 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACE: Action Concept Enhancement of Video-Language Models in Procedural Videos
Nov 23, 2024
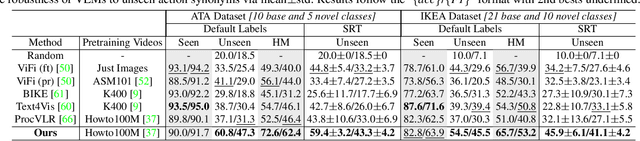
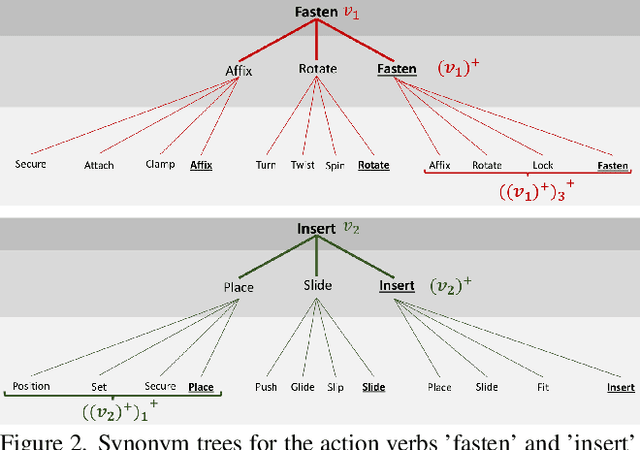
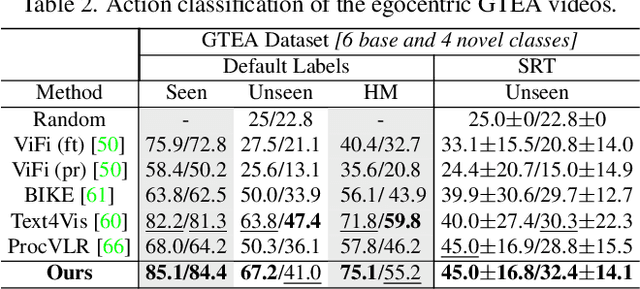
Vision-language models (VLMs) are capable of recognizing unseen actions. However, existing VLMs lack intrinsic understanding of procedural action concepts. Hence, they overfit to fixed labels and are not invariant to unseen action synonyms. To address this, we propose a simple fine-tuning technique, Action Concept Enhancement (ACE), to improve the robustness and concept understanding of VLMs in procedural action classification. ACE continually incorporates augmented action synonyms and negatives in an auxiliary classification loss by stochastically replacing fixed labels during training. This creates new combinations of action labels over the course of fine-tuning and prevents overfitting to fixed action representations. We show the enhanced concept understanding of our VLM, by visualizing the alignment of encoded embeddings of unseen action synonyms in the embedding space. Our experiments on the ATA, IKEA and GTEA datasets demonstrate the efficacy of ACE in domains of cooking and assembly leading to significant improvements in zero-shot action classification while maintaining competitive performance on seen actions.