 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly supervised learning of indoor geometry by dual warping
Paper and Code
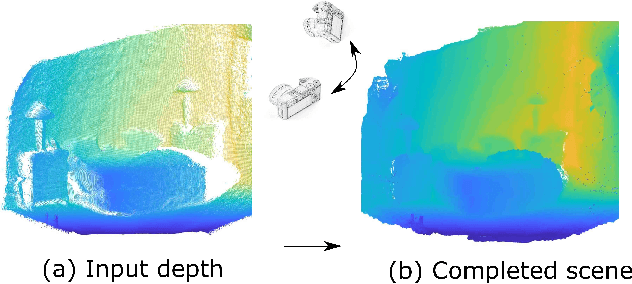
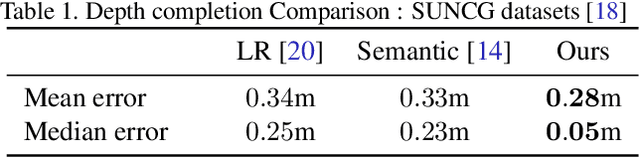
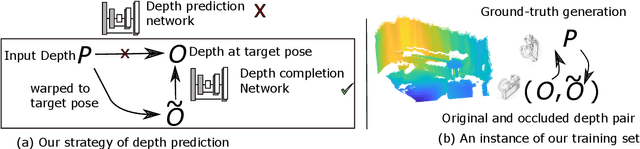
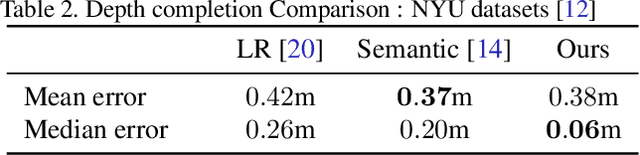
A major element of depth perception and 3D understanding is the ability to predict the 3D layout of a scene and its contained objects for a novel pose. Indoor environments are particularly suitable for novel view prediction, since the set of objects in such environments is relatively restricted. In this work we address the task of 3D prediction especially for indoor scenes by leveraging only weak supervision. In the literature 3D scene prediction is usually solved via a 3D voxel grid. However, such methods are limited to estimating rather coarse 3D voxel grids, since predicting entire voxel spaces has large computational costs. Hence, our method operates in image-space rather than in voxel space, and the task of 3D estimation essentially becomes a depth image completion problem. We propose a novel approach to easily generate training data containing depth maps with realistic occlusions, and subsequently train a network for completing those occluded regions. Using multiple publicly available dataset~\cite{song2017semantic,Silberman:ECCV12} we benchmark our method against existing approaches and are able to obtain superior performance. We further demonstrate the flexibility of our method by presenting results for new view synthesis of RGB-D images.