 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Generative Adversarial Network Training via Self-Labeling and Self-Attention
Jun 18, 2021



We propose a novel GAN training scheme that can handle any level of labeling in a unified manner. Our scheme introduces a form of artificial labeling that can incorporate manually defined labels, when available, and induce an alignment between them. To define the artificial labels, we exploit the assumption that neural network generators can be trained more easily to map nearby latent vectors to data with semantic similarities, than across separate categories. We use generated data samples and their corresponding artificial conditioning labels to train a classifier. The classifier is then used to self-label real data. To boost the accuracy of the self-labeling, we also use the exponential moving average of the classifier. However, because the classifier might still make mistakes, especially at the beginning of the training, we also refine the labels through self-attention, by using the labeling of real data samples only when the classifier outputs a high classification probability score. We evaluate our approach on CIFAR-10, STL-10 and SVHN, and show that both self-labeling and self-attention consistently improve the quality of generated data. More surprisingly, we find that the proposed scheme can even outperform class-conditional GANs.
Training Constrained Deconvolutional Networks for Road Scene Semantic Segmentation
Apr 06, 2016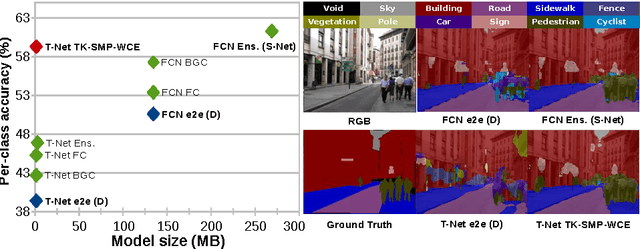
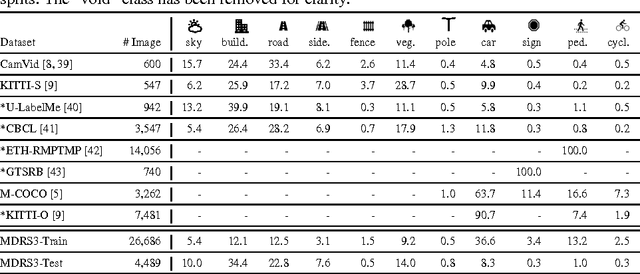

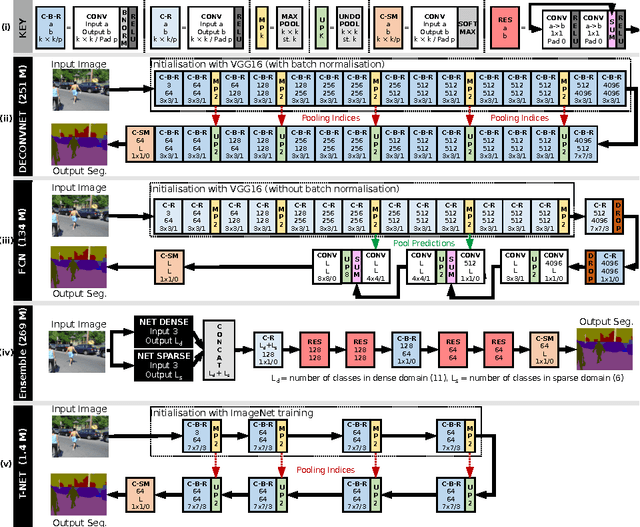
In this work we investigate the problem of road scene semantic segmentation using Deconvolutional Networks (DNs). Several constraints limit the practical performance of DNs in this context: firstly, the paucity of existing pixel-wise labelled training data, and secondly, the memory constraints of embedded hardware, which rule out the practical use of state-of-the-art DN architectures such as fully convolutional networks (FCN). To address the first constraint, we introduce a Multi-Domain Road Scene Semantic Segmentation (MDRS3) dataset, aggregating data from six existing densely and sparsely labelled datasets for training our models, and two existing, separate datasets for testing their generalisation performance. We show that, while MDRS3 offers a greater volume and variety of data, end-to-end training of a memory efficient DN does not yield satisfactory performance. We propose a new training strategy to overcome this, based on (i) the creation of a best-possible source network (S-Net) from the aggregated data, ignoring time and memory constraints; and (ii) the transfer of knowledge from S-Net to the memory-efficient target network (T-Net). We evaluate different techniques for S-Net creation and T-Net transferral, and demonstrate that training a constrained deconvolutional network in this manner can unlock better performance than existing training approaches. Specifically, we show that a target network can be trained to achieve improved accuracy versus an FCN despite using less than 1\% of the memory. We believe that our approach can be useful beyond automotive scenarios where labelled data is similarly scarce or fragmented and where practical constraints exist on the desired model size. We make available our network models and aggregated multi-domain dataset for reproducibility.