 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-fidelity Hamiltonian Monte Carlo
May 08, 2024


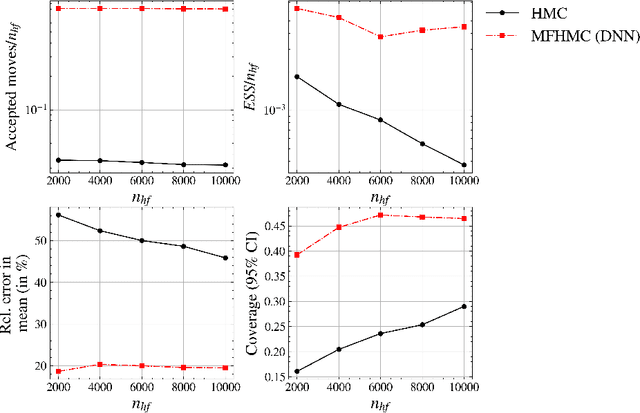
Numerous applications in biology, statistics, science, and engineering require generating samples from high-dimensional probability distributions. In recent years, the Hamiltonian Monte Carlo (HMC) method has emerged as a state-of-the-art Markov chain Monte Carlo technique, exploiting the shape of such high-dimensional target distributions to efficiently generate samples. Despite its impressive empirical success and increasing popularity, its wide-scale adoption remains limited due to the high computational cost of gradient calculation. Moreover, applying this method is impossible when the gradient of the posterior cannot be computed (for example, with black-box simulators). To overcome these challenges, we propose a novel two-stage Hamiltonian Monte Carlo algorithm with a surrogate model. In this multi-fidelity algorithm, the acceptance probability is computed in the first stage via a standard HMC proposal using an inexpensive differentiable surrogate model, and if the proposal is accepted, the posterior is evaluated in the second stage using the high-fidelity (HF) numerical solver. Splitting the standard HMC algorithm into these two stages allows for approximating the gradient of the posterior efficiently, while producing accurate posterior samples by using HF numerical solvers in the second stage. We demonstrate the effectiveness of this algorithm for a range of problems, including linear and nonlinear Bayesian inverse problems with in-silico data and experimental data. The proposed algorithm is shown to seamlessly integrate with various low-fidelity and HF models, priors, and datasets. Remarkably, our proposed method outperforms the traditional HMC algorithm in both computational and statistical efficiency by several orders of magnitude, all while retaining or improving the accuracy in computed posterior statistics.
