 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast-SCNN: Fast Semantic Segmentation Network
Feb 12, 2019
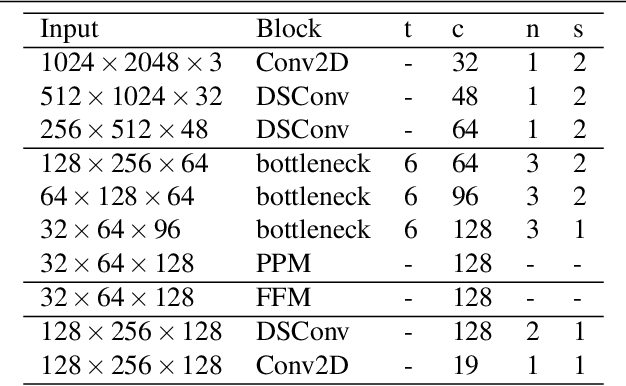


The encoder-decoder framework is state-of-the-art for offline semantic image segmentation. Since the rise in autonomous systems, real-time computation is increasingly desirable. In this paper, we introduce fast segmentation convolutional neural network (Fast-SCNN), an above real-time semantic segmentation model on high resolution image data (1024x2048px) suited to efficient computation on embedded devices with low memory. Building on existing two-branch methods for fast segmentation, we introduce our `learning to downsample' module which computes low-level features for multiple resolution branches simultaneously. Our network combines spatial detail at high resolution with deep features extracted at lower resolution, yielding an accuracy of 68.0% mean intersection over union at 123.5 frames per second on Cityscapes. We also show that large scale pre-training is unnecessary. We thoroughly validate our metric in experiments with ImageNet pre-training and the coarse labeled data of Cityscapes. Finally, we show even faster computation with competitive results on subsampled inputs, without any network modifications.
ContextNet: Exploring Context and Detail for Semantic Segmentation in Real-time
Nov 05, 2018



Modern deep learning architectures produce highly accurate results on many challenging semantic segmentation datasets. State-of-the-art methods are, however, not directly transferable to real-time applications or embedded devices, since naive adaptation of such systems to reduce computational cost (speed, memory and energy) causes a significant drop in accuracy. We propose ContextNet, a new deep neural network architecture which builds on factorized convolution, network compression and pyramid representation to produce competitive semantic segmentation in real-time with low memory requirement. ContextNet combines a deep network branch at low resolution that captures global context information efficiently with a shallow branch that focuses on high-resolution segmentation details. We analyse our network in a thorough ablation study and present results on the Cityscapes dataset, achieving 66.1% accuracy at 18.3 frames per second at full (1024x2048) resolution (41.9 fps with pipelined computations for streamed data).
Recurrent Fully Convolutional Neural Networks for Multi-slice MRI Cardiac Segmentation
Aug 13, 2016



In cardiac magnetic resonance imaging, fully-automatic segmentation of the heart enables precise structural and functional measurements to be taken, e.g. from short-axis MR images of the left-ventricle. In this work we propose a recurrent fully-convolutional network (RFCN) that learns image representations from the full stack of 2D slices and has the ability to leverage inter-slice spatial dependences through internal memory units. RFCN combines anatomical detection and segmentation into a single architecture that is trained end-to-end thus significantly reducing computational time, simplifying the segmentation pipeline, and potentially enabling real-time applications. We report on an investigation of RFCN using two datasets, including the publicly available MICCAI 2009 Challenge dataset. Comparisons have been carried out between fully convolutional networks and deep restricted Boltzmann machines, including a recurrent version that leverages inter-slice spatial correlation. Our studies suggest that RFCN produces state-of-the-art results and can substantially improve the delineation of contours near the apex of the heart.