against the state-of-the-art in blurred image restoration and can provide deblurred results in realtime.