Effective approaches to disaster evacuation during a COVID-like pandemic
Aug 29, 2022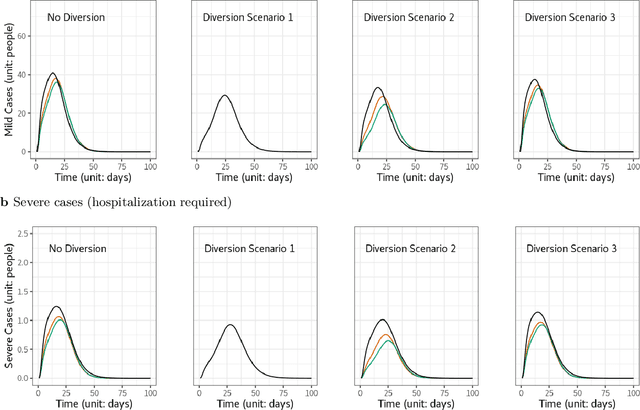
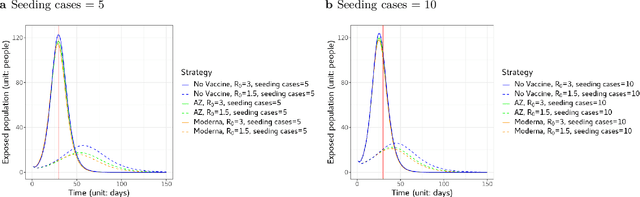
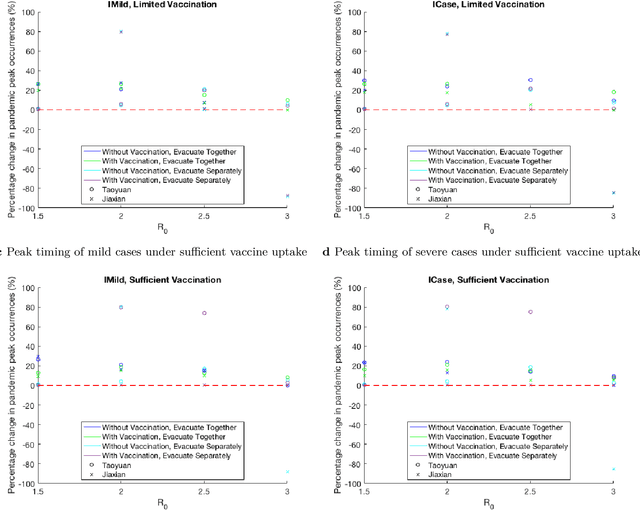
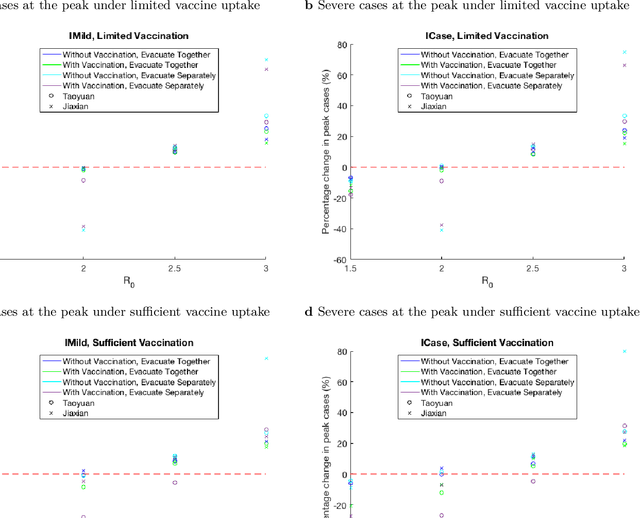
Since COVID-19 vaccines became available, no studies have quantified how different disaster evacuation strategies can mitigate pandemic risks in shelters. Therefore, we applied an age-structured epidemiological model, known as the Susceptible-Exposed-Infectious-Recovered (SEIR) model, to investigate to what extent different vaccine uptake levels and the Diversion protocol implemented in Taiwan decrease infections and delay pandemic peak occurrences. Taiwan's Diversion protocol involves diverting those in self-quarantine due to exposure, thus preventing them from mingling with the general public at a congregate shelter. The Diversion protocol, combined with sufficient vaccine uptake, can decrease the maximum number of infections and delay outbreaks relative to scenarios without such strategies. When the diversion of all exposed people is not possible, or vaccine uptake is insufficient, the Diversion protocol is still valuable. Furthermore, a group of evacuees that consists primarily of a young adult population tends to experience pandemic peak occurrences sooner and have up to 180% more infections than does a majority elderly group when the Diversion protocol is implemented. However, when the Diversion protocol is not enforced, the majority elderly group suffers from up to 20% more severe cases than the majority young adult group.
