 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognition and 3D Localization of Pedestrian Actions from Monocular Video
Aug 03, 2020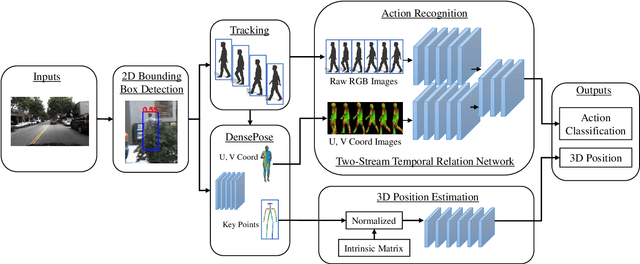

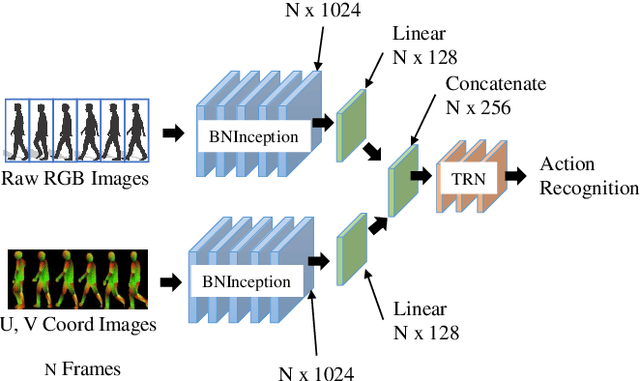
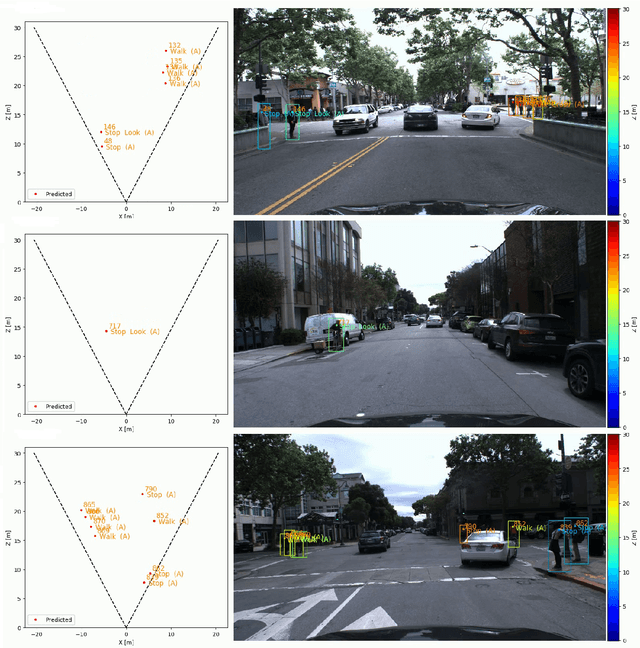
Understanding and predicting pedestrian behavior is an important and challenging area of research for realizing safe and effective navigation strategies in automated and advanced driver assistance technologies in urban scenes. This paper focuses on monocular pedestrian action recognition and 3D localization from an egocentric view for the purpose of predicting intention and forecasting future trajectory. A challenge in addressing this problem in urban traffic scenes is attributed to the unpredictable behavior of pedestrians, whereby actions and intentions are constantly in flux and depend on the pedestrians pose, their 3D spatial relations, and their interaction with other agents as well as with the environment. To partially address these challenges, we consider the importance of pose toward recognition and 3D localization of pedestrian actions. In particular, we propose an action recognition framework using a two-stream temporal relation network with inputs corresponding to the raw RGB image sequence of the tracked pedestrian as well as the pedestrian pose. The proposed method outperforms methods using a single-stream temporal relation network based on evaluations using the JAAD public dataset. The estimated pose and associated body key-points are also used as input to a network that estimates the 3D location of the pedestrian using a unique loss function. The evaluation of our 3D localization method on the KITTI dataset indicates the improvement of the average localization error as compared to existing state-of-the-art methods. Finally, we conduct qualitative tests of action recognition and 3D localization on HRI's H3D driving dataset.
Ego-motion and Surrounding Vehicle State Estimation Using a Monocular Camera
May 06, 2020



Understanding ego-motion and surrounding vehicle state is essential to enable automated driving and advanced driving assistance technologies. Typical approaches to solve this problem use fusion of multiple sensors such as LiDAR, camera, and radar to recognize surrounding vehicle state, including position, velocity, and orientation. Such sensing modalities are overly complex and costly for production of personal use vehicles. In this paper, we propose a novel machine learning method to estimate ego-motion and surrounding vehicle state using a single monocular camera. Our approach is based on a combination of three deep neural networks to estimate the 3D vehicle bounding box, depth, and optical flow from a sequence of images. The main contribution of this paper is a new framework and algorithm that integrates these three networks in order to estimate the ego-motion and surrounding vehicle state. To realize more accurate 3D position estimation, we address ground plane correction in real-time. The efficacy of the proposed method is demonstrated through experimental evaluations that compare our results to ground truth data available from other sensors including Can-Bus and LiDAR.