Improving debris flow evacuation alerts in Taiwan using machine learning
Aug 27, 2022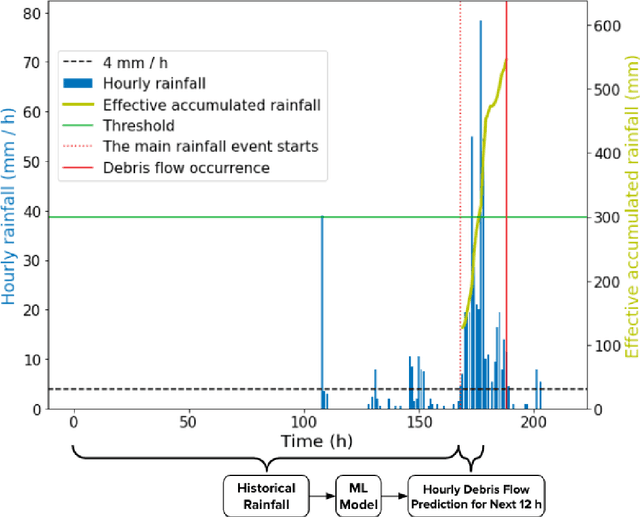
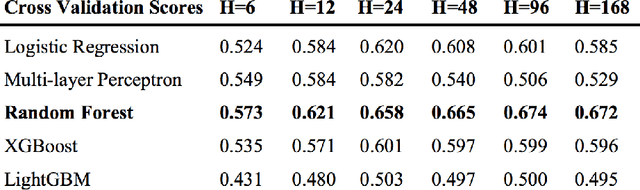
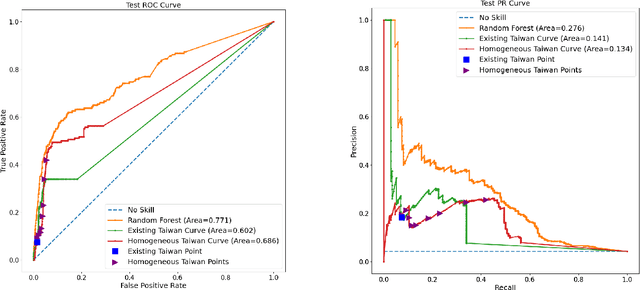
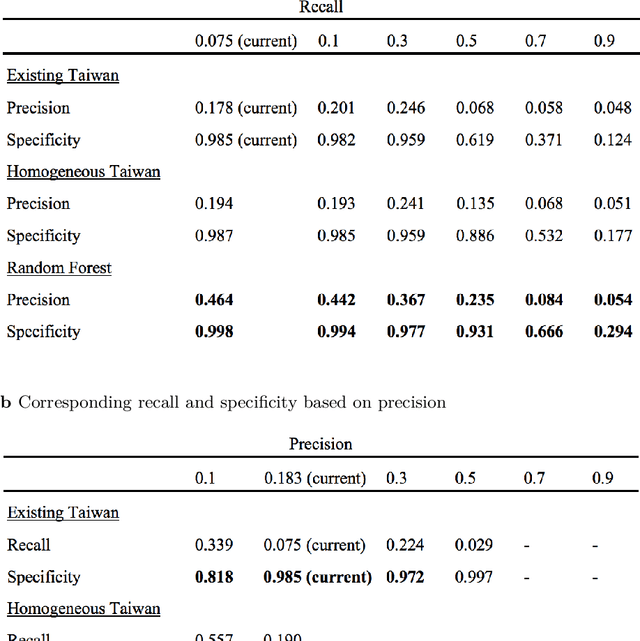
Taiwan has the highest susceptibility to and fatalities from debris flows worldwide. The existing debris flow warning system in Taiwan, which uses a time-weighted measure of rainfall, leads to alerts when the measure exceeds a predefined threshold. However, this system generates many false alarms and misses a substantial fraction of the actual debris flows. Towards improving this system, we implemented five machine learning models that input historical rainfall data and predict whether a debris flow will occur within a selected time. We found that a random forest model performed the best among the five models and outperformed the existing system in Taiwan. Furthermore, we identified the rainfall trajectories strongly related to debris flow occurrences and explored trade-offs between the risks of missing debris flows versus frequent false alerts. These results suggest the potential for machine learning models trained on hourly rainfall data alone to save lives while reducing false alerts.
Variational encoder geostatistical analysis (VEGAS) with an application to large scale riverine bathymetry
Nov 23, 2021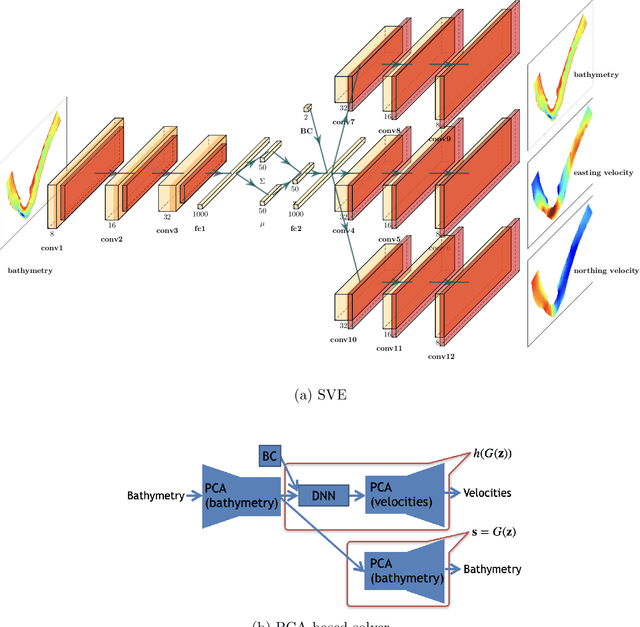
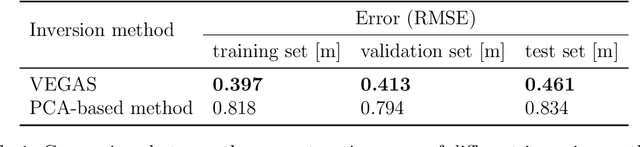
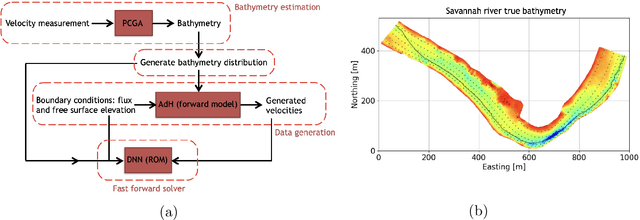
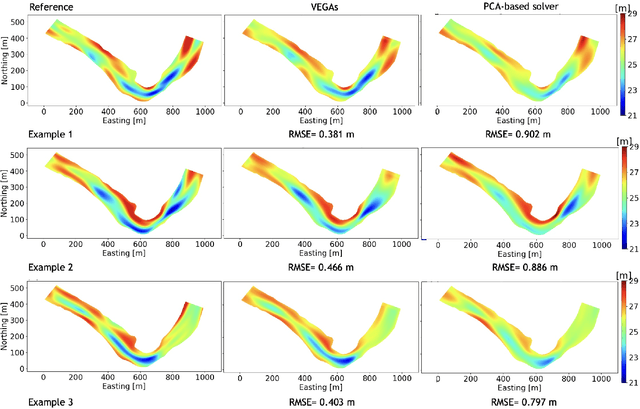
Estimation of riverbed profiles, also known as bathymetry, plays a vital role in many applications, such as safe and efficient inland navigation, prediction of bank erosion, land subsidence, and flood risk management. The high cost and complex logistics of direct bathymetry surveys, i.e., depth imaging, have encouraged the use of indirect measurements such as surface flow velocities. However, estimating high-resolution bathymetry from indirect measurements is an inverse problem that can be computationally challenging. Here, we propose a reduced-order model (ROM) based approach that utilizes a variational autoencoder (VAE), a type of deep neural network with a narrow layer in the middle, to compress bathymetry and flow velocity information and accelerate bathymetry inverse problems from flow velocity measurements. In our application, the shallow-water equations (SWE) with appropriate boundary conditions (BCs), e.g., the discharge and/or the free surface elevation, constitute the forward problem, to predict flow velocity. Then, ROMs of the SWEs are constructed on a nonlinear manifold of low dimensionality through a variational encoder. Estimation with uncertainty quantification (UQ) is performed on the low-dimensional latent space in a Bayesian setting. We have tested our inversion approach on a one-mile reach of the Savannah River, GA, USA. Once the neural network is trained (offline stage), the proposed technique can perform the inversion operation orders of magnitude faster than traditional inversion methods that are commonly based on linear projections, such as principal component analysis (PCA), or the principal component geostatistical approach (PCGA). Furthermore, tests show that the algorithm can estimate the bathymetry with good accuracy even with sparse flow velocity measurements.
Deep learning-based fast solver of the shallow water equations
Nov 23, 2021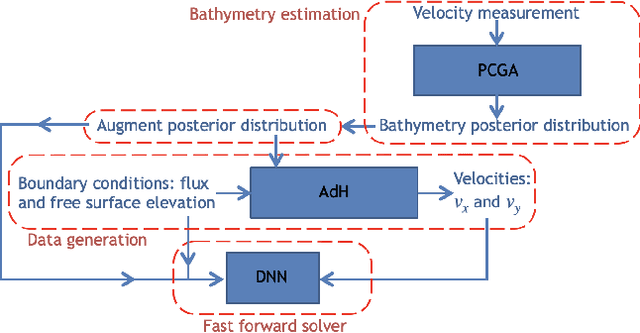
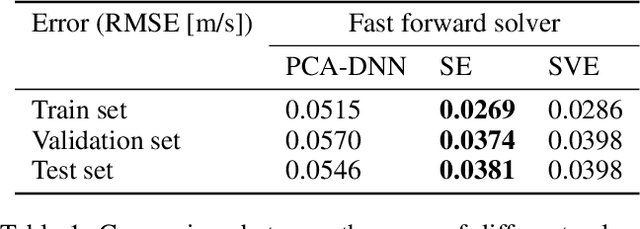
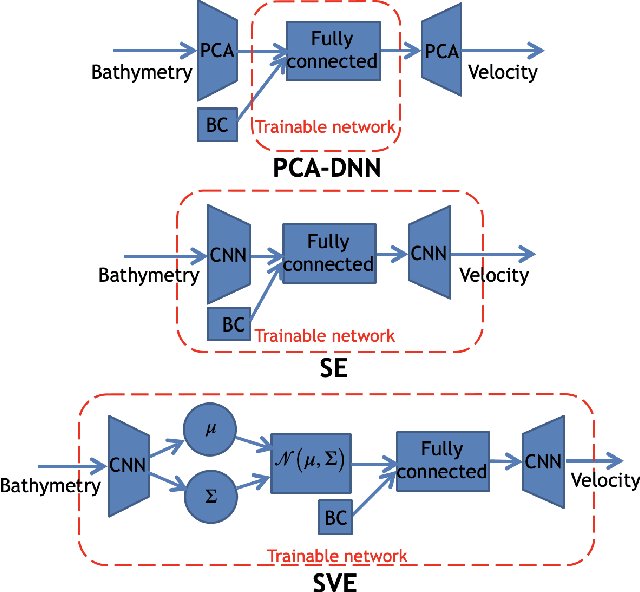

Fast and reliable prediction of river flow velocities is important in many applications, including flood risk management. The shallow water equations (SWEs) are commonly used for this purpose. However, traditional numerical solvers of the SWEs are computationally expensive and require high-resolution riverbed profile measurement (bathymetry). In this work, we propose a two-stage process in which, first, using the principal component geostatistical approach (PCGA) we estimate the probability density function of the bathymetry from flow velocity measurements, and then use machine learning (ML) algorithms to obtain a fast solver for the SWEs. The fast solver uses realizations from the posterior bathymetry distribution and takes as input the prescribed range of BCs. The first stage allows us to predict flow velocities without direct measurement of the bathymetry. Furthermore, we augment the bathymetry posterior distribution to a more general class of distributions before providing them as inputs to ML algorithm in the second stage. This allows the solver to incorporate future direct bathymetry measurements into the flow velocity prediction for improved accuracy, even if the bathymetry changes over time compared to its original indirect estimation. We propose and benchmark three different solvers, referred to as PCA-DNN (principal component analysis-deep neural network), SE (supervised encoder), and SVE (supervised variational encoder), and validate them on the Savannah river, Augusta, GA. Our results show that the fast solvers are capable of predicting flow velocities for different bathymetry and BCs with good accuracy, at a computational cost that is significantly lower than the cost of solving the full boundary value problem with traditional methods.
Routing algorithms as tools for integrating social distancing with emergency evacuation
Mar 05, 2021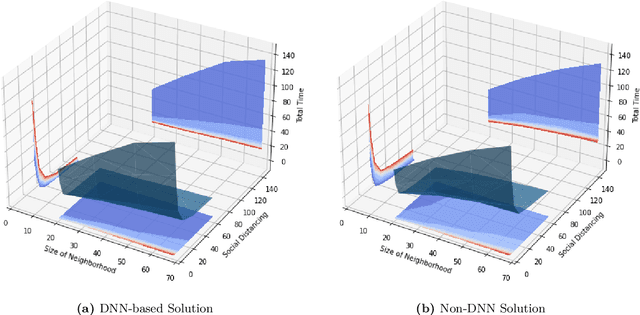

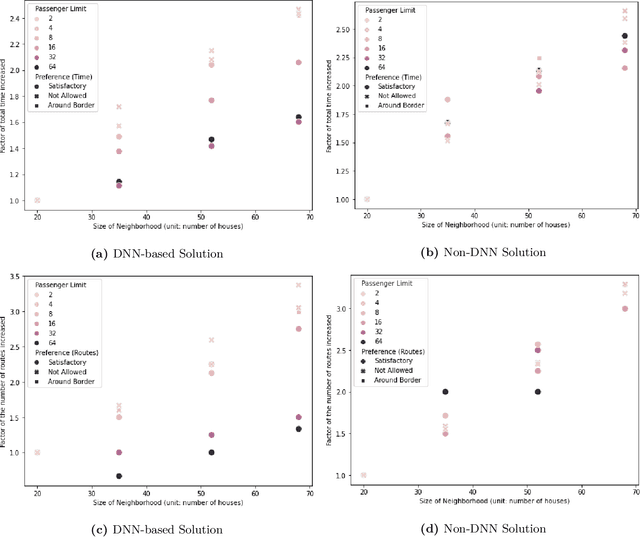
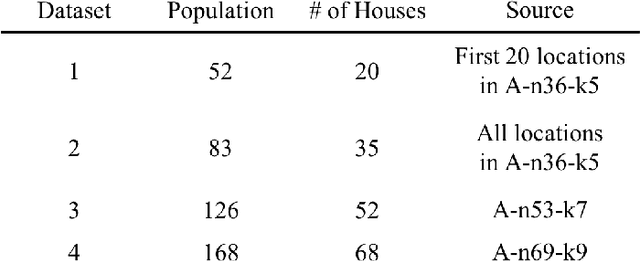
In this study, we explore the implications of integrating social distancing with emergency evacuation when a hurricane approaches a major city during the COVID-19 pandemic. Specifically, we compare DNN (Deep Neural Network)-based and non-DNN methods for generating evacuation strategies that minimize evacuation time while allowing for social distancing in rescue vehicles. A central question is whether a DNN-based method provides sufficient extra efficiency to accommodate social distancing, in a time-constrained evacuation operation. We describe the problem as a Capacitated Vehicle Routing Problem and solve it using one non-DNN solution (Sweep Algorithm) and one DNN-based solution (Deep Reinforcement Learning). DNN-based solution can provide decision-makers with more efficient routing than non-DNN solution. Although DNN-based solution can save considerable time in evacuation routing, it does not come close to compensating for the extra time required for social distancing and its advantage disappears as the vehicle capacity approaches the number of people per household.
Application of deep learning to large scale riverine flow velocity estimation
Dec 04, 2020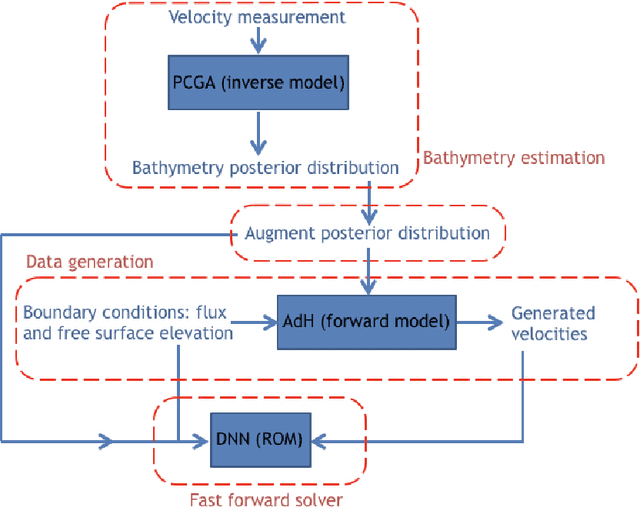
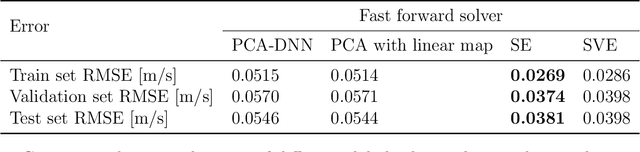
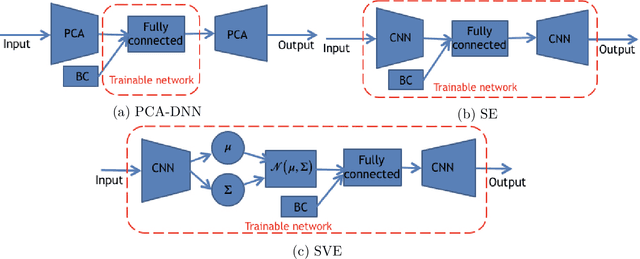
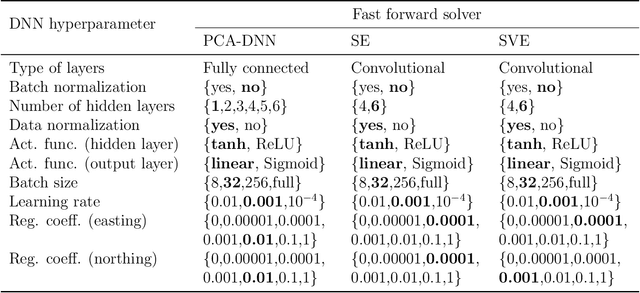
Fast and reliable prediction of riverine flow velocities is important in many applications, including flood risk management. The shallow water equations (SWEs) are commonly used for prediction of the flow velocities. However, accurate and fast prediction with standard SWE solvers is challenging in many cases. Traditional approaches are computationally expensive and require high-resolution riverbed profile measurement ( bathymetry) for accurate predictions. As a result, they are a poor fit in situations where they need to be evaluated repetitively due, for example, to varying boundary condition (BC), or when the bathymetry is not known with certainty. In this work, we propose a two-stage process that tackles these issues. First, using the principal component geostatistical approach (PCGA) we estimate the probability density function of the bathymetry from flow velocity measurements, and then we use multiple machine learning algorithms to obtain a fast solver of the SWEs, given augmented realizations from the posterior bathymetry distribution and the prescribed range of BCs. The first step allows us to predict flow velocities without direct measurement of the bathymetry. Furthermore, the augmentation of the distribution in the second stage allows incorporation of the additional bathymetry information into the flow velocity prediction for improved accuracy and generalization, even if the bathymetry changes over time. Here, we use three solvers, referred to as PCA-DNN (principal component analysis-deep neural network), SE (supervised encoder), and SVE (supervised variational encoder), and validate them on a reach of the Savannah river near Augusta, GA. Our results show that the fast solvers are capable of predicting flow velocities with good accuracy, at a computational cost that is significantly lower than the cost of solving the full boundary value problem with traditional methods.